
互联网行业“查成分”,或解AI污染难题
2025-09-16









在生成式AI泛滥的当下,区分AI生成内容和人类产出内容愈发困难。为解决AI内容对互联网的“荼毒”,各方都在想办法。日前,互联网工程任务组(IETF)发布《AI内容披露标头》(AI Content Disclosure Header)草案,打算在网页HTTP响应中新增可机读的AI内容标记。
IETF此举针对的是AI领域的突出问题,即不同AI产品循环引用虚假内容,导致“弄假成真”,扰乱互联网内容生态。AI会因幻觉(AI Hallucinations)而胡说八道,因为AI大模型本质是“概率预测机”,靠海量训练学习词语关联规律,回忆“生僻内容”时会有困难。
目前,AI幻觉无法完全避免,这是让AI更智能、更像人的代价。所以,解决AI生成内容中虚假部分的危害成了业界课题。AI虚假内容本身不可怕,真正挑战是不同AI产品互相引用虚假内容,形成造假闭环。
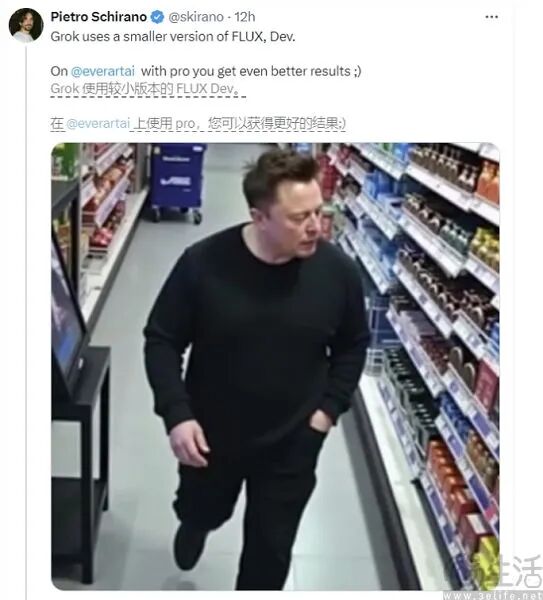
ChatGPT能在“DeepSeek被伪造道歉”事件中成为事实核查工具,是因为它与DeepSeek使用不同训练数据,未被虚假内容污染,所以输出了事实。但如果OpenAI的爬虫GPTBot抓取到“DeepSeek向明星道歉”内容,结果就不同了。
AI互相引用虚假内容,用户就会遭殃,假的也会成真。IETF工作的核心是避免AI生成的虚假、垃圾内容“回流”到互联网,形成“垃圾进、垃圾出”的负向循环。
相比技术难度高的AI水印,让网站主动披露内容是否由AI生成更具可操作性。而IETF能约束网站,因为它是负责互联网标准制定与推广的行业组织,HTTP、 IPv6都是其成果,如今的互联网建立在IETF工作基础上。
本文来自微信公众号“三易生活”(ID:IT - 3eLife),作者:三易菌,36氪经授权发布。

IETF此举针对的是AI领域的突出问题,即不同AI产品循环引用虚假内容,导致“弄假成真”,扰乱互联网内容生态。AI会因幻觉(AI Hallucinations)而胡说八道,因为AI大模型本质是“概率预测机”,靠海量训练学习词语关联规律,回忆“生僻内容”时会有困难。

目前,AI幻觉无法完全避免,这是让AI更智能、更像人的代价。所以,解决AI生成内容中虚假部分的危害成了业界课题。AI虚假内容本身不可怕,真正挑战是不同AI产品互相引用虚假内容,形成造假闭环。
ChatGPT能在“DeepSeek被伪造道歉”事件中成为事实核查工具,是因为它与DeepSeek使用不同训练数据,未被虚假内容污染,所以输出了事实。但如果OpenAI的爬虫GPTBot抓取到“DeepSeek向明星道歉”内容,结果就不同了。
AI互相引用虚假内容,用户就会遭殃,假的也会成真。IETF工作的核心是避免AI生成的虚假、垃圾内容“回流”到互联网,形成“垃圾进、垃圾出”的负向循环。

相比技术难度高的AI水印,让网站主动披露内容是否由AI生成更具可操作性。而IETF能约束网站,因为它是负责互联网标准制定与推广的行业组织,HTTP、 IPv6都是其成果,如今的互联网建立在IETF工作基础上。
本文来自微信公众号“三易生活”(ID:IT - 3eLife),作者:三易菌,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com