
揭秘GPT-5减少“胡说”之谜:OpenAI新论文解读






OpenAI出手,找到了减少模型幻觉的诀窍。GPT - 5发布后,虽性能未实现业界期待的“飞跃”,但最亮眼的是幻觉率大幅下降。
OpenAI数据显示,GPT - 5出现事实错误的概率比GPT - 4o低约45%,比OpenAI o3低约80%。
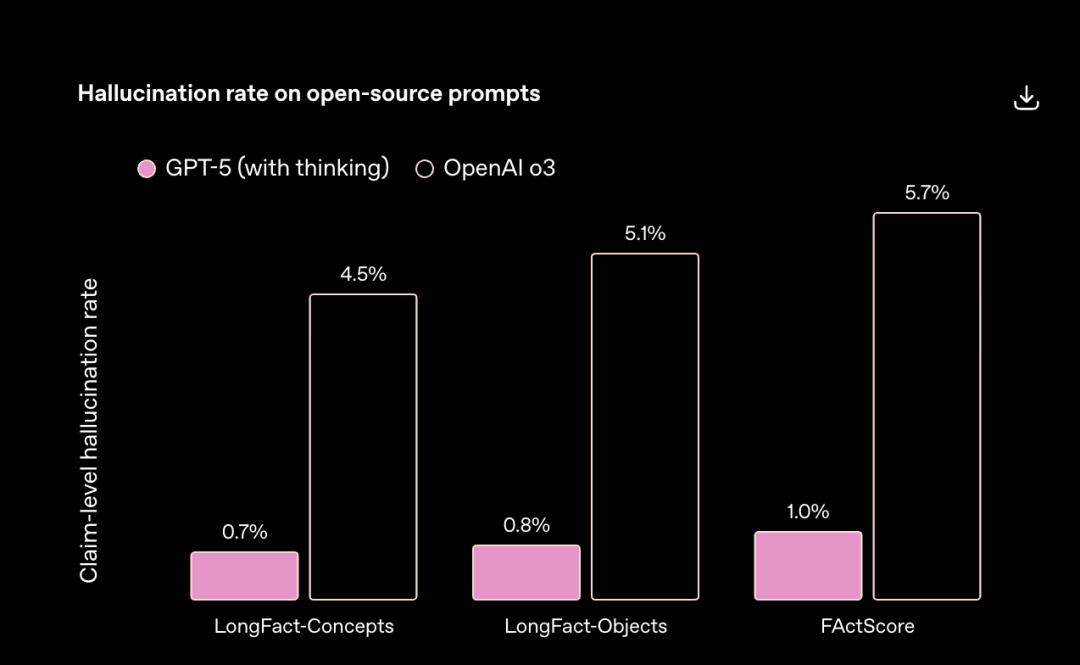
不过,这一提升背后的原因一直未公开。在System Card里,OpenAI将其归功于强化学习训练,称利用了新方法让模型学会“完善思考过程、尝试不同策略并认识错误”,但具体方法成谜。
9月4日,OpenAI发布论文《语言模型为何会产生幻觉》(Why Language Models Hallucinate)。虽未完全公开技术细节,但结合论文和已发布文档,能窥见其核心思路。

01 预训练阶段幻觉产生不可避免
幻觉不可避免并非新结论,但过往研究多围绕训练数据问题,很少从语言模型机制探讨。
OpenAI新论文证明:“幻觉”是大语言模型(LLM)统计学习本质下必然产生、可预测的副产品。
其论证逻辑为:生成可靠信息比判断是否可靠更难,而判断是否可靠必然有失败之处。
首先,论文利用语言模型自回归预测本质,定义其内在“判断力”。模型评估句子时,逐词预测并连乘条件概率得出总概率值,反映句子与模型统计规律的符合程度。基于此,研究人员提出“是否有效”(Is - It - Valid, IIV)判断器:句子内部概率高于阈值为“有效”,反之“无效”。
简单说,模型生成的话“看着熟、顺”就“有效”,反之无效。
然而,该“判断器”并非永远可靠。处理“面生但似曾相识”的灰色信息时会出错,论文列举多种导致判断失效的场景,如数据稀疏、模型能力不足、计算复杂、数据分布偏移和训练数据含错误等。

对于“判断错误”后果,论文给出数学结论:(生成模型的错误率)≥ 2 ×(IIV判断器的错误率)。这种放大效应源于判断错误会衍生多种幻觉,如1 + 1判断为3,会产生1 + 1 = 3和1 + 1不等于2两种幻觉。
结论很清晰:训练数据存在长尾、稀疏和噪声部分,模型判断必然失败,判断错误会传导至生成任务,导致幻觉不可避免。
人类也会有不确定的事,但有“知之为知之,不知为不知”的态度。模型对齐过程应教其“不知为不知”,如提高“有效性判别器”阈值或突出更可能的答案。但OpenAI论文后半部分证明,当下评价体系下,后训练无法做好这方面工作。
02 后训练未能有效抑制幻觉
后训练并非完全无效,OpenAI提出校准概念。预训练模型中,词的概率分布依训练材料产生,为使损失函数最小化,模型会自然校准。
但这会产生平原效应,模型很多选项自信度高,易越过IIV判断器阈值,产生幻觉。
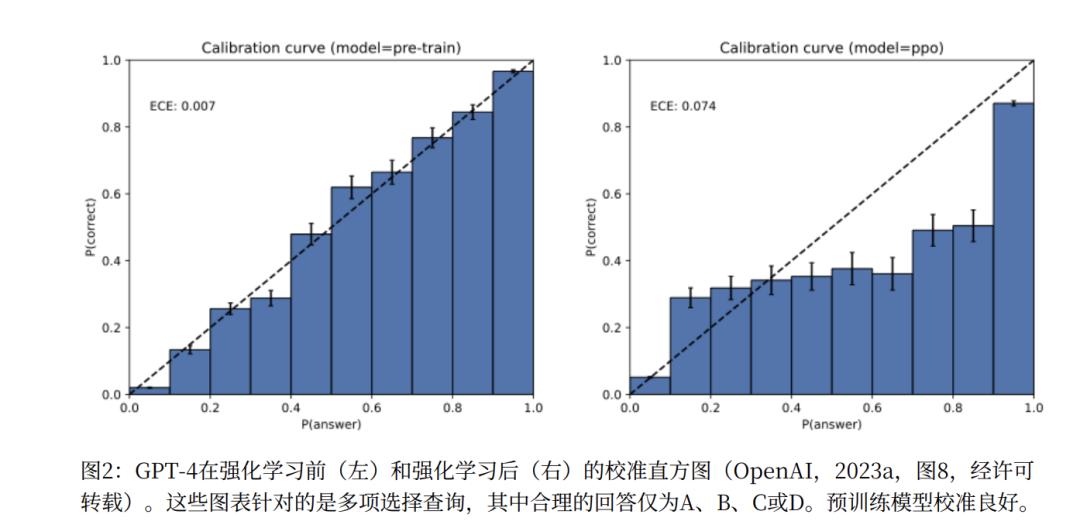
后训练通过明确偏好反馈改变平坦的概率分布,使模型将大部分概率集中到“最佳”答案,形成陡峭山峰,其他选项概率被极大压制。当“山峰”是正确答案时,模型可克服因不确定性导致的幻觉,降低幻觉率。
然而,这种“非校准”是双刃剑。它减少“因不确定而猜测”的幻觉时,也增加了“过度自信”的风险。后训练重点是减少过度自信,让模型能说“我不知道”。
目前主流评估基准如GPQA3、MMLU - Pro和SWE - bench等采用“二元评分制”,答案只分“正确”(1分)或“错误”(0分)。

这种评分机制惩罚不确定性,模型面对没把握的问题,诚实回答“我不知道”和给出错误“最佳猜测”得分相同。在当下模型训练中,让模型诚实回答吃力不讨好。
所以,后训练在技术底层可消除模型幻觉,但实践中未被正确引导。当前行业评估标准奖励产生幻觉的行为,只要“惩罚诚实、奖励猜测”的评估范式不变,幻觉问题将阻碍AI系统提高可靠性。
03 GPT - 5可能的幻觉杀手锏与DeepSeek R1的短板
虽文章未深入后训练细节,只批判了对错二元的benchmark,但将其应用到强化学习(RL)领域,结论仍合理。
推论是:若RL过程采用二元奖励路径,极可能降低模型抑制幻觉的能力。
强化学习通过“奖励模型”指导语言模型行为,模型生成回答,奖励模型打分,模型据此调整策略以获更高分数。
若奖励模型采用极端二元评分(如“好答案”+1/“坏答案”-1),会出现问题:事实性错误答案和诚实但无帮助的答案都得 - 1分。这复现了论文中Benchmark的缺陷,二元奖励路径的RL流程会鼓励模型“虚张声势”,惩罚不确定性表达。
目前主流奖励模型有两种。一种是ORM(结果奖励模型),以使用ORM的DeepSeekR1为例,其奖励模型由最终答案是否正确和格式是否正确两个路径构成,是极端二元路径,只要最终答案正确就给高分。
这种强化二元性路径的后训练,可能减少“犹豫型”幻觉,但会增加“顽固型”或“过度自信型”幻觉,推高整体幻觉率。这或许是DeepSeekR1问世后面临幻觉挑战的原因,在Vectara HHEM幻觉测试中,其幻觉率高达3.9%,远高于预训练模型DeepSeekV3。
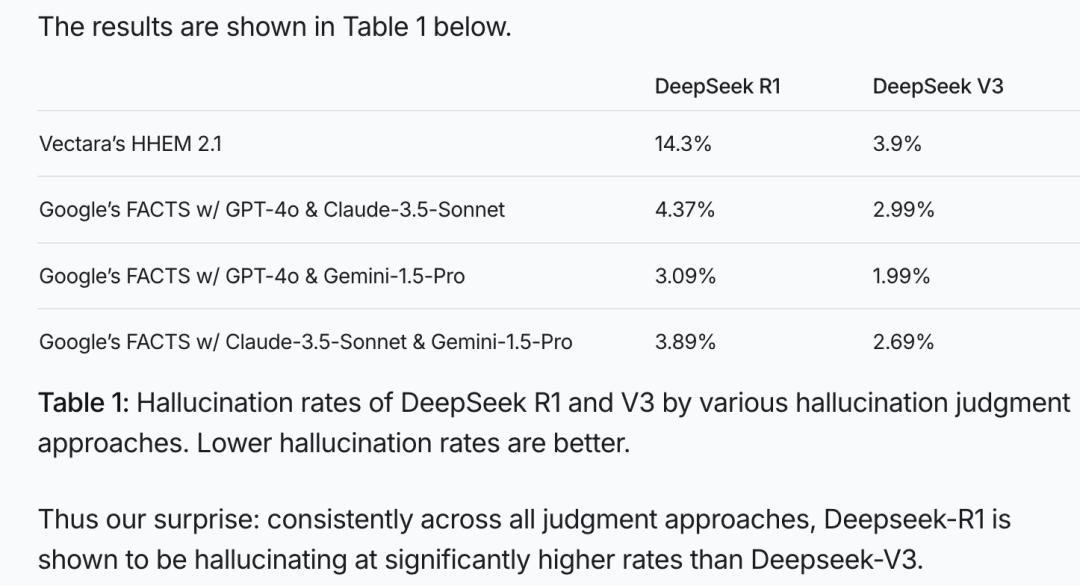
而使用PRM(过程奖励模型)的同期OpenAI o3,幻觉率仅有6.8%,不到DeepSeek R1的一半。PRM会审查模型推理“思路”,发现基于捏造事实的推理步骤就给予负反馈,迫使模型忠于事实推理。
据The Information爆料,GPT - 5极可能引入Universal Verifier技术,超越可验证的对错二元评价标准,如采用Rubric(评分细则)方法,让“验证模型”依据复杂、非二元标准打分,从根本上瓦解二元激励对强化学习的负面影响,这可能是GPT - 5低幻觉率的诀窍。
论文最后,研究者提议后训练阶段引入带惩罚的评分机制,明确告知模型过度自信代价大(如答对得1分,答错得 - 1,过度自信答错扣9分,不答得0分),迫使模型从“得分优化器”变为“风险评估器”,精确校准置信度,确信度足够高才回答。
也许只有让模型不只是专注于得分,而是专注于真实,幻觉问题才可能解决。
本文来自微信公众号“腾讯科技”,作者:博阳,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com