
雄安引才:清华团队开源首个结构化数据通用大模型,助力工业智能化






作为雄安新区重点打造的人工智能产业创新载体,雄安人工智能产业园聚焦人工智能核心技术领域,构建集技术研发、产业孵化、企业培育于一体的创新生态体系,正加速汇聚像稳准智能这样一批前沿科技企业,形成产业创新集群,为区域高质量发展注入强劲动能。

2025年8月29日,清华大学计算机系崔鹏教授团队联合稳准智能共同研发的结构化数据通用大模型 “极数” (LimiX)正式开源。这标志着我国在结构化数据智能处理领域取得技术突破,生态开放迈出关键一步,将降低各行业应用结构化数据AI技术的门槛。在结构化数据占主导的泛工业领域,“极数”大模型能助力AI融入工业生产全流程,解决工业数据价值挖掘难题,为智能制造和新型工业化提供支撑,推动产业升级。
在泛工业领域,结构化数据是核心资产,如工业生产参数等都以结构化数据呈现,其智能处理能力影响产业效率和科研突破,也是AI赋能工业制造的关键。通用大语言模型(LLM)在文本处理方面表现出色,但处理表格、时序等结构化数据时存在短板,难以完成复杂任务,准确率无法满足行业需求。目前工业结构化数据处理依赖私有数据和专用模型,专用模型难以泛化,成本高、效果差,制约了AI在工业场景的应用。
结构化数据通用大模型(LDM)能解决这一问题。它融合结构因果推断与预训练大模型技术,可捕捉结构化数据关联,具备强泛化能力,能跨行业适配多类任务。“极数”大模型支持10类任务,在多个场景中性能超越最优专用模型,实现单一模型适配多场景、多任务,为人工智能赋能工业提供了通用解决方案。
“极数”大模型在技术性能和产业落地方面优势明显。在600多个数据集的测试中,无需二次训练,在准确率、泛化性等指标上达到或超过专有SOTA模型。在产业应用上,已成功落地多个工业场景,具有无需训练、部署成本低、准确率高、通用性强的特点,获得合作企业认可,成为推动工业数据价值转化的实用技术方案,正构建面向泛工业垂直行业核心业务场景的智能底座。
1、研发团队
“极数”模型由清华大学计算机系崔鹏教授牵头研发,团队兼具学术研究和产业落地优势,背后有深厚科研积淀和前瞻性布局。
崔鹏教授是我国数据智能领域顶尖学者,获国家杰出青年科学基金,两次获国家自然科学二等奖,获评国际计算机协会(ACM)杰出科学家,学术影响力获国际认可。他提出 “因果启发的稳定学习” 新范式,为AI模型可靠性和泛化性研究奠定理论基础。
2022年ChatGPT引发大模型浪潮后,崔鹏教授将研究方向拓展至结构化数据通用大模型(LDM)领域。团队攻克核心难题,实现 “极数” 模型性能突破,为开源奠定技术基础。
2、极数大模型简介
“极数”大模型集成多种能力,如分类、回归等,在具备优秀结构化数据建模性能的同时,提高了通用性。
预训练阶段,“极数”大模型基于海量因果合成数据学习因果关系,能捕捉因果变量,学习数据联合分布,适应各种下游任务。推理阶段,可直接基于上下文信息推理,无需训练即可适用于各种场景。
模型技术架构
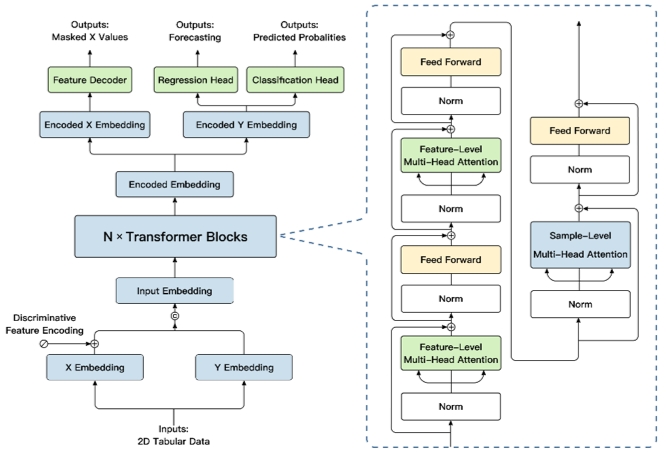
“极数”大模型采用transformer架构并优化。先对特征和目标进行embedding,再在样本和特征维度使用注意力机制,最后将高维特征传入不同模块支持不同功能。
训练数据构建
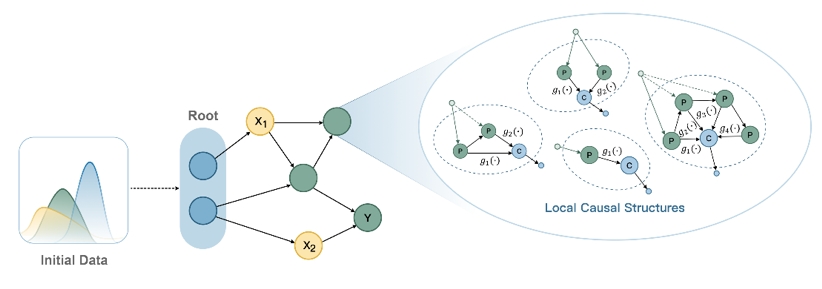
“极数”大模型训练使用生成数据,不依赖真实数据。团队基于结构因果图生成数据,保证了因果结构多样性和数据可控性。
模型优化目标
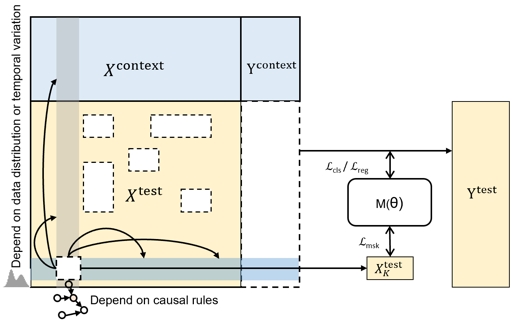
通用结构化数据大模型需具备通用性和无需训练的数据建模能力。“极数”大模型加入掩码重构机制,在三个维度进行掩码操作,考虑特征缺失比例,提高了对各类缺失模式的鲁棒性。
样本维度掩码:对于每一个样本,随机掩码掉其中的某些特征。
特征维度掩码:对于所有样本,随机掩码掉其中的一个特征。
语义维度掩码:关注高维上的相关性,将语义相关度高的特征中的某些特征随机掩码掉。
模型推理
推理时,“极数”大模型无需额外训练,可接收多形态结构化数据,根据任务类型自动完成处理,实现即插即用。还支持模型微调,提升预测性能。
3、模型效果
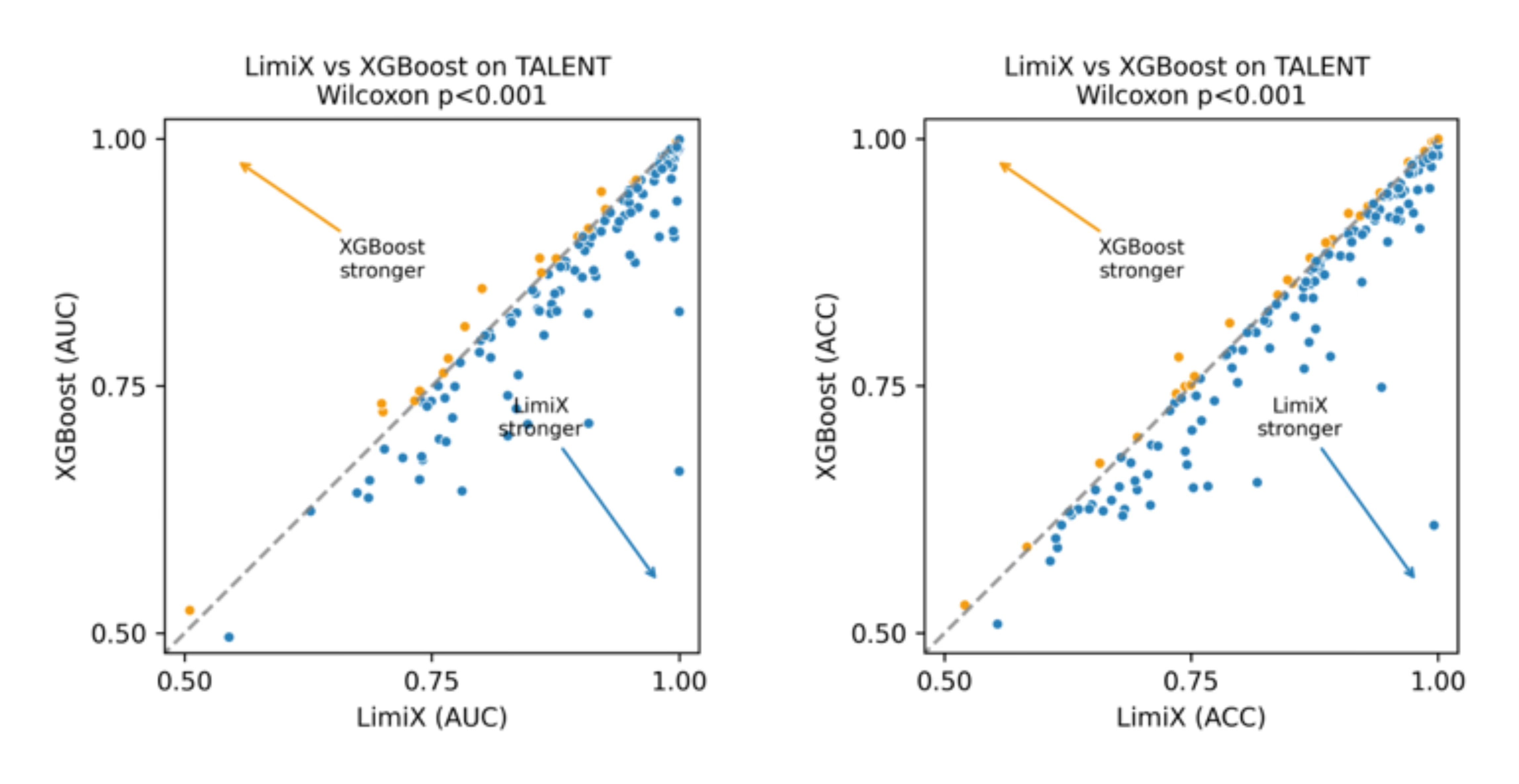
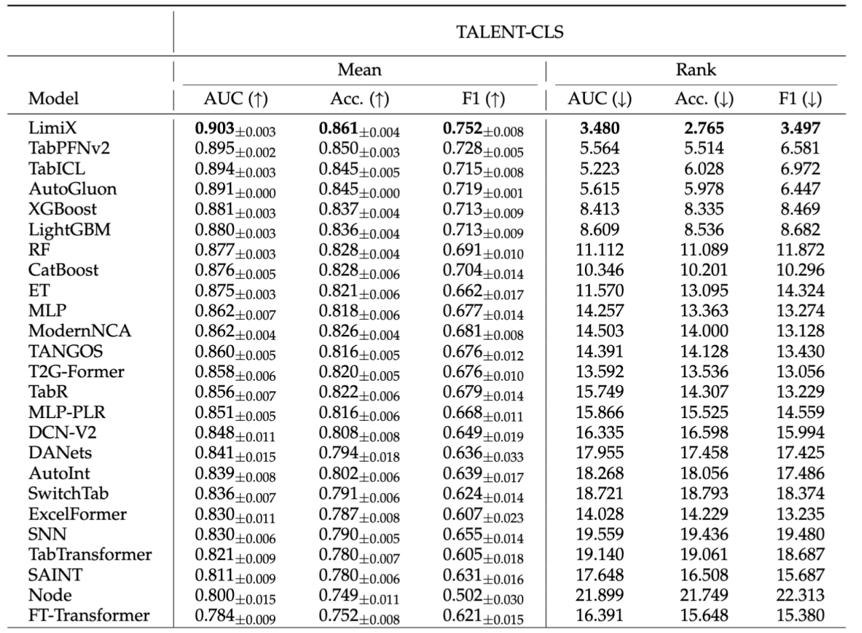
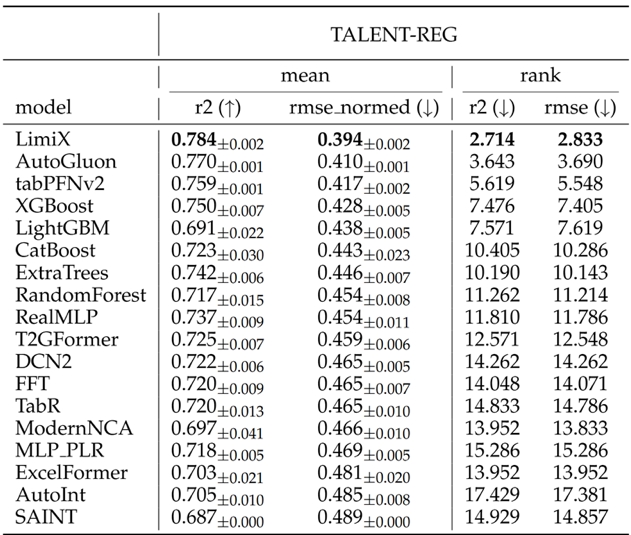
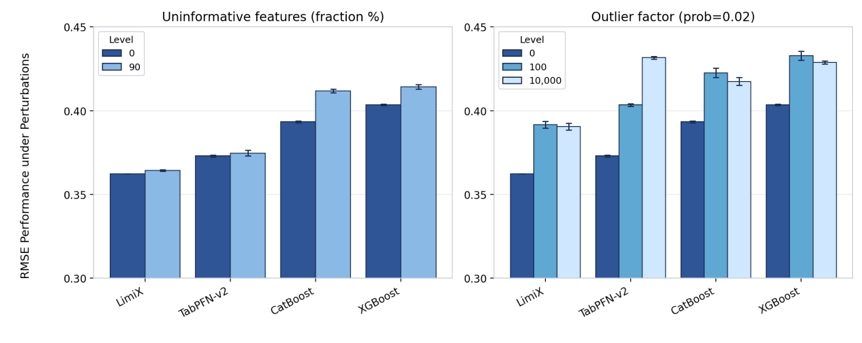
“极数”大模型在多项结构化数据核心任务上表现优异。在分类任务中,超越21个常用baseline方法;回归任务上,在关键指标上达到平均最优,有干扰特征时优势更明显。
4、模型落地应用
“极数”大模型解决了传统专用模型在工业场景的瓶颈,已在多个关键工业场景落地。
在工业运维领域,应用于钢铁等行业,提升设备故障预测准确率,推动维护模式转型。如某钢铁企业,“极数”大模型将故障预测准确率提升15%。
在工艺优化领域,应用于化工等行业,筛选核心优化因子,提升调控效率。如某材料研发企业,“极数”大模型将调控效率提升5倍。
业内专家认为,“极数”大模型验证了通用建模技术在工业场景的适用性,提供了标准化解决方案,有望推动工业智能化升级。
5、开源地址
项目主页:https://limix-ldm.github.io
技术报告:https://github.com/limix-ldm/LimiX/blob/main/LimiX_Technical_Report.pdf
Github:https://github.com/limix-ldm/LimiX
Huggingface:https://huggingface.co/stableai-org
Modelscope:https://modelscope.cn/organization/stable-ai
6、结语
当前人工智能发展中,构建“数据空间的通用世界模型”是AI迈向产业纵深的关键。发展结构化数据通用大模型(LDM)势在必行,我国有望在该领域形成独特竞争力。清华大学团队开源的“极数”大模型是重要突破,期待LDM的“GPT - 3时刻”早日到来。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com