
宇树科技王兴兴言论引关注,对智驾有何参考价值?








宇树科技创始人王兴兴称VLA模型是“相对傻瓜式”的架构,同时认为视频生成模型有前景。这一观点在智能驾驶领域引发了关注和争议。
“VLA模型是相对傻瓜式的架构。”
2025年8月9日,在北京举办的2025世界机器人大会上,宇树科技的创始人、CEO兼CTO王兴兴在演讲中表达了这一观点。尽管他是针对具身智能大模型发表看法,但这也让人对当前智能驾驶最热门的模型方向产生了思考。包括极佳视界的CEO黄冠也吐槽他的观点“太业余”。
王兴兴认为,世界模型可能是更好的技术方向。不过,在短期的未来2 - 5年,“最大的肯定还是一个端到端的具身智能AI模型”。在大会上,他从核心瓶颈、新兴技术引擎及未来技术重心三个方面,对具身智能机器人的发展态势进行了梳理与分析。下面我们来看看他的观点有何启发。
核心瓶颈:模型不够好
很多人认为机器人未大规模应用是因为硬件性能不足或成本过高,但王兴兴指出,当前机器人硬件(包括人形机器人的灵巧手、整机等)已基本够用。从技术层面讲,人形机器人的硬件能满足基本需求,虽工程实施有挑战,但可支撑基础功能实现。
他认为,限制其大规模应用的核心瓶颈是具身智能的AI大模型尚未成熟。

王兴兴觉得目前的机器人大模型(具身智能)发展阶段,类似ChatGPT发布前的1 - 3年,业界明确了方向和技术路线,但未突破关键临界点。他认为没达到临界点,主要是行业对“数据”关注过高,忽视了模型本身的问题。

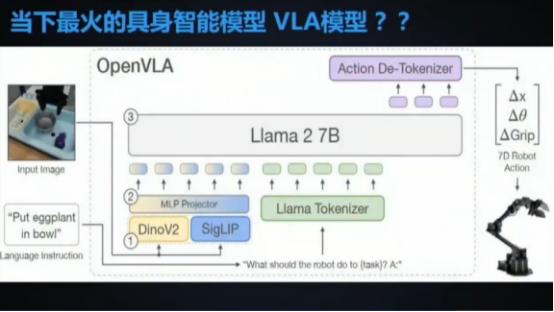
王兴兴指出,具身智能发展的关键问题是模型架构不完善、缺乏统一性和泛用性,导致能力受限,数据也不能充分利用。以VLA模型为例,他认为其是“相对傻瓜式的架构”,在真实世界交互中对数据质量依赖过高,适应性不足,所以他对VLA模型的应用前景持怀疑态度。
此外,“VLA模型 + RL训练”是常见的优化思路,但他认为实践证明这还不够,“模型架构必须进一步升级,不能停留在简单组合层面”。
他还指出,“RL Scaling law(缩放定律)”的缺失也是限制发展的因素,导致机器人学习新任务时要从零开始,训练效率低下。具身智能的理想状态是“新任务训练基于旧有基础,速度越来越快、效果越来越好”,这在语言模型中已得到验证,在机器人运动控制领域虽处于起步阶段,但潜力巨大,值得深入探索。
新技术方向:视频生成模型
既然VLA模型不够优秀,那什么模型才是方向呢?王兴兴认为,现阶段视频生成模型的路线可能比VLA模型更快,收敛概率更大。其核心逻辑是利用视频生成模型预先“模拟生成机器人动作序列的视频”,指导实体机器人执行动作。例如,指令为“整理房间”,模型可先生成虚拟视频,再转化为控制信号。

不过,王兴兴也指出,当前视频生成模型过度关注“视频质量”,导致GPU消耗较高,而机器人只需能驱动动作的视频,这一矛盾有待解决。
未来技术重心:模型、硬件与算力网络
王兴兴预判,未来2 - 5年,具身智能机器人的发展将聚焦三大方向:
一是统一的端到端智能机器人大模型。端到端模型是提升机器人能力的关键,未来要重点推动其研发,实现“基于既有训练基础快速学习新技能”,提升通用性和效率。
二是更低成本、更高寿命的硬件及批量制造。硬件优化很重要,汽车行业发展百年仍有工程难题,对于未来可能大规模应用的人形机器人,必须解决“低成本、高寿命”及“超大批量制造”的工程挑战。
三是低成本、大规模的分布式算力网络。机器人本体受尺寸和电池容量限制,无法部署大规模算力,其峰值功耗通常仅100瓦左右。未来需构建分布式算力网络,如工业场景可在工厂部署局部服务器集群,民用场景可建立区域级算力集群,降低成本,保障延迟和安全性。

会后采访中,媒体提到机器人的价格预期,王兴兴表示,当机器人具备大规模作业能力时,甚至可能免费,因为“每台机器人出厂后都可以缴税”。他举例说,若企业派遣机器人开垦荒芜之地,机器人创造的部分价值将转化为税收。
“这个过程快的话可能要2 - 3年,慢的话可能3 - 5年,但是我觉得这波浪潮(的到来)大概率不会超过10年。”王兴兴说道。
王兴兴的发言引发了争议。当前智能汽车行业,VLA + RL是热门方向,理想汽车、小鹏、华为、文远知行等企业采用了这一路线或近似路线。同时,华为、蔚来,以及理想、小鹏也采用了世界模型,不过表述和功能有区别。具身智能和智能驾驶开发逻辑未必一致,王兴兴的意见只是一家之言,后续技术路线之争还需在实战中见分晓。
本文来自微信公众号“赛博汽车”(ID:Cyber - car),作者:王凌方,编辑:邱锴俊,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com