
英伟达新开源模型:三倍吞吐、单卡运行,推理能力达SOTA





大家都知道,英伟达不仅售卖GPU,还亲自投身于模型的研发。
英伟达新推出的开源模型Llama Nemotron Super v1.5,是专门为复杂推理和智能体任务打造的。
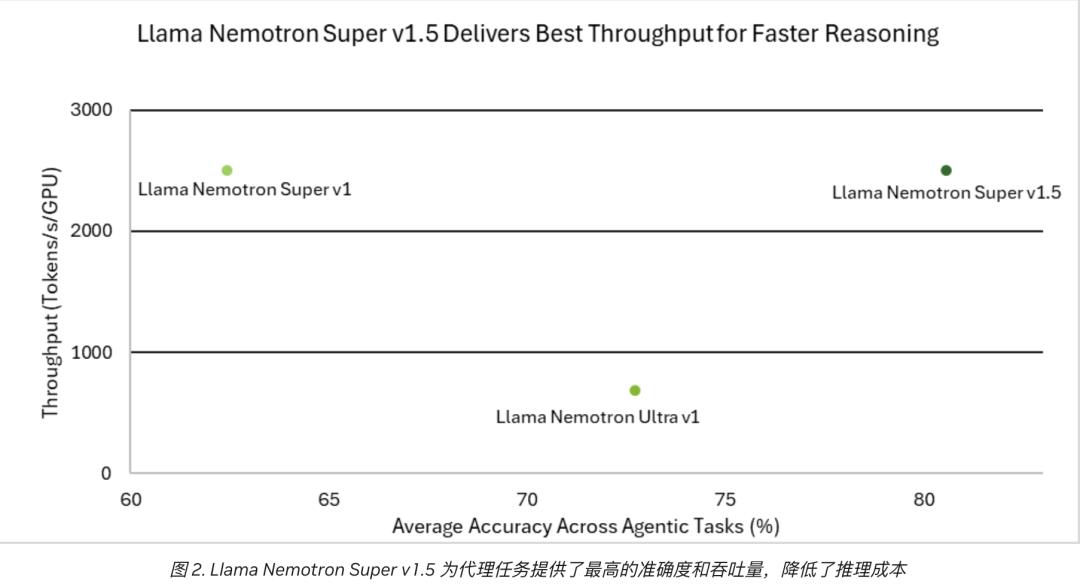
该模型在科学、数学、编程及智能体任务中达到了SOTA水平,同时将吞吐量提升到了前代的3倍,还能在单张显卡上高效运行,真正实现了更准、更快、更轻的目标。
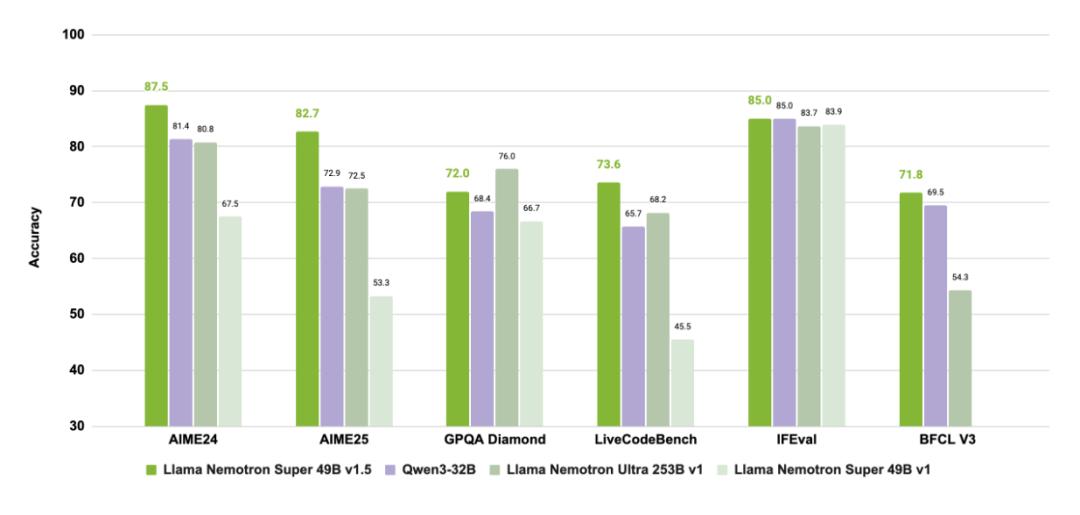
它是如何做到这些的呢?
模型介绍
Llama Nemotron Super v1.5是Llama - 3.3 - Nemotron - Super - 49B - V1.5的简称,它是Llama - 3.3 - Nemotron - Super - 49B - V1的升级版(此模型是Meta的Llama - 3.3 - 70B - Instruct的衍生模型),主要用于复杂推理和智能体任务。
模型架构
Llama Nemotron Super v1.5采用了神经架构搜索(Neural Architecture Search,NAS)技术,这使得模型在准确率和效率之间取得了很好的平衡,同时将吞吐量的提升转化为更低的运行成本。
(注:NAS的目的是通过搜索算法从众多可能的架构中找出最优的神经网络结构,用自动化方法替代人工设计,从而提高模型的性能和效率。)
在Llama Nemotron Super v1.5中,NAS算法生成了非标准、非重复的网络模块(blocks),与传统的Transformer相比,有以下两种变化:
- 跳过注意力机制(Skip attention):在某些模块中,直接跳过注意力层,或者用一个线性层替代。
- 可变前馈网络(Variable FFN):在前馈网络(Feedforward Network)中,不同模块采用了不同的扩展/压缩比。
这样,模型通过跳过注意力机制或改变前馈网络宽度来减少浮点运算次数(FLOPs),从而在资源有限的情况下更高效地运行。
之后,研究团队对原始的Llama模型(Llama 3.3 70B Instruct)进行了逐模块的蒸馏(block - wise distillation),通过为每个模块构建多个变体,并在所有模块结构中搜索组合,构建出一个新模型。
这个新模型既满足了单个H100 80GB显卡的吞吐量和内存要求,又尽可能减少了性能损失。
训练与数据集
该模型首先在FineWeb、Buzz - V1.2和Dolma三个数据集共400亿个token的训练数据上进行了知识蒸馏(knowledge distillation,KD),重点关注英语单轮和多轮聊天。
在后训练阶段,模型结合了监督微调(SFT)和强化学习(RL)的方法,进一步提升了在代码、数学、推理和指令遵循等关键任务上的表现。
这些数据包括公开语料库中的题目和人工合成的问答样本,部分题目配有开启和关闭推理的答案,目的是增强模型对推理模式的辨别能力。
英伟达表示数据集将在未来几周内发布。
总体而言,Llama Nemotron Super V1.5是一个通过NAS自动优化架构、精简计算图的Llama 3.3 70B Instruct变体。它针对单卡运行场景进行了结构简化、知识蒸馏训练与后训练,兼顾了高准确性、高吞吐量和低资源占用,非常适合英语对话类任务及编程任务的部署。
此外,在部署方面,英伟达延续了其生态优势:
我们的AI模型专为在NVIDIA GPU加速系统上运行而设计和/或优化。通过充分利用NVIDIA的硬件(如GPU核心)和软件框架(如CUDA库),相比仅依赖CPU的方案,模型在训练和推理阶段实现了显著的速度提升。
该模型现已开源。开发者可以在build.nvidia.com体验Llama Nemotron Super v1.5,也可以直接从Hugging Face下载模型。
One more thing
作为英伟达新发布的开源大语言模型,Llama Nemotron Super v1.5属于英伟达Nemotron生态。该生态集成了大语言模型、训练与推理框架、优化工具和企业级部署方案,旨在实现高性能、可控性强、易于扩展的生成式AI应用开发。

为了满足不同场景和用户的需求,英伟达在这个生态基础上推出了三个不同定位的大语言模型系列——Nano、Super和Ultra。

其中,Nano系列注重成本效益和边缘部署,适合在边缘设备(如移动端、机器人、IoT设备等)或对成本敏感的场景(如本地运行、离线场景、商业小模型推理)中使用。
Super系列则在单个GPU上实现了精度和计算效率的平衡,它可以在一张高性能GPU(如H100)上运行,无需多卡或大型集群。其精度比Nano系列高,但比Ultra系列小,适合企业开发者或中型部署。我们前面提到的Llama Nemotron Super v1.5就属于这个系列。
Ultra系列致力于在数据中心实现最高精度,专为在数据中心、超算集群、多张GPU上运行而设计,适用于复杂推理、大规模生成、高保真对话等对精度要求极高的任务。
目前,Nemotron已获得SAP、ServiceNow、Microsoft、Accenture、CrowdStrike、Deloitte等企业的支持或集成使用,用于构建面向企业级流程自动化和复杂问题解决的AI智能体平台。
此外,在Amazon Bedrock Marketplace中也能通过NVIDIA NIM微服务调用Nemotron模型,简化了部署流程,支持云端、混合架构等多种运营方案。
参考链接
[1]https://www.marktechpost.com/2025/07/27/nvidia-ai-dev-team-releases-llama-nemotron-super-v1-5-setting-new-standards-in-reasoning-and-agentic-ai/
[2]https://developer.nvidia.com/blog/build-more-accurate-and-efficient-ai-agents-with-the-new-nvidia-llama-nemotron-super-v1-5/
[3]https://huggingface.co/nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
[4]https://www.nvidia.com/en-us/ai-data-science/foundation-models/nemotron/
本文来自微信公众号“量子位”(ID:QbitAI),作者:henry,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com