
继HBM后,英伟达再带火AI内存模组SOCAMM,重塑AI服务器与PC格局







电子发烧友网综合报道,据韩媒消息,下一代低功耗内存模块“SOCAMM”市场已全面开启。AI领域的领军企业英伟达,计划今年为其AI产品部署60至80万个SOCAMM内存模块,这些模块不仅会用于数据中心AI服务器,还有望应用于PC,这一举动将对内存市场及相关产业链产生深远影响。
SOCAMM全称为Small Outline Compression Attached Memory Module,即小型化压缩附加内存模组,是英伟达主导研发的新型内存模块,是适用于数据中心AI服务器的高性能、低功耗内存。
它把低功耗DRAM与压缩连接内存模块(CAMM)搭配使用,以全新外形尺寸实现卓越性能和高能效。基于LPDDR5X芯片,采用694个I/O端口,带宽可达传统DDR5的2.5倍。
物理形态上,SOCAMM尺寸仅14×90毫米,形似U盘,比传统RDIMM体积减少66%,为更紧凑、高效的服务器设计提供了可能。它采用可拆卸的模块化插拔结构,改变了以往LPDDR内存须焊接在主板上的限制,用户能像更换硬盘或SSD一样方便地升级或替换内存,大大提升了系统的灵活性和可维护性。
SOCAMM采用引线键合和铜互连技术,每个模块连接16个DRAM芯片,这种铜基结构增强了散热性能,对AI系统的性能和可靠性至关重要。同时,基于成熟封装工艺,它降低了部署门槛和制造难度,具备更强的成本控制能力和更广泛的适用范围。
得益于LPDDR5X的低电压设计和优化后的封装工艺,SOCAMM使服务器整体运行能耗减少约45%。这种高效能与低功耗的平衡特性,使其不仅适用于集中式的数据中心,也能满足边缘计算场景中对空间和能耗敏感的应用需求。NVIDIA计划将SOCAM率先应用于其AI服务器产品和AI PC(工作站)产品。
在英伟达规划中,GB300 Blackwell平台将率先采用SOCAMM。Blackwell架构GPU有2080亿个晶体管,采用台积电4NP定制工艺制造。所有Blackwell产品均采用双倍光刻极限尺寸的裸片,通过10 TB/s的片间互联技术连接成统一的GPU,在性能、效率和规模上取得了突破性进展。而SOCAMM内存模块的加入,将进一步提升其AI运算表现。
此外,英伟达在今年5月GTC 2025上发布的个人AI超级计算机“DGX Spark”也采用了SOCAMM模块。DGX Spark采用NVIDIA GB10 Grace Blackwell超级芯片,能提供高性能AI功能,支持多达2000亿个参数的模型。随着DGX Spark的推出,预计将推动SOCAMM向PC市场渗透,让更多消费者受益于这一先进内存技术。
SOCAMM与现有的笔记本电脑DRAM模块(LPCAMM)相比,I/O速度更快,数据传输更高效,且结构紧凑,更易更换和扩展。
随着SOCAMM在AI服务器和PC中的应用不断增加,其大规模出货预计将对内存和PCB电路板市场产生积极影响。知情人士透露,“英伟达正与内存和电路板行业分享SOCAMM的部署量(60至80万片),该模块将应用于其AI产品”,目前内存和PCB电路板行业都在积极筹备订单和供货。
从内存市场看,SOCAMM的应用将刺激低功耗DRAM需求,推动内存厂商加大相关技术研发和产能扩充投入。由于SOCAMM需要适配电路板设计,这将促使PCB厂商开发新产品方案,带动行业技术升级。
目前在内存厂商中,美光的SOCAMM已率先获英伟达量产批准,成为英伟达下一代内存供应商。三星和SK海力士的SOCAMM尚未获得英伟达认证,但这两家大厂也在积极与英伟达沟通,希望能供应SOCAMM。
美光SOCAMM是业界首款专为AI资料中心设计的资料中心级模块化低功耗存储器模块。它将美光领先的LPDDR5X与CAMM存储器模块结合,为更高效的AI资料中心奠定了基础。

美光宣称其最新LPDDR5X芯片能效比竞争对手高出20%,这是其赢得英伟达订单的关键因素。考虑到每台AI服务器将搭载四个SOCAMM模块(总计256个DRAM芯片),散热效率尤为重要。
与美光此前生产的服务器DDR模块RDIMM相比,SOCAMM尺寸和功耗减少了三分之一,带宽增加了2.5倍。
通过采用美光LPDDR5X等创新型低功耗(LP)存储器架构,资料中心可大幅提高效能,避免传统DDR5存储器的能源损耗。与DDR5等传统存储器技术不同,LP存储器运行电压较低,通过减少功耗、降低发热量、优化节能电路设计等方式提高功耗和能源效率。
在大规模客户支持环境中执行推理Llama 3 70B,单个GPU管理复杂的AI互动,同时实时处理数千个复杂的客户查询。LP存储器的使用使这一密集型运算更具能源效率。
测试LPDDR5X存储器(在搭载NVLink的NVIDIA GH200 Grace Hopper超级芯片上)与传统DDR5存储器(在搭载PCIe连线Hopper GPU的x86系统上)时,结果显示LP存储器实现了关键的效能提升。使用Meta Llama 3 70B测试推理效能时,LP存储器系统推理吞吐量提高了5倍、延迟减少了近80%、能源消耗降低了73%。
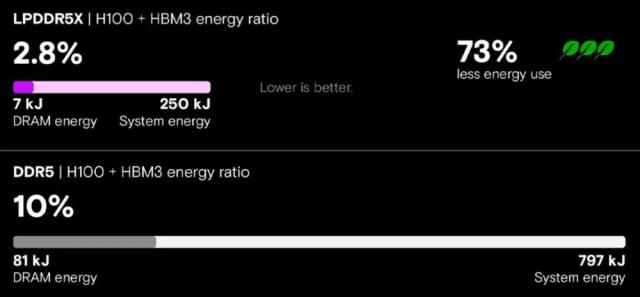
LLM推理的能源效率 来源:美光官网
随着英伟达对SOCAMM内存模块的大规模部署,以及其在AI服务器和PC市场的逐步渗透,将推动整个AI产业链围绕这一新型内存技术进行升级和发展。无论是内存厂商、PCB电路板厂商,还是服务器制造商和终端用户,都将从SOCAMM带来的影响中受益。
更多热点文章阅读
点击关注 星标我们
将我们设为星标,不错过每一次更新!
喜欢就奖励一个“在看”吧!
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com