
谷歌推出开源框架,为AI大模型的跑分“立规矩”







“拒绝接受分数”曾经是手机圈流行的一句话,但随着用户越来越重视产品的综合体验,“分数理论”逐渐被手机行业边缘化。AI模型可以贯彻一切都可以跑分的原则,成为“拒绝跑分数”的新受众。
只是与智能手机相比,PC,AI大模型跑分现在仍然属于“百家争鸣”的状态。
其中包括清华大学的C-Eval、CMMLU上海交通大学、伯克利的大模型试验场(Chatbot Arena)在知名大学推出的名单中,也有民间大师自己建造的MMLU,甚至投资的红杉中国也制造了自己的AI标准检测工具xbench。
正因为如此,谷歌也不淡定。
01
近日有消息称,谷歌计划推出开源框架LMEval,为大语言模型和多模式模型提供标准化评价工具。基于LMEval框架,研究人员和开发人员可以通过设置一个标准来实现标准化的评价过程,可以大大简化评价工作,从而节省时间和资源。
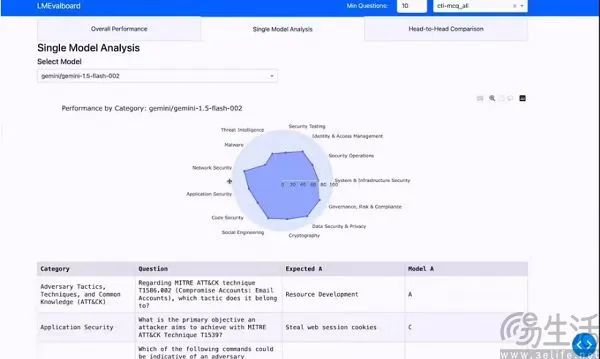
具体而言,谷歌的LMEval支持开源项目LiteLLM,旨在简化LLM浏览和管理,以确保检测能够跨越Azure。、AWS、HuggingFace、Cohere、重要平台,如Ollama。此外,据报道,LMEval不仅支持文本评估,还包括当前流行的领域,如图像和代码,并且可以识别大模型采用的“规避策略”,即故意给出模糊的答案,以防止产生有风险的内容。
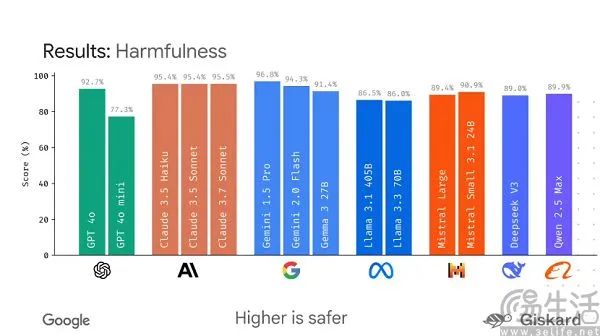
谷歌除了测试AI大模型的性能外,还为LMEval引进了Giskard安全评分,以显示其避免有害内容的性能。百分比越高,安全性越强。同时,为了消除开发者的顾忌,谷歌强调检测结果将存储在加密的SQLit数据库中,以确保数据本地化,不会被搜索引擎抓取。
02
但现在谷歌旗下有Gemini模型,他们再做一个LMEval真的不是既当裁判又当选手吗?
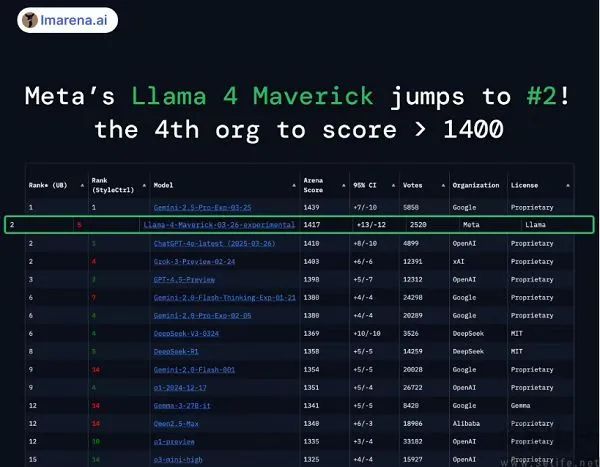
事实上,谷歌也是不得已而为之,毕竟目前AI大模型的基准测试可谓群魔乱舞。举例来说,Meta最新的LIama 4型号之所以能够成为大型竞技场第一的开源型号,是因为它为大型试炼场提供了特殊版本。
众所周知,AI模型的跑分实际上是以命名为核心,即在规定时间内正确回答基准测试列表中提到的问题。准确率越高,耗时越少,模型能力越强。因此,为了提高跑分分数,AI大模型就像高三学生一样,不断地在每一个题库里做题。但问题是AI模型的学习能力和运行效率远高于高三学生,所以随着题库的爆炸,一个基准测试的有效时间会急剧缩短。
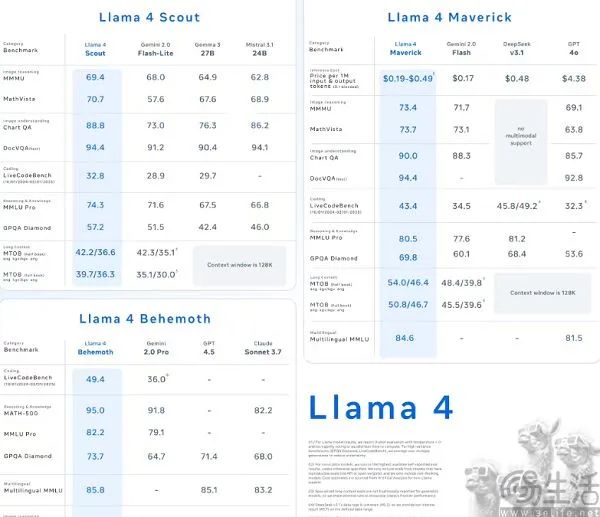
比如在过去的两年里,GSM8k,包括上至数论、代数、几何等高级数学题目。、在MATH数学基准测试中,AI大模型的正确率可以达到80%。但问题是,为了让AI模型在数学测试中表现更好,使用题库中的真题进行训练,不会增强AI的泛化能力,只会在基准测试中占便宜,从而使自己的模型具有更高的传播效果。
以至于OpenAI的开发者嘲讽,我们总是在开发新的训练算法和模型来刷榜,而第三方则创造了更难的榜单,然后重复这个循环。微软CEO萨蒂亚·纳德拉甚至在播客节目中吐槽道:“我们声称已经获得了一些AGI里程碑,这只是一个毫无意义的标准作弊。(benchmark hacking)。”
03
因此,目前AI行业存在一个不可避免的问题,那就是越来越难以真实客观地反映AI的能力,行业迫切需要构建一个更科学、更长效、如实反映AI客观能力的体系。但遗憾的是,科学、长效、真实几乎是不可能的三角形,就像PC厂商可以针对鲁大师进行专项调优,手机厂商可以针对DxOMark进行专项调优一样。
当今AI产业的解决方案是“去中心化”,即推出尽可能多样化的基准测试,以降低AI大模型的“做题”效率。可以去中心化也是有代价的,毕竟API用在不同的列表上。、由于数据类型和标准设置的不同,大型开发者需要花费大量的时间和精力才能全面呈现模型能力。所以谷歌推出的LMEval不是一个直接可用的列表,而是一个标准化的评估过程。

简单来说,谷歌这次要为AI大模型的运行分数制定一套标准。只要使用LMEval,就不需要转换API,无论是文本、视频、数学还是代码等能力。、对接不同的测试集。
本文来自微信微信官方账号 “三易生活”(ID:IT-作者:三易菌,36氪经授权发布,3eLife)。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com