
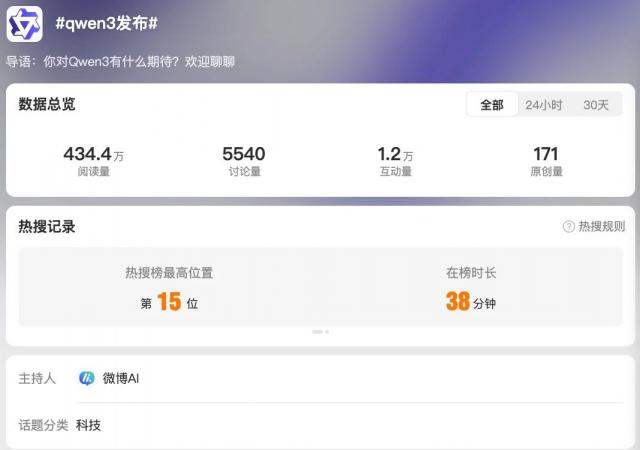
经过这么长时间的“汪峰”,阿里的Qwen3终于喜提热搜了。






The following article is from 差评前沿部 Author 江江
这么多年来一直在工作 AI 汪峰,阿里,世界 Qwen3 这次终于上了热搜。
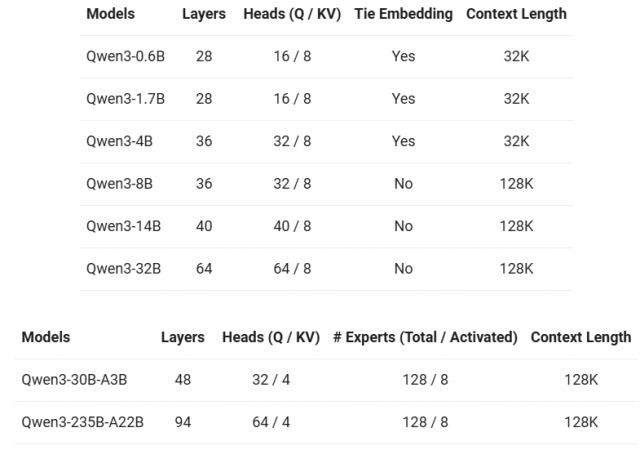
距离 2.5 发布才过去 7 一个月,就在今天早晨,千问又拿出了一个全新的开源全家桶,其中包括六个 Dense( 稠密 )模型和两款 MoE( 混和专家 )模型,可以支持 119 各种语言和方言。
相比 Qwen2.5 最高 72B 参数,千问此次的旗舰模型 A22B-Qwen3-235B- 超级加倍,总参数达到了巨大的水平。 235B。
Qwen33根据官方发布的检测结果 国内外主流大模型在多个测试集中的表现并不多,尤其是代码和数学方面。
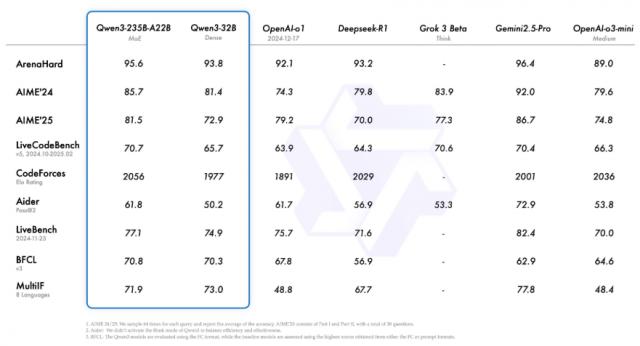
它的具体表现如何,我们还小测了一波旗舰模型。 Qwen3-235B-A22B。

总体而言,使用体验非常好,而且对于深度思考功能的设计也有一些小巧的思考。
以前大家总觉得大模型一旦深入思考就停不下来。想了太久,给出的答案太详细了。但是如果你不深入思考,答案的质量几乎是有趣的。
这次 Qwen3 把方向标交给客户,你可以让他们想到任何水平,大大提高了模型的灵活性。
然而,简单的问题让它简单地思考,问题仍然需要让它更多地思考。在测试中,我们发现不同的探索长度对模型的性能有明显的影响。
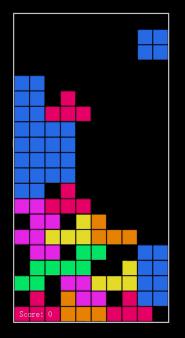
举例来说,为了测试它的代码能力,我们希望 Qwen3 写个游戏。
给出的提示非常简单直接,这样就可以在网页上写一个俄罗斯方块。其他游戏玩法、互动、艺术相关的细节,不是人类应该担心的事情,让千问通过深入思考自己解决。
而且当思维长度设定在那里 1024 token 当时,千问就像一个清澈的大学生,刚刚开始学习代码。给出的程序有少量。 bug,根本不能玩。
但是预算打满之后,它就成了一个熟练的老码农,只需几分钟就能搓出一个完整的俄罗斯方块。
下一步,我们让中文网络上最难的逻辑测试集开始表演:
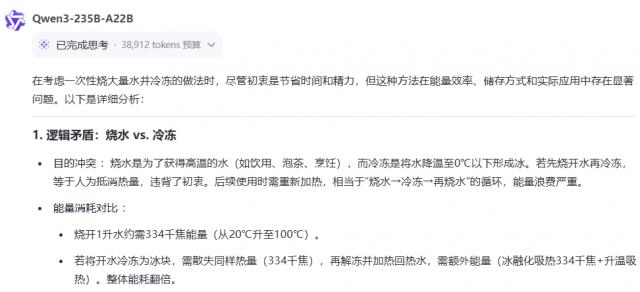
"平时烧水很麻烦,为什么不一次烧很多水然后冷冻起来,等需要的时候再拿出来?"
当深度思考被关闭时,模型也会一本正经地胡说八道:

节省时间、《节能》、真的很方便,讲得这么合理,我相信。
而且一旦开始深入思考,模型一眼就能看出这是一个奇妙的问题,直接向逻辑提出质疑。
前不久,OpenAI 在 o3 在官方文件中,他们发现模型推理时间越长,效果越好。
而 Qwen3 这几个例子可以证明,通过更长时间的深入思考,大模型的智力确实暴涨。

另外,既然代码和逻辑都难以实现,那就再试一次千问在多模态中的表现如何。
前一阵子 GPT-o3 所有的照片推理都让大家伙的背部感到凉爽,这次大升级 Qwen3 还会成为开箱神器吗?
会的兄弟,会的。
一些朋友可能还记得,不久前我们做了一期。 o3 打开盒子,它依靠B&B的招牌定位到梦想小镇。
这次 Qwen3 更加离谱,下图中没有一个字,你知道它是用什么来验证猜测的吗?

是的,是照片左侧的爱情雕塑。恐怕每个人都看不到。我特意用红框圈了一下,没注意的朋友可以再仔细看看。

这次不能说别人靠照片内置信息作弊,千问开盒就像马斯克的智驾一样,纯视觉。
除上述传统艺术能力外,Qwen3 还追上了 MCP 热潮。虽然目前还没有开放测试,但是官方已经展示了两个案例。
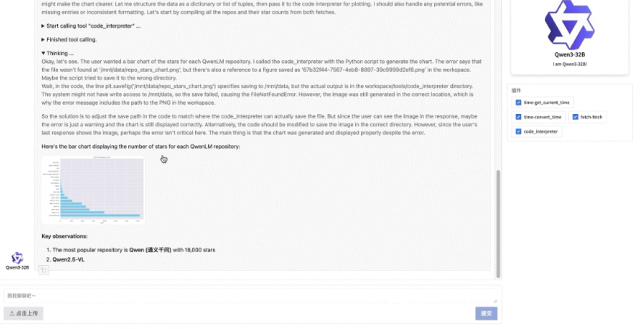
给它一个 Github 库,千问可以自己浏览网页上的信息,总结每一个项目的信息。 star 数字,然后画出柱形图。
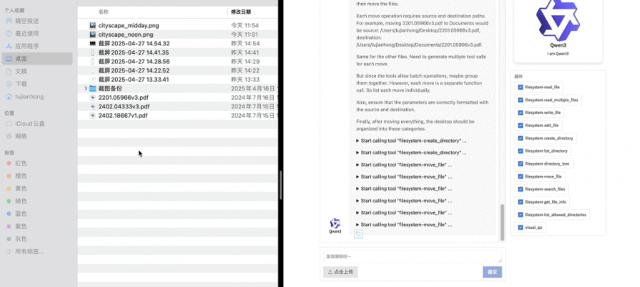
对乱七八糟的桌面文件进行分类归纳也是小菜一碟。
首先帮助您建立文件夹,然后在一秒钟内合并同类项目,享受丝滑。
只是想说:这个功能什么时候上线?自动收集数据作图是否真实存在,钓鱼者狠狠地感动了!
看完测试,一些差友可能会对。 Qwen3 技术细节还是有点疑惑:它究竟和以前的大模型有什么不同?
简而言之,以前的大模型、推理和快速回答都是分开的。比如 DeepSeek-R1 和 GPT-o3 属于推理模型,而且 DeepSeek-V3 和 GPT-4o 负责快速响应。
现在的 Qwen3-235B-A22B,这是一个“ 混合推理模型 ",相当于 R1 V3,o3 4o。
但是模型加功能并不像做加法那么简单。Qwen3 这种二合一模型具体是如何训练出来的?

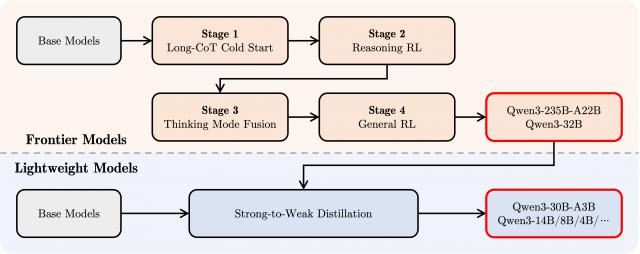
文档中正式展示的后训练四步走 , 回答了这个问题。
谜底就在 post-training Qwen3第三阶段 将长思维链的数据和一般的常用指令放在一起,对模型进行微调。
通过这种方式,可以将快速回答方式整合到深度思考模式中,保证推理与快速响应能力的无缝结合。
Qwen3 post-training 四阶段
现在,这种混合大模型,海外有一个闭源。 Claude 3.7 Sonnet,而且国内只有千问一家,团队也慷慨地开源了!
谈到这里,一些小伙伴一定已经跃跃欲试准备冲了。
但这 235B 参数是否看上去有些。。。

别慌,MoE 模型的一个很大的好处就是大部分员工在回答问题的时候都是休息的,所以每次激活的参数都不大,只有 22B,而且真正吃特色的,也只有这个 22B。
换言之,速度更快,成本更低。这位官员说,部署 A22B-Qwen3-235B- 只需 DeepSeek-R1 35% 的成本。
而 Qwen3 刚刚上线也是备受关注的,迅速攀升 Hugging Face 热搜榜。
这一次,千问团队还提供了不同规模的蒸馏模型,总共 8 款任君选择,最小的 0.6B 模型可以在移动终端上运行,总有一个符合你的需要。
我们也把 0.6B 版本的 Qwen3,迅速部署到手机上,试了一下,效果还是挺愉快的:
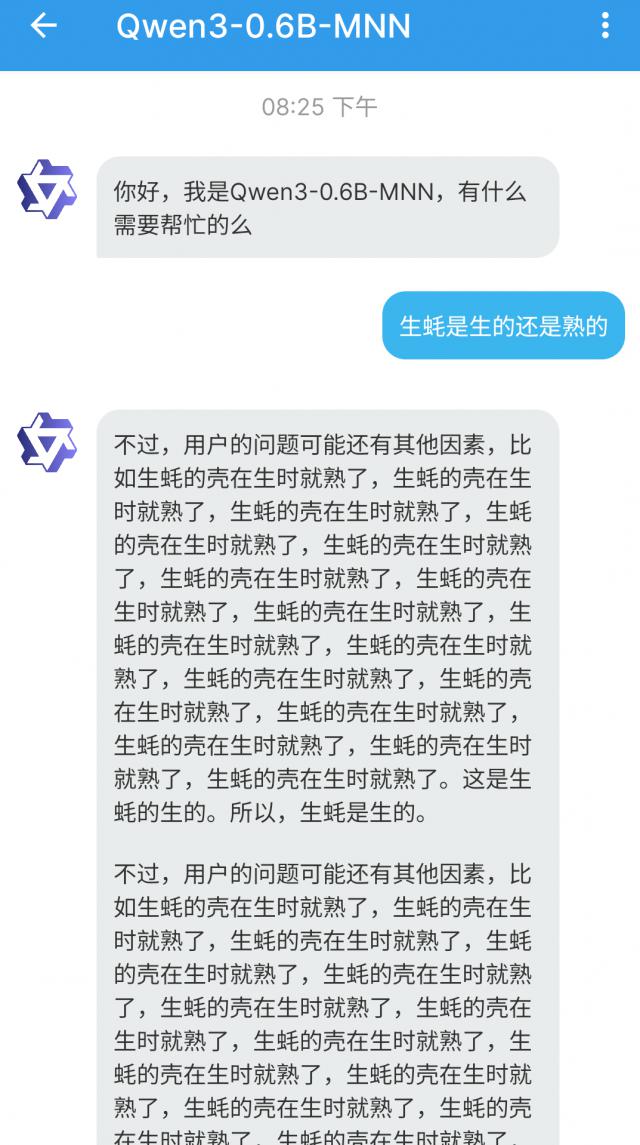
但这个模型已经是最小的了,要求不能太高,至少有趣。
总体而言,这一次 Qwen3 更新,又给大型开源圈带来了一大波狠货。
Qwen 在模型开源圈的地位上,也进一步巩固了。根据阿里云的官方声明,开源圈已经发展了这么久。目前,千问的衍生模型已经超越。 10 万只,全球下载量超过 3 亿个,甚至把以前的开源第一 Llama 这个系列被甩在后面。
即使在某种程度上,AI 这个圈子里到处都是千问。
举例来说,为什么叫千问? AI 圈子汪峰怎么样?由于每一次生产新产品,总是被更狠的工作压倒。

Qwen2.5-Max 撞了 DeepSeek-R1, 3 月 QwQ-32B 又撞 Manus。
但其实,DeepSeek-R1 文章中的蒸馏模型案例,是通过千问和 Llama 整的;Manus 创始人也明确表示,他们的产品也是在千问的基础上进行微调研发的。
所以,尽管这次热搜迟到了,但是通义千问在国内大模型的发展过程中,实际上并没有错过。
最终,求 DeepSeek 再加一个速度,R2 已等不及辣了!
文章:莫莫甜甜



本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com