
Qwen 阿里再次点燃了AI开源篝火。






文|邓咏仪
编辑|苏建勋
四月二十八日,AI圈的从业人员正在等待一件事:Qwen 3。
从中午开始,Qwen 三条即将发布的小道消息,已满天飞舞。Qwen团队负责人林俊邈也在X上暗示:“看看我们今晚能否完成Qwen。 3工作”。

“智能出现”所在的多个行业讨论组,充满了不知道真假的Qwen。 3模型上传截图。AI从业者疯狂刷新GitHub、Qwen主页在HuggingFace中,Qwen主页由AI生成 3网上海报,现场模拟图,霸屏各种表情包,狂欢直到深夜才停止。
Qwen 最终在凌晨5点上线。Qwen新一代。 3参数仅为DeepSeek-R1的1/3,第一,成本大幅下降,性能完全超过R1、OpenAI-世界顶级模型,如o1。
更加重要的是,Qwen 配备了Claude 3.7等顶级模型的混合推理机制,将“快思”和“慢思”融为一体,大大降低了算率消耗。
Qwen 3开源共涉及8种不同的结构和尺寸模型,从0.6B到235B,适用于更多类型的手机设备。除模型外,Qwen还推出了Agents的原始框架,支持MCP协议,并有一种“让每个人都使用Agents”的力量。
大年初一前夕,DeepSeek爆红后的一月,阿里迅速推出了Qwen2.5-VL和Qwen2..5-Max,在快速展示肌肉的同时,也给了阿里集团更强的“AI味道”。在这种情绪的背景下,阿里股价在春节前后大幅上涨了30%以上。
但是与这次的旗舰模型Qwen相比。 以上所有模型都只是前奏。
对Qwen 3所有人都期待阿里在AI开源社区的声誉——如今,Qwen已经成为世界领先的开源模型系列。根据最新数据,阿里通义开源200多个模型,全球下载量超过3亿个模型,千问衍化模型超过10万个模型,已经超过了之前的开源霸主Llama。
假设DeepSeek是一支精英队伍,在技术上迅速冲锋;那Qwen就是一支军团,对于大模型布局较早,也更积极地进行生态,展现出更广泛的覆盖面和社区活力。
在某种程度上,Qwen也是大型落地产业的方向标。
一个典型的例子是,在DeepSeek R1发布后,很多单位和个人都想私下部署“满血版”DeepSeek(671B),单硬件成本就要几百万元,落地成本更高。
阿里Qwen家族提供了更多的模型尺寸和类别,可以帮助行业更快地验证落地价值。就白话而言,开发者不需要自己裁剪模型,而是可以立即使用,然后迅速落地。Qwen 13B及以下模型,可控性强,的确是当今AI应用领域最受欢迎的模型之一。
DeepSeek R1已经成为开源历史上的锚点,也深刻影响了大模型竞争的趋势。与之前沉迷于刷Benchmark的模型制造商不同、做题,中国大厂迎来了一个必须证明自己真正技术实力的周期。
Qwen 3的发布,就是这样一段时间。
DeepSeek满血版的费用是1/3。 性能更强的R1
2024年9月,阿里云在云栖大会上发布了Qwen上一代模型。 2.5。Qwen2.5 从0.5B到72B的全系列模型一次性开源,涵盖了从端到云的全场景需求,可以在代码等多个类别中实现SOTA。
所有模型都允许商业使用和二次开发,这也被开发者称为 真正开放的AI”。
Qwen市场风传新一代。 第三,基于MoE架构,开源大小更大,成本可以比DeepSeek低-这些猜测都得到了一一证实。
Qwen 3 总共开源8个尺寸模型,分别是:
- 两个MoE(混合专家)模型的权重(指模型决策偏好):30B(300亿)、参数235B(2350亿)
- 六个Dense模型:包括0.6个模型B(6亿)、1.7B(17亿)、4B(40亿)、8B(80亿)、14B(140亿)、32B(320亿)
在同一尺寸开源模型中,每个模型都达到SOTA(最佳性能)。
Qwen 3延续了阿里开源的慷慨风格,仍采用宽松的Apache2.0协议开源,首次支持119多种语言。世界各地的开发者、研究机构和公司都免费下载模型并进行商业化。
Qwen 三是最大的看点,一是成本大幅下降,同时性能也大幅提升。
在Qwen 在训练中,阿里付出了令人惊讶的代价。Qwen 3基于36万亿token进行预训练,这是上一代Qwen模型。 2.5的两倍,也可以排在世界顶级同等体量模型的前列。
根据Qwen团队公开的数据,只需4张H20就可以安排Qwen。 3满血版,显存占用仅为性能相近模型的三分之一。
成本下降,但性能反而更高。
Qwen的推理能力有了很大的提高。就数学、代码生成和常识逻辑判断而言,Qwen 3都超过了以前的推理模型。 QwQ(思维模式)和 Qwen2.5 模型(非思维模式)。
但是,在代码、数学、通用能力等基准测试中,Qwen 也可以和现在的顶级模型o3-mini、Grok-3 和 Gemini-顶级模型,如2.5-Pro。
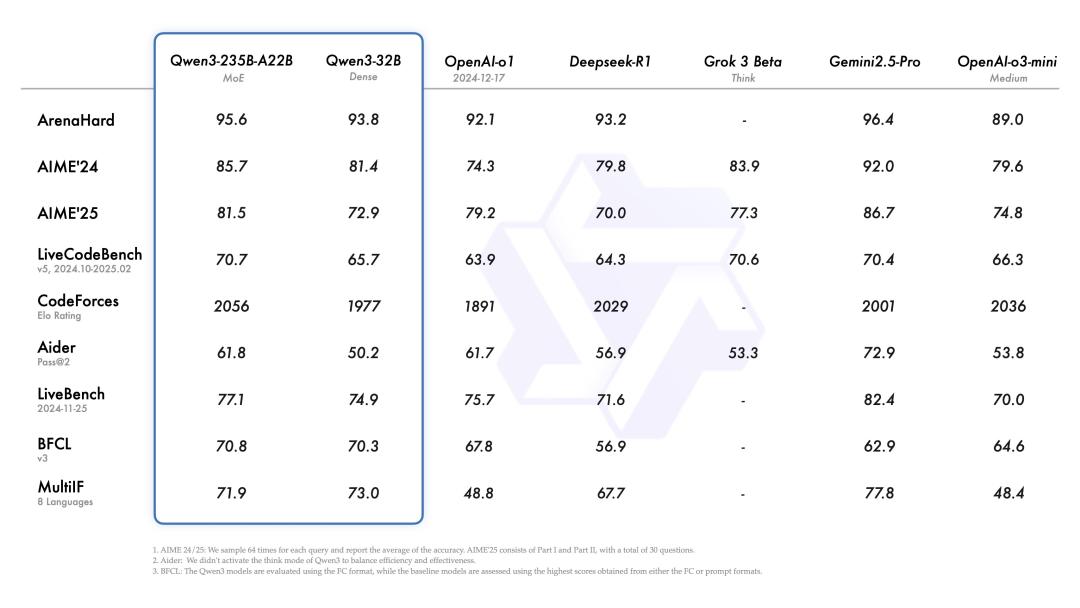
△Qwen 3性能图 来源:Qwen 3
另一个核心亮点是Qwen模型对于智能体(Agents)全面适配。
假设OpenAI的o1模型一脚踢开了推理模型的大门,DeepSeek R1的发布让所有用户看到了推理模型的魔力:模型有一个像人类一样的“思维链”,有一个思维顺序,不断验证是否正确,演绎出自己认为合适的答案。
但是如果只有深入思考,缺点也是显而易见的。即使你问简单的天气,今天穿什么,DeepSeek也会来回纠结,自我怀疑,不断验证,经历从几十秒到几十秒的过度思考——如果DeepSeek不向客户展示模型的探索链,基本上没有客户能忍受这样的对话感受。
2024年9月,阿里首席执行官吴泳铭在云栖大会上表示:“AI最大的想象力不是手机屏幕,而是接管数字世界,改变物理世界”。
智能体是通往这种愿景的重要途径。因此,Qwen3制作混合和推理模型至关重要:在单一模型中,思维模式(用于复杂的逻辑判断、数学和编码)和非思维模式(用于高效的通用对话,如询问天气、历史知识等简单信息搜索)可以无缝切换。
推理与非推理任务的融合能力,实际上是让模型:
- 能理解数字世界,更强调识别、检索、分类等非推理能力,
- 可操作数字世界,更注重推理能力,模型可自主规划、决策、编程等典型应用,如Manus。
Qwen 3的API可以根据需要设置“思维预算”(也就是预期深度思考的tokens数量),在一定程度上进行思考,确保各种场景都能达到最佳性能。
在以往的机制中,客户需要手动开关“深度思考”,一次对话中可能只能专注于一种方式;但是Qwen 3新机制将这一选择移交给模型-模型,可以自动识别任务场景,选择思维模式,降低客户对模型的干扰成本,带来更丝滑的产品体验。
混合推理是目前比较难的技术方向,需要极其精细创新的设计和培训,远比纯粹的培训推理模型难。模型要学会两种不同的导出分布,两种方式结合起来,基本不影响任何模式下的效果。
目前流行的模型只有Qwen。 3、Claude3.还有Gemini 2.5 Flash能做得更好的混合推理。
混合推理可以整体提高模型使用的性价比,既提高了智能水平,又整体降低了计算率能耗。举例来说,Gemini-2.5-Flash,在推理和非推理模式下,价格相差约6倍。
Qwen团队几乎提供了一个保姆式的工具箱,以便每个人都能立即开发Agents:
- Qwen 最近流行的MCP协议,有工具调用(Function Calling)能力,两者都是Agents的主要框架
- Qwen的原生-Agent 框架包装了工具调用模板和工具调用分析器。
- API服务也同步上线,公司可通过阿里云百炼直接调用。
如果以装修为例,这就像Qwen团队建造房屋并完成硬装,并为您提供一些软装,开发者可以直接使用大量服务。这将大大降低编码的复杂性,进一步降低开发门槛。例如,许多任务,如手机和计算机Agent操作,可以有效实现。
开源模型进入新一轮竞争周期。
DeepSeek R1在获得爆炸性音量并成为全球开源模型的标杆后,模型发布不再是简单的产品更新,而是代表公司战略的关键方向。
Qwen DeepSeek3的发布值 在R1之后,开源社区的新一轮竞争已经开始:2025年4月,Meta旗下的Llama 4月初正式发布,但由于效果不佳,受到了许多批评;而且之前屡遭挫折的AI巨头Google,也通过Geminini 2.5 pro,把一个城市拉回开源领域。
通用大模型层的能力还在快速变化,很难有厂商一直领先。在这个时间点,如何确定大模型团队的发展主线,不仅仅是一个技术问题,更是一个判断不同产品路线和业务的策略问题。
在Qwen 在3的发布中,我们可以看到一个更加务实的开源策略。
举例来说,Qwen3这次提出了一个模型尺寸,比Qwen3更大 2.5时的尺寸划分更加细致。实现资源有限的设备(如手机、边缘计算设备)的高效运行,Qwen 能够同时保证一定的性能,满足轻量级推理、对话等需要。
阿里仔细解释了每一个模型的适用场景:
- 最小参数模型(例如0.6B和1.7B):为开发者提供支持 speculative decoding(推断解码) 用作试验模型,对科研非常友好;
- 4B模型:建议应用于手机端侧。
- 8B模型:建议应用于计算机或汽车端面。
- 14B模型:适合落地应用。一般来说,开发者可以玩几张卡片。
- 32B模型:开发者和企业最喜欢的模型尺寸,支持企业大规模布局商业用途
但是在旗舰模型上,Qwen 3模型规模和结构,也是一种更加精巧,更容易落地应用的设计。
235B(235亿参数)和DeepSeek,Qwen旗舰版模型 直接对比R1满血版:
- Qwen 3 235B选择中等规模(235B)和高效激活设计(22B激活,约9.4%),只需4张H20。 可以安排GPU;
- DeepSeek-推荐16卡H20配置,R1追求超大规模(671B)和稀疏激活(37B激活,约5.5%),约200万元。
就部署成本而言,Qwen 3是25%-35%的满血版R1,模型部署费用大幅下降6-70%。
DeepSeek R1之后,如果大模型领域达成共识,那就是——再次将资源和人力投入到模型层面的技术突破中,让模型能力突破应用能力的上限。
现在大模型领域,再一次将目光转向模型能力的突破。
从Qwen发布主题的变化中,我们也可以看到当今技术主线的变化:Qwen 2.5发布时,主题是“扩展大型语言模型的边界”,而Qwen则是 第三,就是《思深,行速》,专注于提高模型能力的应用性能,拉低抑郁的门槛,而不是简单地扩大参数规模。
现在,通义千问Qwen在全球下载量超过3亿,在2024年HuggingFace社区全球模型下载量中,Qwen占了30%以上。阿里巴巴云模型的开源策略,已经走出了另一条更加清晰的道路:真正成为使用的土壤。
欢迎交流
欢迎交流
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com