
16年「英伟达」芯片史和未来趋势预测


本文全面盘点了英伟达自己。 2009 年起,16 年间在 GTC 会议上发布的各种芯片和结构,包括性能参数、市场影响力和技术突破,以及过去。 16 基于这一预测,总结了年度芯片发展过程。 GPU 结构与人工智能(AI)未来的发展趋势。
一、GTC 会议和芯片发布概览
自 2009 年首届 GTC 到目前为止,英伟达一直处于世界顶级地位。 GPU 新一代架构和芯片产品在技术大会上发布,推动了 GPU 图形渲染,高性能计算(HPC)、在人工智能和数据中心加速方面取得了革命性的进步。按年份分列如下:
2009 年:首届 GTC 会议拉开帷幕,为后续提供后续。 GPU 结构的发布奠定了基础。
2010 年:发布 Fermi 结构,并预告未来 GPU 家族——Kepler 与 Maxwell,这意味着新一代架构的蓝图首次显示。
2012 年:Kepler 结构正式发布,其突破性技术包括多线程(SIMT)优化,促进 CUDA 核心利用率大幅提高。
2014 年:Maxwell 为了更高能效、更好的并行计算和更优化的内存管理, GPU 提供性能升级的支持。
2016 年:Pascal 结构发布,重点提高能效和效率。 VR 为虚拟现实应用提供技术支持。
2017 年:Volta 架构问世,专为 AI 和 HPC 而且设计,内置张量核心(Tensor Core)大大加快深度学习训练和推理。
2018 年:Turing 结构发布,首次在消费级显卡中引入实时光跟踪技术,推动游戏和渲染技术的创新。
2020 年:Ampere 结构亮相,进一步优化了第二代张量核心和更高的带宽内存。 AI、游戏和数据中心的性能。
2022 年:Hopper 结构发布,重点面向 AI 和 HPC 在市场上,选择第三代张量核心和编程模型(例如 CUDA 图片),帮助大规模 AI 模型训练。
2022 年:Ada Lovelace 结构发布,可以为光线跟踪和基础 AI 神经图提供革命性的性能,显著改善 GPU 性能标准,更代表光线跟踪和神经图形转折点。
2024 年:Blackwell 结构发布,其第四代张量核心,先进的内存技术(例如 HBM3)和能效提升,是新一代 AI 推理和 HPC 提供强有力的任务支持。
2025 年:告知下一代结构 Vera Rubin,它具有 3.6 EF 的 FP4 推理性能和 1.2 EF 的 FP8 训练性能,整体可以达到 GB300 NVL72 的 3.3 倍数,同时在其它指标上也会有 2 大约倍增。
这一结构的发布,不仅体现了英伟达在硬件技术上的不断创新,而且对全球产生了深远的影响 IT 产业发展的趋势,特别是 AI 加速和图形渲染领域具有重要意义。
第二,详细的技术参数表格。
以下是自我整理 2009 年至今在 GTC 代表性芯片架构及其主要性能参数在会议上发布。表格中的数据都是基于公开数据进行整理,并在每个单元格中附上相应的引用。
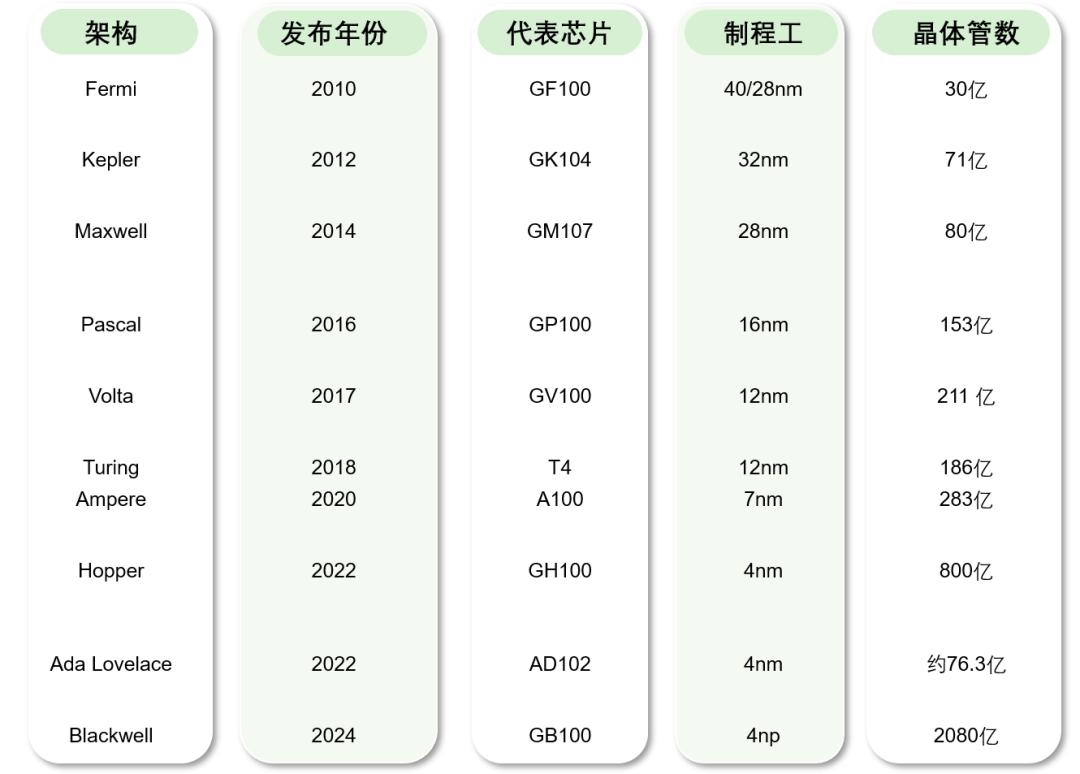
注:表中数据均基于各架构旗舰产品或数据中心级别。 GPU 典型的设备,部分消费级产品参数不同,但整体性能参数处于同一架构水平。如有差异,请指正。
三是各种结构的技术突破和市场影响
Fermi 架构(2010 年)选择第三代流处理器设计,每一个 SM 包括 32 个 CUDA 核心,大大提高了并行计算能力;错误校准码首次引入(ECC)内存技术提高了计算的稳定性,特别适合科学计算和数据中心应用。改进后的双精度浮点性能和硬件虚拟支持进一步扩大 GPU 应用范围。这不仅促进了这些创新 GPU 英伟达在高性能计算和专业图形市场中的领先地位也得到了科学研究、工程计算和数据分析等方面的广泛应用。
Kepler 架构(2012 年)则引进了 SMX 设计,每个 SMX 拥有 192 个 CUDA 核心,显著提高并行计算性能;另外,动态并行技术使得 GPU 无需 CPU 干预可以独立生成任务, Hyper-Q 技术使多种多样 CPU 核心可以同时向 GPU 发布工作指令,从而提高资源利用率。这些改进不仅进一步提高了英伟达在消费市场和专业市场的地位,也使基于该架构的产品在游戏、科学计算和可视化应用中表现出色,为后续产品的研发奠定了坚实的基础。
Maxwell 架构(2014 年)通过运用 SM 单元设计完成了更高的能效,改善了资源配置,不仅提高了性能,而且降低了功耗;内存压缩和数据调度机制在渲染过程中,GPU Boost 动态调频、精细化过程和缓存管理,大大提高了图形渲染和多任务处理的效率。这些技术进步使得高性能游戏显卡和轻薄笔记本市场更具竞争力。同时,英伟达凭借出色的性价比巩固了市场领先水平,为数据中心、人工智能等新兴领域的发展提供了有力支撑。
Pascal 架构(2016 年)通过重新设计,在提高能效方面取得了显著成效。 CUDA 为核心布局和内存分系统, VR 应用程序提供了更有效的图形渲染能力,提高了虚拟现实体验;硬件对混合精度计算(FP16)的支持也支持深度学习和 AI 应用为高性能显卡和数据中心的应用奠定了基础,并在散热和功耗之间取得了良好的平衡。 GPU。由此,GeForce GTX 1080 高端游戏市场脱颖而出, Tesla P100 它还在数据中心领域发挥了关键作用,同时促进了数据中心领域 VR、AR 以及新一代图形应用的普及,加速了 AI 商业化进程。
Volta 架构(2017 年)专门为加快人工智能和高性能计算而设计,首次引入张量核心(Tensor Core)通过加速矩阵运算,可以显著提高深度学习模型的练习和推理速度;同时,通过优化内部缓存水平和互联技术,可以加快数据传输速度,减少性能瓶颈,重点改进大规模并行计算任务。正是如此,Tesla V100 等 Volta 该系列产品迅速成为数据中心和超级计算中心的首选加速器,引领行业重视张量计算和专用加速器,进而推动了行业 AI 整个芯片市场的产品升级,为自动驾驶、语音和图像识别等应用提供了坚实的支持。
Turing 架构(2018 年)在图形渲染领域取得突破性进展,实时光跟踪技术首次大规模应用,大大提升了游戏和影视渲染的画质;同时保留了传统着色器和计算任务的高效支持,通过混合渲染模式完成了光跟踪和传统渲染技术的无缝结合。此外, CUDA 核心与专用 RT 协同优化的核心,使得整体计算效率和能效比显著提高。由此,RTX 2080 商品迅速占领游戏显卡市场,推动实时时间跟踪成为新一代显卡的标准,也引领了游戏引擎、影视后期制作、专业可视化等领域的技术创新,加快了设计和模拟过程的发展。
Ampere 架构(2020 年)这是一个全新的设计 CUDA 第二代张量核心与加强型内存子系统的结合,在核心上实现了较高的单线程和多线程性能,显著改善了 AI 练习和推理任务的效率;同时进一步优化能效,支持更高的显存带宽和更低的功耗,适应从消费水平到数据中心的各种应用领域。这些特征促使它们 GeForce RTX 30 系列和 A100 快速获得市场认可的数据中心卡,推动了市场 AI 模型推理和大规模数据处理的普及,为云计算和超级计算平台提供了更高的计算密度和更节能的解决方案,促进了游戏显卡与AI加速卡技术跨领域结合的新应用。
Hopper 架构(2022 年)针对 AI 深度提高了高性能计算,选择第三代张量核心高效处理大规模矩阵运算和深度学习任务;同时支持 CUDA 图和多实例 GPU 等待编程模型,使软硬件协同优化更加高效,并通过 4nm 工艺过程大大提高了晶体管的密度,实现了较高的计算密度和能效比。所以,代表产品 H100 迅速成为大规模 AI 实践和推理的首选加速了云计算和超级计算中心的升级,同时促进了大语言模型的生成。 AI 以及自动驾驶等前沿技术的发展,以及软硬件生态的完善,极大地激发了整个技术 AI 芯片市场的活力。
Ada Lovelace 架构(2022 年)第四代被引进 Tensor Core,支持 FP8 精确计算,使 GPU 吞吐量达到每秒 1.4 PetaFLOPS,这样就大大增强了 AI 计算能力加快了深度学习模型的实践和推理;配置第三代光跟踪核心,显著提高光跟踪性能,支持更复杂场景的渲染,呈现真实光影;同时,重排序通过着色器进行重排序。(SER)技术和 DLSS 3 对渲染效率和帧率表现进行技术优化。正因为如此,这个架构不仅使英伟达 GPU 在高端游戏和专业图形领域表现更加突出,在深度学习、数据分析等领域也拓展了应用范围,满足了在提高能效的同时对功耗敏感应用的需求。
Blackwell 架构(2024 年)代表现在的市场 GPU 第四代张量核心和先进内存技术的最高水平(例如 HBM3)的融合完成了极高的计算密度和能效;选择 4nm 工艺工艺使晶体管数量达到100亿级,大大提高了单芯片的计算能力,同时针对 AI 对大规模数据处理任务进行了推理和专项提升,并支持新一代编程界面和分布式计算方法。RTX 5090 和 B100 数据中心卡为数据中心和超算平台提供了前所未有的计算能力,推动了数据中心和超算平台 AI 模型迭代升级,帮助大语言模型、药物发现、气候建模等前沿领域的研究,同时为未来跨领域应用奠定基础。
第四,芯片发展过程总结
从 2009 到现在,英伟达已经存在 GTC 各代人在大会上发布 GPU 从图形加速到全面,架构展示技术 AI 加速跨越式发展。这篇文章分别从“从技术演变到架构创新”、多重提高性能和能效”、扩展应用场景”、完善生态系统和软件支持”总结如下:
早期的 GPU 架构(如 Kepler 和 Maxwell)以提高图形渲染性能和能效为主,为后续技术的发展积累了宝贵的经验。随后,随着 Volta 随着架构的推出,英伟达引入了张量核心, GPU 不仅在图像处理方面表现出色,而且成为 AI 重要的加速器,练习和推理。以后,Pascal、Turing 和 Ampere 在保证和提高传统图像处理能力的基础上,不断优化架构 AI 加速性能,完成游戏,虚拟现实和 AI 深度融合计算之间。但是在比较新一代的架构中,Hopper 大规模面向数据中心和数据中心。 AI 采用先进的工艺和编程模型,推动高性能计算和分布式计算的发展;同时,Blackwell 该结构主要服务于游戏和专业可视化市场,进一步提高了性能和能效。
随着性能和能效的提高,每一代结构都在显著增加晶体管的数量、内存带宽和核心数量。初期结构的晶体管数量约为几十亿,最新结构可达数百亿(具体值因型号而异),充分体现了技术和设计的双重进步。与此同时,通过不断优化架构模式,各代产品在能效方面也取得了突破,使在降低功耗的同时仍能保持强劲的性能。
伴随着技术的不断发展,GPU 使用场景也在不断扩大。初期 GPU 它主要用于图形渲染和科学计算, Volta 以及后续架构的发布,AI 加速、深度学习、自动驾驶、虚拟现实等新兴领域得到了极大的推动。Turing 与 Ampere 该结构完成了游戏与专业计算的无缝连接,Hopper 该架构致力于数据中心。 AI 推理和高性能计算, Blackwell 该结构进一步扩大了消费市场的应用边界。
另外,英伟达不仅在硬件方面不断创新,而且在生态系统和软件支持方面也做得很好。通过 CUDA 平台、cuDNN、TensorRT 以及对 OpenGL、DirectX 等待标准的支持,构建一个完整的软件生态系统,使开发者能够更方便地使用它 GPU 加快各种应用。伴随着每一代架构的发布,相关的驱动、编程模型和优化库也在不断升级,从而进一步释放了硬件的性能潜力。
五、将来 GPU 架构和 AI 发展趋势预测
基于过去 16 年度芯片发展历史,未来 GPU AI结构和AI的发展可能呈现如下趋势:
结构融合与多元化应用方面,技术突破的主要表现在未来 GPU 结构的系统化与多领域相结合,不同的应用领域(如游戏、数据中心、自动驾驶和边缘计算)将采用各自的结构。同时,在保证高性能的基础上,通过降低功耗和缩小体积,新一代架构借助更高的工艺节点(例如 4nm 到 3nm 甚至 新材料和新材料,2nm) 3D 封装技术,实现晶体管密度的提高和跳跃性能的突破。在市场影响方面,这些进步将满足嵌入式和边缘设备的需求,同时促进芯片在数据中心和高性能计算领域的广泛应用,进一步提高整体计算密度和能效比,增强各领域的市场竞争力。
智能计算与自适应架构领域,以技术突破为主 GPU 随着智能化的发展,其内置的自适应调节机制可以根据任务需要动态分配计算资源,并结合 AI 实现实时负载平衡和能耗管理,技术不断优化调度算法。另外,内置更多的特殊加速器(例如 AI 在处理特定任务后,推理引擎和神经网络处理器的协同处理方法也会带来显著的性能提升。在市场影响方面,该技术不仅可以实现“按需计算”,提高芯片在混合负荷场景下的计算效率,还可以帮助各行各业在人工智能技术、自动驾驶等实时数据处理领域获得更高效可靠的计算支持。
创新软件生态和编程模型,技术突破主要体现在开放标准和跨平台支持的推广上,CUDA 图片和新编程模型的普及使得软件库和开发工具更加智能,可以自动优化代码,深入挖掘硬件性能。与此同时,未来架构对上一代产品与不同平台之间的兼容性设计,以及对分布式和云计算环境的支持,也体现了全新的技术升级。在市场影响方面,这一进步大大降低了开发者高性能的使用 GPU 构建统一灵活的计算平台的门槛,从而促进数据中心和超级计算中心的升级,支持大规模计算。 AI 模型化培训与数据处理,拓展了市场应用和商业模式。
能源效率和排热管理,技术突破主要体现在绿色计算和能效提升上。芯片内部还集成了能效监控系统,依靠架构改进、新材料应用、更有效的散热设计和液冷技术,从而达到降低功耗、保持高性能的目的。在市场影响方面,这些改进为大规模部署提供了坚实的保障,特别是在数据中心和边缘计算领域,促进了绿色可持续的计算方案的实施,进一步减少了能耗问题和运营成本。
驱动领域的新兴应用,在元宇宙、虚拟现实、自动驾驶、边缘智能等方面,技术突破主要表现在应用需求上。新一代 GPU 在支持更高分辨率和更复杂场景实时渲染的同时,通过整合更多的特殊渲染核心,实现更真实的光影效果和物理模拟;对于自动驾驶系统的特殊改进,芯片可以在低延迟和高可靠性的要求下稳定运行,并在边缘计算设备中找到微型化和高性能的平衡。在市场影响方面,这些技术创新促进了显存带宽和处理速度的显著提高,为大型模型、元宇宙和虚拟现实技术的成熟提供了硬件基础,同时满足了自动驾驶和物联网实时数据分析的严格要求,给相关行业带来了巨大的商业应用价值。
六、结论
从 2009 年首届 GTC 到目前为止,英伟达已经不断地发布新一代。 GPU 该结构促进了行业技术创新,呈现出持续突破和稳步发展的趋势。
技术层面:各代架构从 Kepler 到 Blackwell,能源效率,内存带宽,CUDA 核心数量及 AI 在加速能力方面都实现了跳跃性的提高,促进了 GPU 从过去的图形加速到通用计算。 AI 加速变化。
市场方面:每一次结构创新都对消费级显卡、数据中心加速、高性能计算产生了深远的影响,不仅巩固了英伟达在 GPU 同时,市场的领先水平也加速了全球 IT 产业数字化转型。
未来展望:将来,GPU 架构将在模型、元宇宙、自动驾驶、边缘计算等新兴领域发挥更大的作用,朝着更高的能效、专用化、智能化和绿色计算方向发展。结合不断演进的软件生态和编程模型,新一代 GPU 它将为人工智能和数据驱动应用提供更强有力的支持。
总的来说,英伟达不仅引领了技术极限和创新架构模式的不断突破, GPU 技术的发展,也为全球数字化、智能化转型提供了坚实的技术基础。未来,随着应用需求的不断扩大,GPU 结构也将继续演变,推动计算技术走向更高的水平。
本文来自微信微信官方账号“学术头条”(ID:SciTouTiao),作者:小编,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com