
DeepSeek让英伟达H20疯狂抢购,但是AI推理的爆发不仅仅是靠囤卡。





什麽?H20都变成了香饽饽,涨价10万那种?!
最近有市场报道称,英伟达H20咨询量原本不受欢迎。暴涨几十倍,与年前相比,8卡H20机器的价格也更高涨价十万(价格在110万左右),一些从业者预测“价格不会下降”。
H20是中国特供版,显存带宽等方面明显受到限制,性能和性价比都远低于H100。
现在市场趋势发生了变化,业内人士透露,某互联网大厂已下订单10-20万卡,整个市场H20的订单量大幅增加。
其背后的原因,直观上是DeepSeek热潮。更深层次的是——
AI推理的需求爆发了。
尽管H20的性能只有H100的1/10,但做推理绰绰有余,显存充足,适合运行大规模参数模型,价格更便宜。
AI Infra制造商PPIO派欧云联合创始人兼首席执行官姚欣向量子位透露,去年年底H20并不那么受欢迎,但春节过后又是另一个场景,AI算率的供需正在迅速变化。
相应地,英伟达CEO黄仁勋在最新一季财务报告发布后也表示,目前AI模型所需的算率是以前的模型。100倍,提高计算能力需求的关键在于AI推理。
看到微知,AI算率行业的风向发生了变化,新的机遇也在考虑中。
DeepSeek重构计算逻辑,推理需求面临爆发
首先,DeepSeek以算法创新重构AI算率逻辑,推动AI计算从“训练为主”向“推理为主”转变,AI推理需求迎来全面爆发。
先看看DeepSeek做了什么?
今年开源的两个模型,在结构和算法上都提高了训练推理的效率。
第一,DeepSeek-在AI中,V3选择MoE(混合专家模型)架构。 Infra提出大规模跨节点专家并行(Expert Parallelism/EP)。
EP促使batch size大大提高了GPU矩阵乘法的效率和吞吐量。专家模型分散在不同的GPU上,每个GPU只需要计算少量的专家(因此访问存储需求较少),从而减少延迟。
同时,DeepSeek-V3的专家模型数量从上一版的160增加到256。“大量小专家”模型架构可以进一步减少一次推理时激活的参数。
第二,DeepSeek-利用强化学习,R1-Zero迈出了提高语言模型推理能力的第一步。通过纯粹的强化学习过程,在没有任何监管数据的情况下进化自己,从而获得推理能力。DeepSeek-R1采用FP8混合精度训练框架和动态学习率调度器等技术,将训练费用降至560万美元,远远低于OpenAI。并且可以将模型能力蒸馏到较小的密集模型中。
这一低成本模式使得AI推理场景得到了更广泛的应用。

第二,为什么DeepSeek能成为推动计算趋势转变的导火索?
从大模型的整体发展过程来看,预训练Scaling Law已经放缓,推理Scaling Law成了一个新的方向。
Scaling推理 Law的核心是通过增加推理时计算资源(如推理时间和计算率)来提高模型性能。以o1为代表的推理模型显著提高了推理能力,通过在推理阶段引入多步思维链,加强学习,导致推理计算需求大幅增加。
o1模型虽然好用,但不开源。DeepSeek就是因为这个原因,它们为整个行业提供了出色的开源替代方案。,瞬间改变整体情况。
DeepSeek以其低成本、高性能的特点,引发了全社会的热潮。不但普通人可以免费使用,大中小企业也可以将DeepSeek系列模型与自己的业务相结合。
尤其在ToB领域,高质量的开源模型解决了企业对数据维度的担忧。——没有人愿意免费向闭源模型提供自己或用户的数据进行培训。与此同时,DeepSeek暂时没有考虑到模型的商业化,更接近真正意义上的开源。它还点燃了公司拥抱AI的热情,加速了AI的落地过程,推理需求空前爆发。

结果,量变导致质变,AI计算需求和底层逻辑发生变化。
与预训练相比,推理计算对硬件门槛、集群建设等方面的要求更低。
超大型集群不再是必须的,小集群甚至单机将是未来的AI。 Infra的主要特征。
结合DeepSeek的一系列趋势和市场现状,PPIO姚欣对DeepSeek提出的跨节点专家并行系统进行了一定程度的分析。分布式思想上,它将不常用的专家模型集中在一台机器上,常用的专家模型分配更多的计算率。从而在调度上形成平衡。
这进一步扭转了算率行业的深层逻辑。本来大家都在期待英伟达如何从硬件上带来更好的推理性能。现在H800可以通过EP跑出H100的性能。
它还解释了为什么DeepSeek会影响英伟达的股票价格。由于系统优化,底层硬件的环城河并不深。
由此可见,H20这种原本不受大厂推崇的推理计算卡开始流行起来。即使更进一步,英伟达本身的地位也会受到影响。
姚欣判断,未来,英伟达一家独大的局面也将发生变化,推理时代,推理芯片将百花争艳。举例来说,根据DeepSeek研究者的测试结果,在推理任务时,升腾910C的性能可以达到H100的60%。
这样,算率供给侧的结构和逻辑就会受到进一步的影响。更具体地说, Infra架构的变化。
应该往哪个方向做?即将爆发的AI应用落地浪潮已经给出了指导。——优化与降本。
AI Infra肩负着推理时代成本优化的重任。
与预训练时代相比,推理时代是云计算,AI Infra有新的需求。
在预训练时代,云厂商提供的服务更倾向于一个裸金属的实践环境。因为是集中集群,几乎每台机器都跑满了,云厂商可以提升的空间有限。在推理时代,每个企业更倾向于选择公共云服务部署模式。
也就是说,云厂商的下一个竞争点应该是从不同的卡型到模型层的全栈提升。
但是为什么是AI呢? Infra/云厂商来做?
从技术底层到实际成本优化,AI Infra/云制造商具有自己的生态优势。
从技术角度来看,并非所有AI厂商都有高并发、高流量、高弹性的网络服务经验。
比如前不久DeepSeek突然宣布成本利润率理论值可以达到545%,引起了很多行业的争议。
姚欣说:PPIO:
身为一位真正为4.5亿用户服务的创始人,真实情况下,所有互联网用户的请求都必须有波峰、波谷,一天的客户请求变化应该是一条曲线。如果是在高峰期,突然变成一条直线,那就意味着,在那段时间里,顾客请求无法进入。
所以综上所述,DeepSeek的服务在春节期间已经崩溃,无法满足客户和公司的服务。
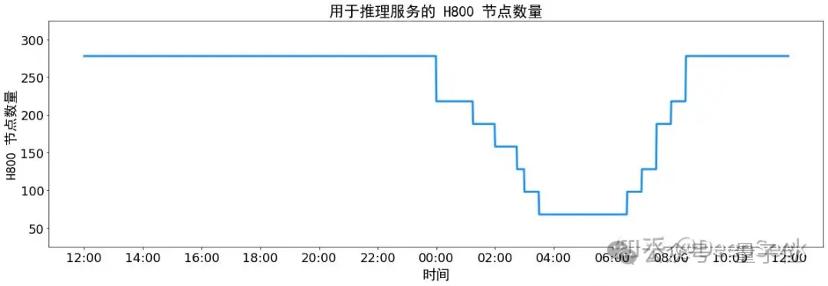
换言之,DeepSeek需要进一步的服务和技术结构。“弹性”计算率,只有这样,我们才能处理这个问题。春节期间,PPIO派欧云第一时间接入DeepSeek,利用分布式推理和大规模计算率调度,实现了更加灵活的负载平衡,保证了客户的服务水平和稳定性。
另外,在基础设施建设方面,AI Infra制造商更具先天优势。
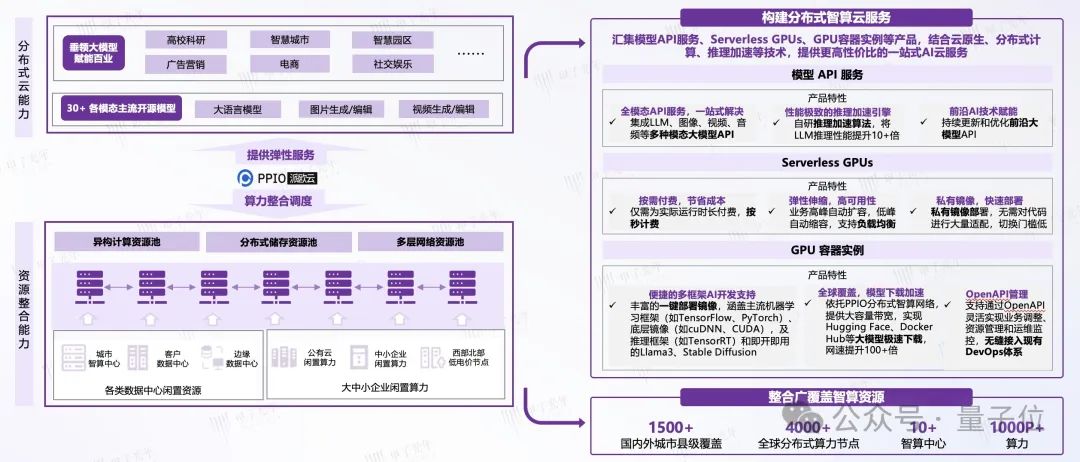
有的玩家通过自建IDC提供各种计算率服务,代表玩家有阿里云等。有的玩家选择通过分布式网络提供计算率服务,不建立自己的IDC。、代表玩家拥有PPIO派欧云,而不是购买GPU,而是通过独特的算率共享调度。
相比之下,前者可以提供更多的综合服务,后者在性价比和资源调度方面更有优势。
比如PPIO分布式架构,打破了传统集中架构的瓶颈,不仅大大减轻了公司的运营和维护压力,而且将系统的处理效率提高到了一个全新的高度。通过PPIO提供的AI推理平台,公司可以直接调用API服务,而不是自己部署后台服务的复杂过程,不再需要自己运营和维护。直接降低40%的成本。
速度方面,得益于PPIO遍布全球的分布式云服务系统,无论客户在哪里,都能找到近距离的计算节点,获得20毫秒的低延迟感。PPIO可以通过独特的方式调用全国计算节点,为企业用户带来更灵活、更持久、更具成本效益的AI推理服务。

据悉,PPIO在整个春节期间ToB角度的DeepSeek服务可用性达到99.9%,没有TPM限制。关键在于底层弹性充足。目前,PPIO平台的日均tokens消耗量已超过1300亿元,与“六骁龙”的日均tokens消耗量不相上下。
另外,在算法方面,PPIO还提出KV Cache稀疏压缩算法,Hydra Sampling投机取样技术和端到端FP8推理三大核心技术,进一步突破了显存、计算能力和带宽对大模型推理特性的限制。因此,PPIO可以快速适应和优化各种大型开源模型。举例来说,PPIO计算云产品已经为百川智能提供大规模的AI推理服务。
"只有AI Infra公司可以提供足够高性能、低成本的基础设施,让大量的AIFra 使用的收益足以覆盖所有的推理成本,从而迎来AI应用的大爆发,客户也将迎来AI。 应用的免费时代。”姚欣表示。
为了进一步加快大规模应用的落地,DeepSeek振臂一挥之后,还需要全行业上下游通力合作。
现在,值得关注的玩家纷纷站出来,在承担流量的同时,进一步推动新浪潮的发生。AI Infra玩家的动作,仍然只是表现之一。
而且随着越来越多的行业合作伙伴的加入,更大的需求和市场仍在考虑之中。
趋势变化之后,又是一个新的开始。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com