
稚晖君做了一个 “好东西”,网络视频也可以用来训练机器人






上个星期五,稚晖君并没有在微博上做一波浅浅的预告。 "好东西" 嘛。
就在星期一,智元机器人立刻将热气抬起。
机器人为您端茶倒水,煮咖啡。

将面包放入面包机中,将烤好的面包涂上果酱,然后将面包端到您面前,整个动作一气呵成。

也可以在公司当前台,充当迎宾。

也就是说,在看到了多种人类机器人的视频之后,世超对于这种程度的展示,已经不足为奇了。
所以仅仅这些演示,还不足以称之为好东西。智元机器人此次发布的底座大模型 GO-1 ( Genie Operator-1 ),这才是真正值得拿出来唠叨的好东西。
这么说吧,这一大型底座模型,使得人形机器人长期缺乏数据、泛化能力差的问题更加有效地解决了这一问题。
也许每个人都知道,现在的人形机器人之所以看起来很拉胯,其中一个重要原因就是 缺少高质量的数据。
而且获取这些数据的成本,同样也很高。
为解决这一行业难题,去年年底,智元机器人已开源百万真机数据 AgiBot World 。

AgiBot World 所有的数据都来自智源的数据采集工厂,里面有很多模拟真实场景。数据采集者的日常任务是教机器人如何执行某些任务。
据官方声明, AgiBot World 包括了超出 100 万条轨迹、 217 个任务和 106 一个场景。但即使是这个数量级的数据,对于机器人来说还是九根牛一毛,机器人泛化能力差的问题也无法处理。
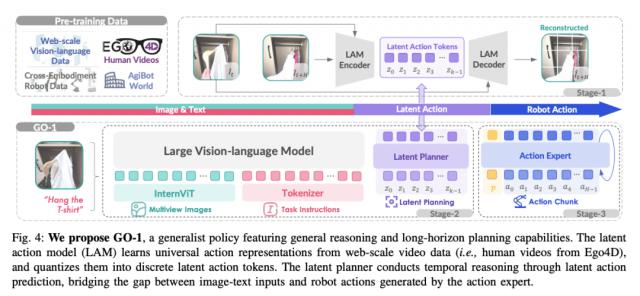
所以,智元机器人才正在进行 AgiBot World 在此基础上,又提出了新的建议 ViLLA ( Vision-Language-Latent-Action )架构。这一结构,就是 GO-1 大型模型的关键。
世超翻翻了翻智元机器人发表的论文,简单地用大白话给大伙儿介绍一下, ViLLA 牛到底在哪里?

第一,在数据方面, ViLLA 结构没有那么挑剔。
据官方介绍, ViLLA 架构是 由 VLM ( 多模态大模型 ) 和 MoE ( 混和专家 ) 构成。
传统的 VLA 结构,融合 VLM 而且端到端的特点,因此这种结构需要大量标注的真机数据进行训练,费钱费力,而且信息量还很小。
ViLLA 尽管本质上还是如此 VLA 结构,但是它强大而强大,这些网络上的人类视频数据也可以使用。。
换言之,基于 GO-1 理论上,大型机器人只要 "看过" 录像,可以学习相应的动作。

对这些原因来说,世超觉得很有可能是因为这个原因 “潜在动作” ( Latent Actions )。
咱还是拿 VLA 作为对比, VLA ( Vision Language Action )在执行任务时,结构就是这样一个过程:输入图像和语言指令,然后机器人根据这些信息生成并执行指定动作。
看起来简单直接,但是稍微遇到一些复杂的任务,机器人会变得能够理解和理解,但是做不好甚至做不到。
举例来说,我们要求机器人( VLA 架构 )制作一杯咖啡,机器人可以看到咖啡机在哪里,也可以理解我要它做咖啡。
可是, VLA 机器人在架构下应该直接存在。 "看见咖啡机"" " 懂得做咖啡 " ,突然想清楚所有的步骤,然后马上开始,中间没有思考的过程。
DeepMind 的 VLA 模型 RT-2
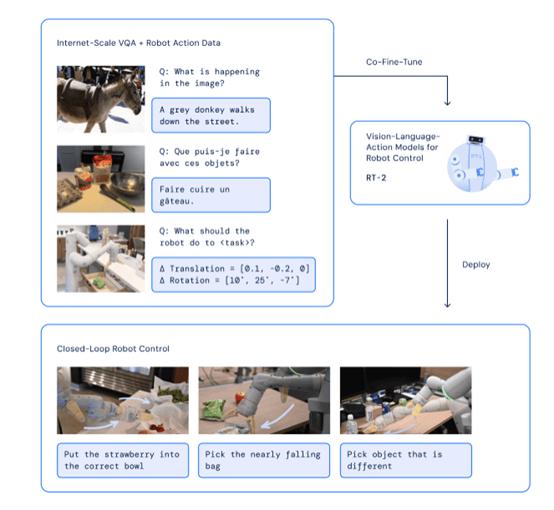
问题是泡咖啡其实中间有很多小步骤,比如找咖啡豆,打开咖啡机,按下开关。即使人们来了,他们也应该在做任何他们想做的事情之前思考一下。
更何况是 "一根筋" 的 VLA 结构,让它处理中间这些复杂的过程,多少有些让它难堪。
但 ViLLA 结构,引进了两个人 "专家" :隐式规划器( Latent Planner )和动作专家( Action Expert )。
这两位专家不仅可以让机器人想得更多,而且可以做更多的事情。

不懂专有名词也没关系,我们继续举例吧。
假定现在输入一个视频,就是一个人拿起杯子喝水。
VLM 多模态大模型将首先处理视频,然后进行潜在的动作模型。( Latent Action Model ),这些复杂的视频动作将被分解成几个关键步骤,例如 "抓取" 、 " 挪动 " 和 " 喝水 " 。
但是光到这一步是不够的,隐式规划器( Latent Planner )要继续加工关键步骤,生成更详细的步骤: "抓住(杯子),移动(杯子到嘴边),喝" 。
最后,动作专家( Action Expert )把这些步骤全部转换成机器人可以理解的信号,让机器人执行动作。
因此 ViLLA 在执行复杂任务时,架构的表现将比较 VLA 更加出色,也更加适应当前人形机器人的实践需要。
而且世超也注意到了, ViLLA 结构不依赖于特定的硬件。
也就是说, VLA 结构是根据特定的机器人本体,特定的场景,生成动作信号, ViLLA 结构产生的是 "抓取" " 挪动 " 这一通用动作标记,具有较好的任务泛化能力,也更容易转移到其它机器人平台。
给大伙儿一句话总结一下,GO-1 使机器人能够从互联网上的人类视频数据中学习,增强拆解任务的能力,提高复杂任务的成功率,同时提高泛化能力。
如果 GO-1 效果确实如官方所述,那么这对于整个人形机器人行业来说,或许是个好消息。
不用担心数据,还没有选择平台,这个机器人训练起来就方便多了。我就是不知道这个。 GO-1 ,智元是否会选择继续开源?
听到这里,智元机器人明天还要释放一个惊喜,让我们等一手行。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com