
百度文心4.5即将到来,大型应用赛按下加速键。






百度官方宣布,2月28日将于3月16日发布文心大模型4.5。
据媒体报道,百度文心4.5将于3月中旬发布,28日凌晨,OpenAI发布了GPT-4.5模型,OpenAI发布GPT-4.5的时间节点恰好是媒体爆料的第二天。所以业内人士分析OpenAI仓促发布GPT-4.5的重要原因可能是中国竞争加剧。

但是略显仓促的GPT-4.5性能被业界评价为不尽如人意。而且据百度介绍,文心大模型4.5不仅大大提高了基础模型的能力,而且具有原生多模态、深度思考等能力。在DeepSeek大火之前,百度也在2月中旬宣布,文心一言将于4月1日0时起全面免费,所有PC端和APP端用户均可体验文心系列的最新模式,并于6月30日起开源文心大模式4.5系列。
百度将在4月和6月举行一系列大动作,如“免费”和“开源”,这反映了百度的信心,也引起了市场对4.5的关注和期待。
文心大模型4.5定档,百度历史上最好的模型即将到来。
从2019年3月开始,百度率先开始训练大模型,并于2023年3月16日正式推出文心大模型。目前,百度已经将5500多亿知识的自研知识地图融入到文心大模型的预训练中。结合深度学习和大量行业数据,现已应用于百度搜索、信息流、智能驾驶、百度地图等多种产品。
从那以后,百度每年都会迭代模型。百度文心大模型矩阵增加了“力作”,全家桶更加丰富。两年后,百度再次发布了一个新的大模型。据了解,3月16日发布的文心大模型4.5将具有多模式和深度思维能力,尤其是深度思维能力,成为市场预期的焦点。
文心大模型4.5到底有什么能力值得期待?
2月18日的财务报告电话会上,百度创始人、董事长兼首席执行官李彦宏透露,文心大模型4.5将是百度迄今为止最强大的模型。“希望客户和用户能比以前更方便地感受到这个模型”。

文心最近推出了“深度搜索”功能,具有专家问答能力和突出的RAG能力。特别是行业问答的低幻觉率已经降到了最新水平,百度去年发布了自研iRAG技术,这也是李彦宏对“史上最好的模式”的信心来源。
而且OpenAI最新推出的GPT-4.5并不具备多模式推理能力,或者主要推广写作等文本生成。与OpenAI相比 的 ChatGPT、谷歌的 Bard ,作为一种扎根于中国市场的本土语言模式,是目前市场上最适合中国人使用的语言模式。
研发投入1700亿
大模型流行了三年。为什么头部玩家还是只有那些实力雄厚的大企业?根本原因是大模型很贵,不是一般企业能玩的。其主要成本包括硬件、电力、数据、R&D部门等。
大模型的计算能力需求很大,大模型的训练需要高性能的计算集群,单卡成本可以达到几万美元。以GPT-3为例。训练需要1万元左右的GPU,训练需要几个星期。仅训练成本就高达几千万甚至上亿美元。这不包括高负荷运行导致硬件寿命缩短、维护和更新的成本。
公开数据显示,GPT-四次培训费用约6300万美元,年运营费用超过10亿美元。Google PaLM(5400亿参数):训练费用大约在2000-3000万美元之间。即使是数百亿参数级模型的训练费用也通常在数百万美元之间。
百度能够在模型上得到让OpenAI不得不仓促发布新产品的结果,根本原因在于舍得“烧钱”搞研发。财务报告显示,从2019年到2024年,百度的R&D支出分别为183.5亿元、195.1亿元、249.4亿元、233.2亿元、241.9亿元和221.3亿元。在过去的四年里,R&D支出超过了220亿元,R&D支出占总收入的比例一度位居全球互联网巨头之列。2020年,在全球互联网巨头中,百度的研发比例高于谷歌和亚马逊,位居世界第二。
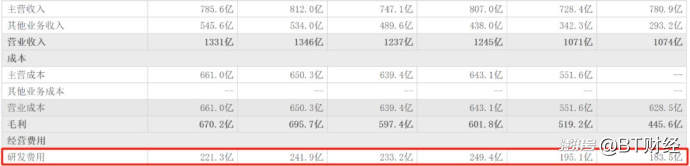
目前百度的R&D比例一直保持在20%左右,而全球互联网行业的R&D比例平均在3%-6%之间。比如小米的R&D比例在4%左右,联想的R&D比例在2.5%左右,JD.COM的R&D比例在1.6%左右。百度和华为已经成为国内唯一一家R&D比例超过10%的互联网公司。
财务报告数据显示,百度在R&D投资AI10年,累计投资1700亿元。在模型领域的巨大投资使百度成为世界大模型的领导者。
AI行业大震动——连续开源,免费,百度更开放。
目前,大型模型已经进入一个新的阶段。模型基础通过开源路线普及,从而带动模型应用的爆发。
李彦宏在财务报告电话会议上特别解读了百度的开源。李彦宏表示,开源4.5系列决策来源于对技术领先水平的坚定信念,开源将进一步推动文心大模型的广泛应用,扩大其在更多场景中的影响力。“但我想重视的是,无论开源闭源,基本模型都只有在大规模处理实际问题时才有真正的价值”。今后,百度将加快推动文心大模型性能升级和降低成本。
作为技术领域的核心合作方式,开源的价值体现在R&D、经济、社会等多个维度。在技术驱动方面,u200c提高了软件的质量和安全性。u200c开源代码的透明性允许全球开发者共同审查和修复漏洞,形成持续优化的技术迭代机制。开放源码打破了技术垄断,开发者可以根据当前的成果快速迭代,u200c加速了技术创新。最重要的一点是,开源可以降低行业的整体成本。在谈到DeepSeek时,李彦宏说:“历史上所有的创新都来自于成本的下降,而大模型的成本每年都在下降90%以上。”开源占据了绝大多数角色。

互联网投资者史保刚称赞百度的开源。“随着R&D的加速,百度推出了免费和开源,以促进整个行业的发展。百度的适配和开放也体现在接入DeepSeek上,让百度在大模型竞争中占据主导地位。根本原因是百度对自身技术的信心。”
史保刚认为百度直接将行业拉入“免费” 开源“新阶段,将大模型的使用门槛拉到极致,无疑会推动大模型应用的爆发。它不仅促进了行业的发展,也促进了百度自身大模型的发展,极大地促进了百度和行业的发展。
使用场景和产品体验为王的时代
大型应用场景和产品体验设计是决定其技术价值能否转化为实际商业或社会价值的关键,无论是百度文心还是ChatGPT-4。大型机型的技术能力至关重要,但是产品体验决定了客户是否愿意继续使用,也是决定大型机型是否能够通过市场检验的基础。现在第一轮百模对决已经结束,接下来就是应用对决。如何给大家一个接入最先进技术的机会,落地场景是各大头部玩家的目标。
当前,百度文心大模型技术正经历着从u200c“能力展示”到“价值交付”u200c的关键转变。未来三年,对u200c场景有深刻的了解。、u200c交互好感度u200c、在医疗、金融、制造等领域,u200c价值可以量化u200c特性的商品将继续释放变革能量u200c。在这个过程中,技术普惠与伦理标准的双轨并行,将定义智能时代的新生产关系。
在使用场景和产品体验为王的时代,百度心脏大模型的很多场景体验都通过了市场测试,完成了“应用落地”,代表了中国大模型领域的最新技术和发展路线。这一次,李彦宏自信地带着“百度历史上最好的模型”来到这里。在使用场景不断丰富、应用领域真正落地的情况下,市场对百度最新的力量有了更多的期待。
有DeepSeek在春节期间走红,然后百度不断开源免费,中国的大模型超过了美国的加速。以百度为代表的中国公司在算法上的巨额投资产生了一个强大的基础模型,那就是环城河。目前,OpenAI已经被“逼出”GPT-在4.5的背后,是中国大模型不断提升能力赶超美国的证实。
本文为BT财经原创文章,未经许可不得随意使用、复制、传播或改编,如构成侵权行为将追究法律责任。
作 者 | 梦萧
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com