
减价75%,DeepSeek“避峰定价”,给豆包带来压力?






DeepSeek 仍在搞事。
这是官方的钦定「开源周」,DeepSeek 本周,四个项目陆续开源。周四,最新发布了计算与通信并行的项目。 DualPipe(直译为「双向管路」)。与此同时,DeepSeek 还有一项不大不小的工作——避峰定价。
周三(2 月 26 日),DeepSeek 从那天起,北京时间每天都在发布。 00:30 至 08:30 夜间空闲时间,DeepSeek 开放式平台推出避峰优惠活动。可以在前一天,DeepSeek 刚刚恢复官方 API 充值服务。
但是说回优惠,DeepSeek 不能说是不给力。据官方消息,DeepSeek API 在夜间空闲时间,调用价格将大幅下调:DeepSeek-V3 降到原价的 50%;DeepSeek-R1 更是低至 25%(降了 75%)。
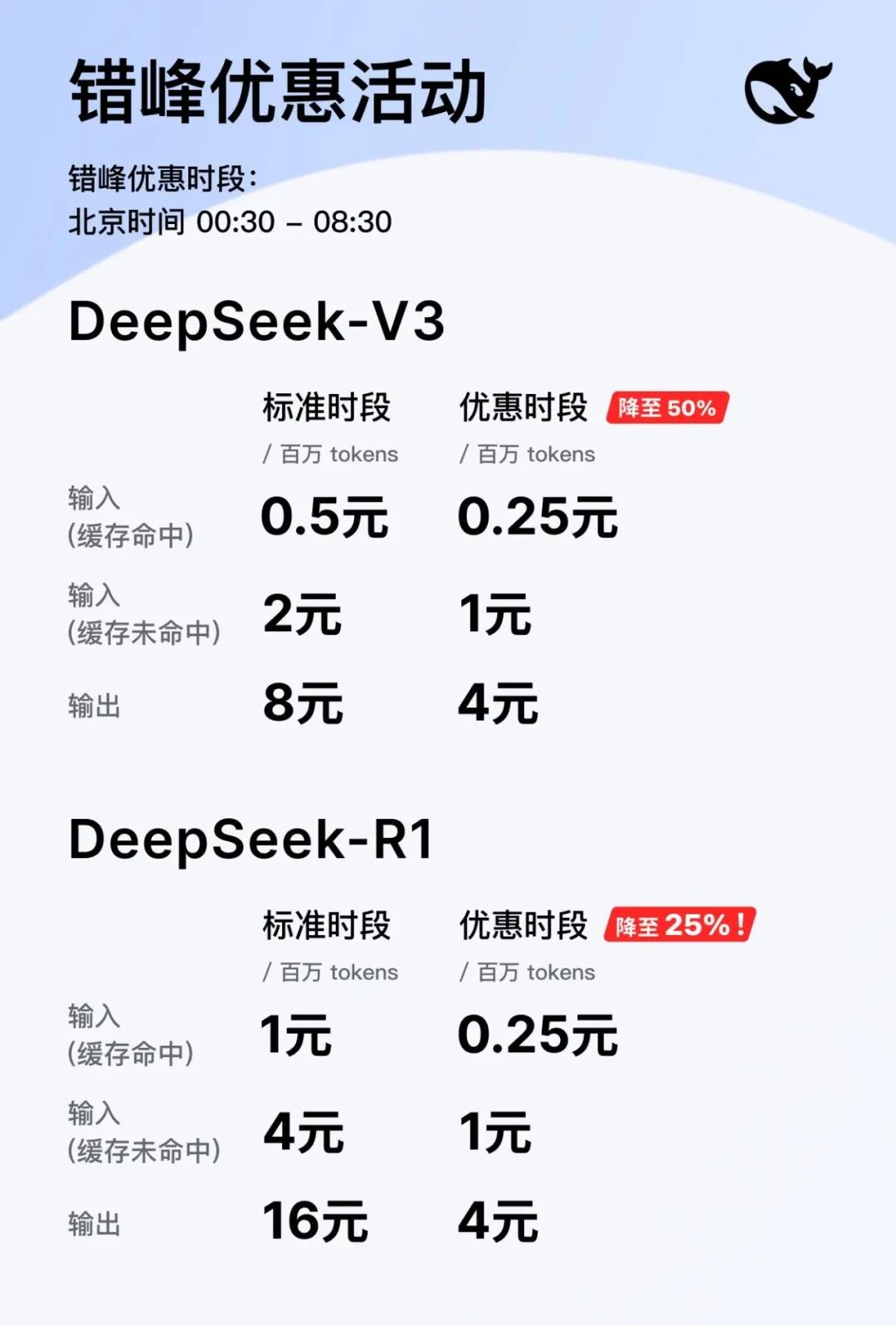
图/ DeepSeek
具体调价如图所示,不再赘述,反正就是帮兄弟们。「自砍一刀」。
值得注意的是,有别于。 DeepSeek-V3 发布之初的「优惠感受期」有明确的时间限制,此次避峰优惠只有「时段限定」,而没有「期限」。换言之,我们可以简单地将避峰优惠视为长期的:
「避峰定价」。
另外还有一点必须提到的是,两款车型不仅优惠期一致,而且优惠后的价格也完全相同:
输入(缓存命中)为 0.25 元 / 百万 tokens;
输入(缓存未命中) 1 元 / 百万 tokens;
输出为 4 元 / 百万 tokens。
这可能也是 DeepSeek 有意为之。
归根结底,推理模型已成为大型模型制造商的共识,通过在优惠期拉齐定价,DeepSeek 不但能减少开发者的使用 DeepSeek-R1 成本顾忌,实际上还模糊了两种模式的界限,激励开发者根据自己的需要灵活调用两种模式。
就像前几天一样 Anthropic 全球首款混合推理模型推出——Claude 3.7 Sonnet,传统模型的融合「快速回答」以及推理模型「高级推理」实现更加灵活的计算和更加合适的优势 AI 感受。
图/ Claude
不过 DeepSeek 这次调整的核心变化是什么?「避峰定价」这一运营策略的选择,「肉眼可见」其优点极有可能导致豆包、通义千问等其他大型模型的跟进,甚至成为另一场大型价格战的导火索:
一如 2024 年初 DeepSeek-V2 这场价格战在发布后掀起。
DeepSeek-R1 杀价!比豆包便宜吗?
值得注意的是,DeepSeek-V3 事实上「降过价」,之前雷科技报道过 DeepSeek-V3「优惠感受期」这个月初结束了,那么之前整个时间段的优惠价格甚至比现在的优惠价格更便宜:
输入(缓存命中)为 0.1 元 / 百万 tokens;
输入(缓存未命中) 1 元 / 百万 tokens;
输出为 2 元 / 百万 tokens。

2 月初结束,图/ DeepSeek
但是不同的是,DeepSeek-R1 但是没有,发布以来价格一直没有变化,都是输入(缓存命中)1 元 / 百万 tokens、输入(缓存未命中)4 元 / 百万 tokens、导出 16 元 / 百万 tokens。
而且相对来说,这也让这一次 DeepSeek-R1 高达 75 折的「避峰减价」更加惊喜。
第一,在能力方面,我相信今天已经不需要强调了。 DeepSeek-R1 它的表现,无论是产品层面思维链的创新,还是工程方面实现的极致成本,都让 DeepSeek-R1 现在已经成为最成功的模式。
在此基础上,降价无疑是降低开发者调用成本和门槛最有力的策略之一,间接会进一步提高。 AI 感觉推广到更多 AI 应用程序(通过接入 DeepSeek)中。
事实上,标准时间段 DeepSeek 价格已经比许多其它厂商的大型模型便宜了,而且有优惠时间 DeepSeek,更加便宜的是相对于很多主力大模型:
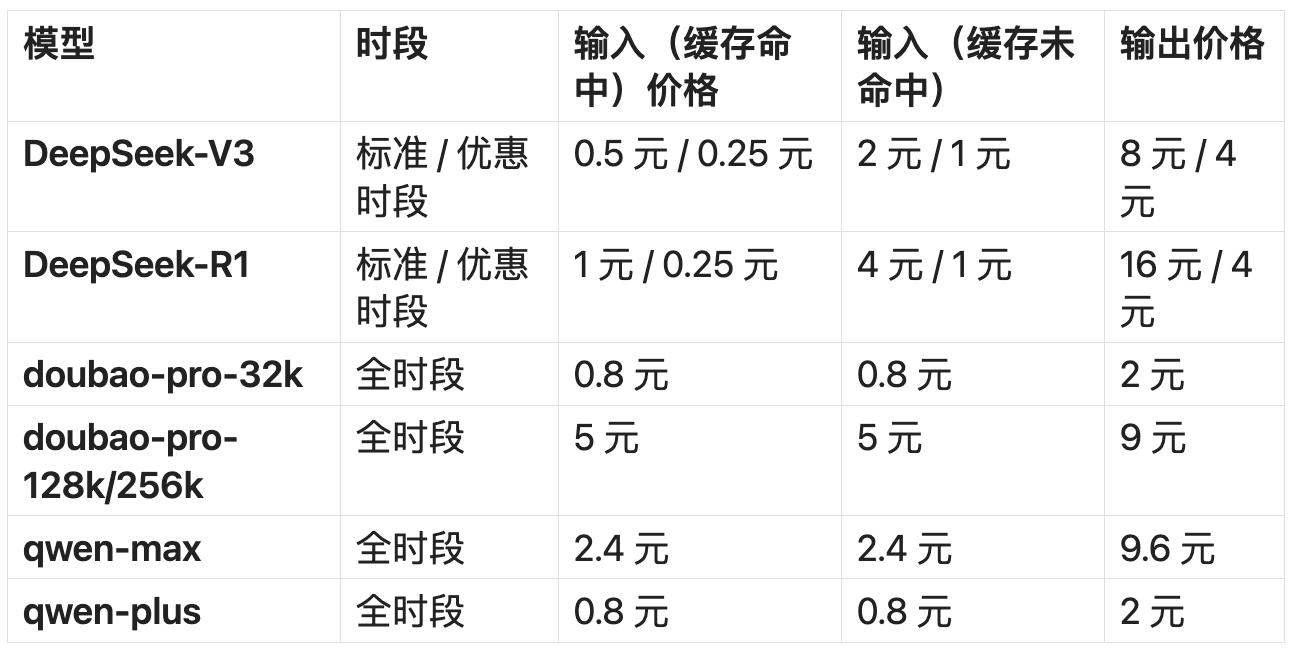
单位是每百万 tokens,图/雷科技
以字节跳动旗下的豆包通用模型为例,火山引擎平台显示的价格如下:doubao-pro-32k,输入为 0.8 元 / 百万 tokens,输出为 2 元 / 百万 tokens;doubao-pro-128k / doubao-pro-256k,输入为 5 元 / 百万 tokens;输出为 9 元 / 百万 tokens。
甚至我们也可以看到,火山发动机 deepseek-r1-distill-qwen-32b(蒸馏版)的价格是:输入 1.5 元 / 百万 tokens、导出 6 元 / 百万 tokens。
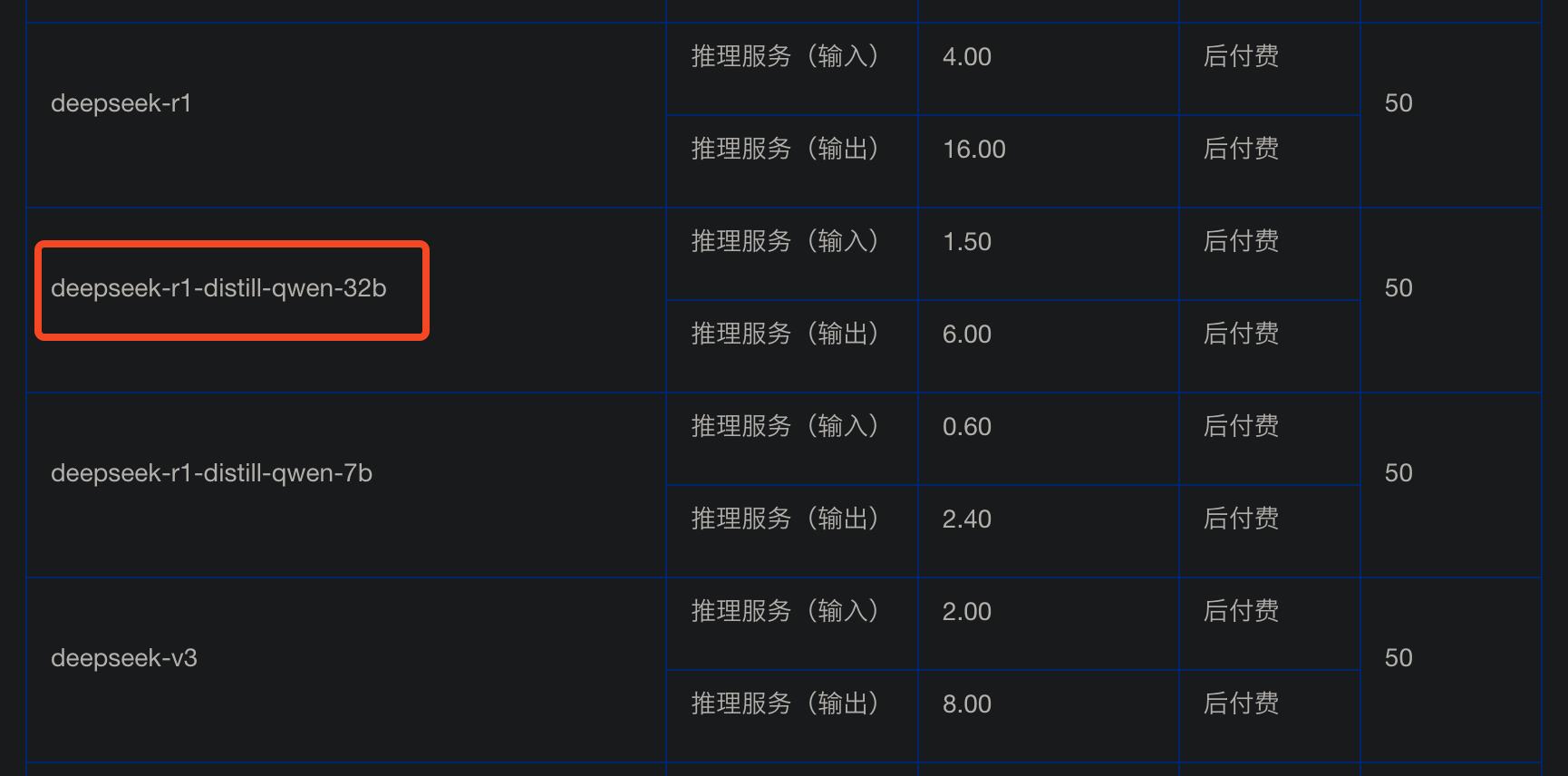
也就说,DeepSeek-R1 在优惠期间,官方满血版的价格,甚至比较 32b 蒸馏版也更便宜。
而且还只是在国内,DeepSeek-R1/V3 同样的运营策略也在国外推出, 50% 和 75% 大幅度降价,而且优惠期是直接对应北京时间的。 00:30 至 08:30。换言之,伦敦时间 16:30 至 00:30、纽约时间 11:30 至 19:30 都能直接体验到 DeepSeek 官方优惠期的价格。
换言之,DeepSeek 对许多面向海外用户市场的开发者来说,仍然具有更高的吸引力,相当于在高峰期享受优惠期的价格。
避峰优惠非常动人,豆包们将如何迎战?
避峰定价本身并不罕见,就像我们最熟悉的避峰电费一样,在不同时期的用电价格也会有很大的差价。
为了尽可能避免用电高峰期用电紧张,用电低谷时电能闲置,国内设置了峰谷电价,鼓励用户通过峰谷差价错峰用电,帮助用户节约用电成本,挖掘更多的经济效益和环境效益,同时最大限度地配备电网资源。
实际上,DeepSeek 这位官员在新闻稿中也提到了类似的说法,称推出避峰优惠活动是:「鼓励用户充分利用这段时间,享受更加经济流畅的服务体验。」

从开发者的角度来看,这种避峰定价的运营策略几乎可以算是百利而无害。从大型厂商和云计算平台的角度来看,其实利大于弊,可以更大程度的利用服务器资源。
所以现在看来,大模型跟进避峰定价的操作策略应该算是题中应有的意义,只是具体的策略有不同的调整,比如上面提到的不同时区(不同的用户市场)。
不过,DeepSeek 这次会不会引起行业连锁反应,甚至是一年前的大模型价格战?也许还有待观察。
不少关注 AI 有些读者可能还记得2024年。 年 5 月初,大众眼中「没名气」的 DeepSeek 第二代已经发布 MoE 大模型 DeepSeek-V2首次引入双头潜在注意力。(MLA)机制,拥有 2360 十亿参数,每一个 token210 亿次活跃参数,堪称当时最强的开源参数。 MoE 模型。

DeepSeek V2 图/雷科技技术论文摘要
但是更重要的是,DeepSeek-V2 价格达到:输入 1 元 / 百万 tokens、导出 2 元 / 百万 tokens。
如今看上去也许并不太惊艳,但是这个价格,只是当时。 ChatGPT 主力模型 GPT-4 Turbo 近百分之一,就性价比而言,直接秒杀了国内外众多的大模型,也让很多人记住了这个名字。「DeepSeek(深度追求)」大型模型制造商,并冠于「AI 界拼多多」的称号。
更加令人印象深刻的是,DeepSeek-V2 此后,中国大模型价格战触发,字节、腾讯、百度、阿里等大厂商纷纷降价,通义千问对比。 GPT-4 的主力模型 Qwen-Long,API 甚至是从输入价格 20 元 / 百万 tokens 降到 0.5 元 / 百万 tokens。
「避峰定价」可能很难独立推进运营策略,但是考虑到 DeepSeek 在开源周展示一系列能力,如长上下文的突破,芯片应用效率的提高等。,可能不是大模型价格战的又一轮。「新开始」。
写在最后
DeepSeek 毫无疑问,今年以来 AI 业内最大的鲶鱼,行业领导者 OpenAI 还被迫做出许多回应。据多家媒体报道,OpenAI 最近计划推出「酝酿已久」的 GPT-4.5。
自然,其它大型厂商的追逐甚至超越,也在倒逼。 DeepSeek 加快节奏。根据美联社的最新报道,新一代 R2 推理模型的确要来了,DeepSeek 计划要在 5 每月推出,但是最近一直在考虑提前推出。
所有这些变化都在推动 AI 迭代与进步,也在改变今天的世界。
这篇文章来自“雷科技”,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com