
使用大模型,阴谋论无效!最新的MIT研究








“兔子洞”的阴谋论, AI 破解了!
MIT最新的研究已经登上Science 封面:与 AI 对话,有利于持续减少阴谋论的影响。
结果表明,大模型反驳阴谋论。准确性极高!
对专业事实核查员进行评估,99.2%所有的反驳内容都被认定为真实信息,只有0.8%存在一定的误导性,并且整体上没有任何虚假信息和偏见。

研究成果一经公布,就备受关注,但是人们对此非常关注。 AI 破解阴谋论的态度褒贬不一。
有些人认为这是人类抵抗错误思维的杰出工具。

还有人说,放到现实中,这一切都不成立。由于她身边的阴谋论者都非常抗拒使用。 AI 即使他们使用了工具 AI 也不会相信他给出的答案。
但是,更多的人仍然对这一研究成果持乐观态度。

关于结果到底是什么,我们来看看吧!
“兔子洞”成功破解
在实验中,科研人员各自招聘 1055 人进行治疗组试验,以及 2286 人进行对照组试验。
其中,治疗组要求参与者和参与者 AI 进行对话,讨论他们所选择的阴谋论,而对照组则与对照组进行对话, AI 讨论一个无关紧要的话题。
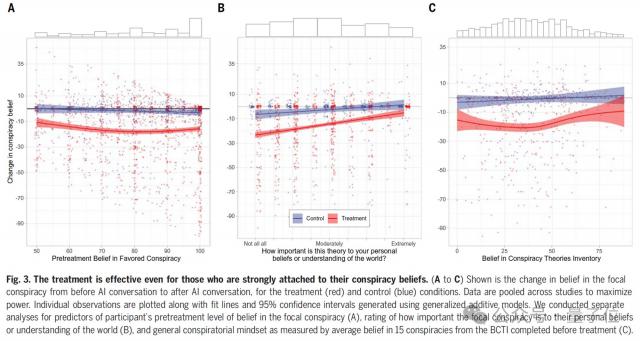
最终实验数据显示,治疗组的阴谋论信念平均值降低了约 20%,而且对照组几乎没有变化。
这一效果在 2 在过去的几个月里,它仍然存在,并且对各种阴谋论产生了普遍的影响。

即使是对初始信念根深蒂固的参与者也是如此。
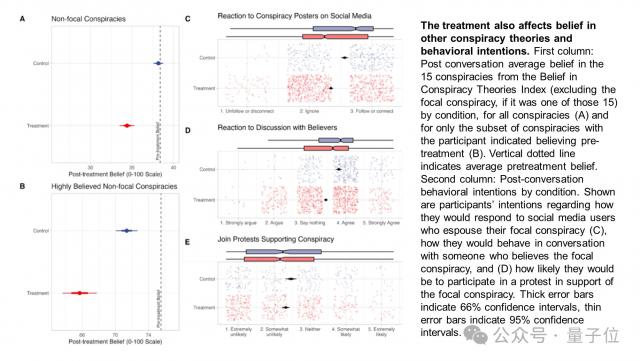
实验还会影响参与者的后续行为。(例如,他们将关闭那些在社交平台上传播阴谋论的博主)
这个团队的研究人员更是发文感慨:
在陷入阴谋论之后,需求和动机并不会完全使你失去理智,只需要详细而量身定制的证据就能帮助你回归现实。干涉是合理的!

如何破解?
既然"干涉是合理的",那么,让我们一起来聊聊实验中是怎样进行“干涉”的。
在实验中,研究人员首先要求参与者完成包括在内的工作15 个阴谋论信念量表, 0-100 对他们的初始信念进行评分。
并要求他们描述一个他们相信的阴谋论,并提供相关证据。(用于生成 AI 对话的初始摘要)
之后,他们被分配到“治疗组”和“对照组”进行实验。
在此期间,他们将与基础相结合GPT-4 Turbo模型进行三轮对话,平均对话值持续。 8.4 分钟。

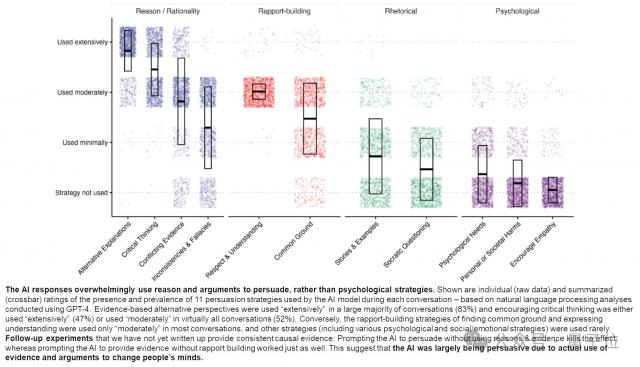
实验中,AI 其目的是反驳参与者提供的具体证据,并试图降低他们对阴谋论的信念。
谈话结束后,所有参与者都需要重新测试他们对上述阴谋论的信仰水平,等级范围仍然是 0-100,用于评估干涉效果。
以后的10 天和2 个月在此期间,研究人员再次与参与者联系,对信念程度进行跟踪测量,从而评估信念变化的持久性。
另外,研究小组通过不断优化问卷措辞,在二轮试验中成功验证了研究结果的稳定性。
看到实验过程后,我们再来谈谈这个实验的问题。创新之处:
第一,利用实时互动方式进行研究,AI 这种方法比传统的静态问卷或预置干涉更灵活、更有目的,可以根据参与者的具体证据和反驳灵活地调整论点和策略。
第二,研究提出了行为科学与生成式相结合的新试验范式。 AI 优点,促使研究者能够实时获得参与者的信念解释,并将其转化为定量结果。
不过 AI 虽然很好,但是不要贪吃,毕竟,"水能载舟也可以覆舟"。
正如研究人员所说:
如果没有保障措施,语言模型也会使人们相信阴谋论或其它虚假信息。
尽管如此,他还是热情地把相关的链接发给大家去测试。
试玩链接已另附,有兴趣的朋友可以观看一下。 ~
试玩链接:
https://www.debunkbot.com/
参考链接:
[ 1 ] https://www.science.org/doi/10.1126/science.adq1814
[ 2 ] https://www.science.org/doi/10.1126/science.ads0433
[ 3 ] https://www.science.org/doi/10.1126/science.adt0007
[ 4 ] https://x.com/DG_Rand/status/1834291074480660560
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com