
国产AI卷翻硅谷,奥特曼发文“阴阳”,类o1模型都在卷什么?








两种国产推理模式的发布,让全球AI圈“提前过年”。
日前,月之暗面推出Kimimi k1.DeepSeek还发布了DeepSeek-R1文本推理模型,两者都在推理能力上对标OpenAI正式版o1。
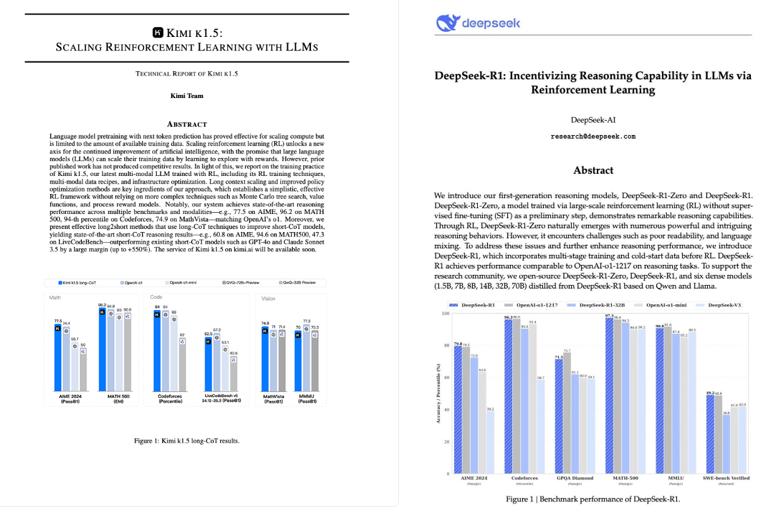
在不到2个月的时间里,国产推理模型完成了OpenAI。 与OpenAI遮盖的技术秘诀不同,o1满血版(2024年12月上线)的对比,两家中国企业都公开了自己的特色技术原则:DeepSeek R1具有很高的性价比,kimi k1.long2short原创技术 高效思维链 原始多模态。
所以Kimi/DeepSeek一夜之间,“双子星”卷翻硅谷,技术报告paper一发布,就引起了大批国内外同行的关注和解读,在github的人气飙升。
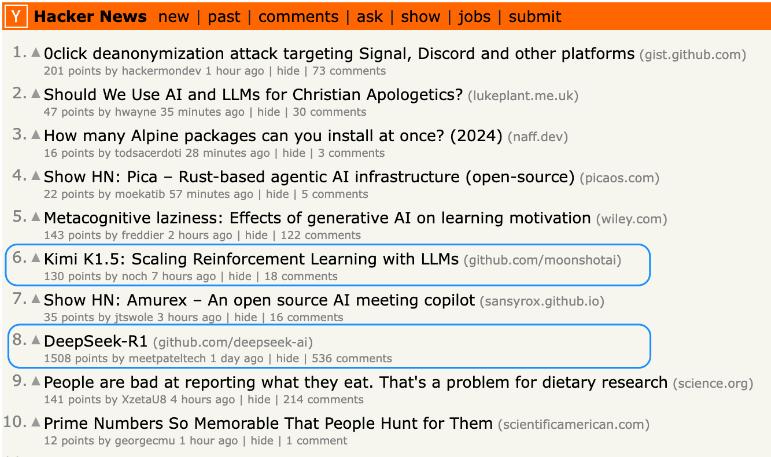
现在,海外同行的反馈主要是兴奋。比如保罗·库弗特,Answera公司的创始人。(Paul Couvert)感觉,两个中国o1同日发布,(中国AI)追逐速度越来越快!
“泼冷水”当然也是不可或缺的。
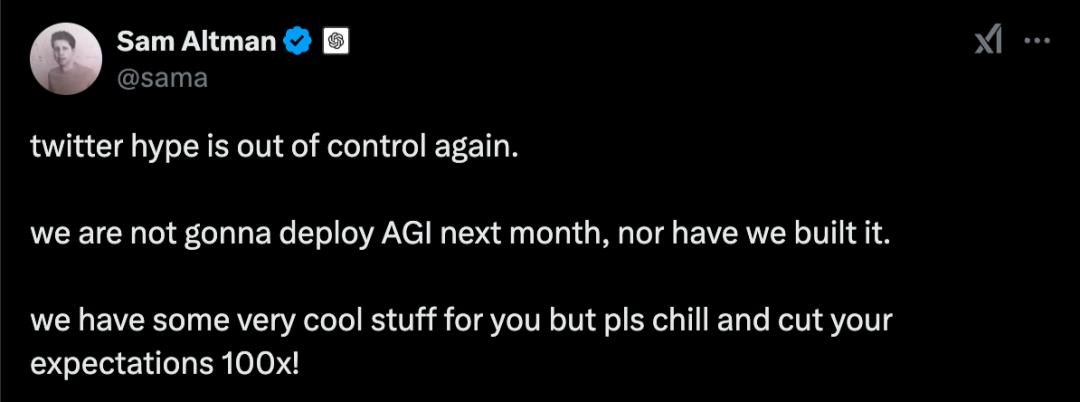
OpenAI 在社交媒体上,CEO奥特曼说:twitter hype is out of control"(推特上的各种炒作已失控)。“AI将取代大多数中层职位”(主要依靠推理模式),他认为外界猜测过于夸张。但愿每个人都能冷静下来,把期望降低100倍(cut your expectations 100x)。
有些人可能会好奇,国产推理模式真的崛起了吗?大模型技术如何从“规模扩展”发展到“推理扩展”?我们应该保持兴奋还是冷静推理模型的路线?本文将逐一解读。
国产推理模式, 为什么这次炸场硅谷?
中国AI企业的两种新模式,引起了全球国内外同行的高度重视。理由很简单,推理模式太火了。
reasoning出现在2024年第四季度。 Model的新形态LLM,选择思维链进行“慢思维”,在推理阶段投入更多的计算(推理拓展思路),这种创新能给大模型带来超前推理能力,可以减少幻觉,提高可靠性,处理更复杂的任务,达到人类专家/研究生的智能水平,它被称为规模扩展Scaling 最具潜力的新技术是Law碰墙。
o1系列之后,头模厂开始投资“慢思维”的推理模型技术路线,包括谷歌、百度、阿里、科大讯飞、夸克、AI六虎中的智谱。DeepSeek、阶跃星辰等,之前也都推出了准o1的推理模式,但是一直没有完全对标正式版o1的国产推理模式。
为了证明国内推理模式的兴起,有两个前提条件:第一,经得起全球同行的审视;第二,具有原创性而非简单跟随,全面对标而非部分达标。
目前来看,Kimi k1.5/ DeepSeeK R1符合上述条件。
Kimi k1.5/ DeepSeeK R1首次真正对比了正式版o1,获得了SOTA成绩。其中,k1.在支持文字和图像推理的同时,也是国内第一个多模态o1。它在全球推理模型领域都取得了很大的成就。
而且,与OpenAI不同。 Kimi和DeepSeeK都发布了详细的技术报告,分享了模型训练技术的探索经验,并立即在国外AI圈掀起了解读论文的热潮。
举例来说,英伟达的研究科学家第一时间开扒,得出Kimi和DeepSeeK的研究“令人兴奋”的结论。

作为当前AI领域最主流的叙事和技术高地,推理模型的动作会引起全世界从业者的关注。然而,中国企业在推理模型跑道上一口气拿出了两篇含金量高的重磅论文,经历了专注和严格的审查,其中包含了许多原创技术。
从Kimi可以说 k1.5/ DeepSeeK R1的“双子星”开始了,国内的推理模式真的崛起了。
中国原创AI,点亮推理扩展的技术版图
推理模型,国内AI公司是怎样追求的?与海外AI圈一起“黑眼圈熬夜”,努力学习kimi/ 简单总结一下DeepSeek论文:
k1在总路线上.5和R1都使用了强化学习。(RL)提高模型推理能力的技术。但是在技术细节上,kimi/ DeepSeek都想出了一个全新的想法。
DeepSeek没有采用行业内常见的微调监管。(SFT)作为一种冷启动方案,提出了一种多阶段循环的训练方法,利用少量冷启动数据和微调模型作为强化学习的开始,然后通过奖励信号在RL环境中进化自己,达到了非常好的推理效果。
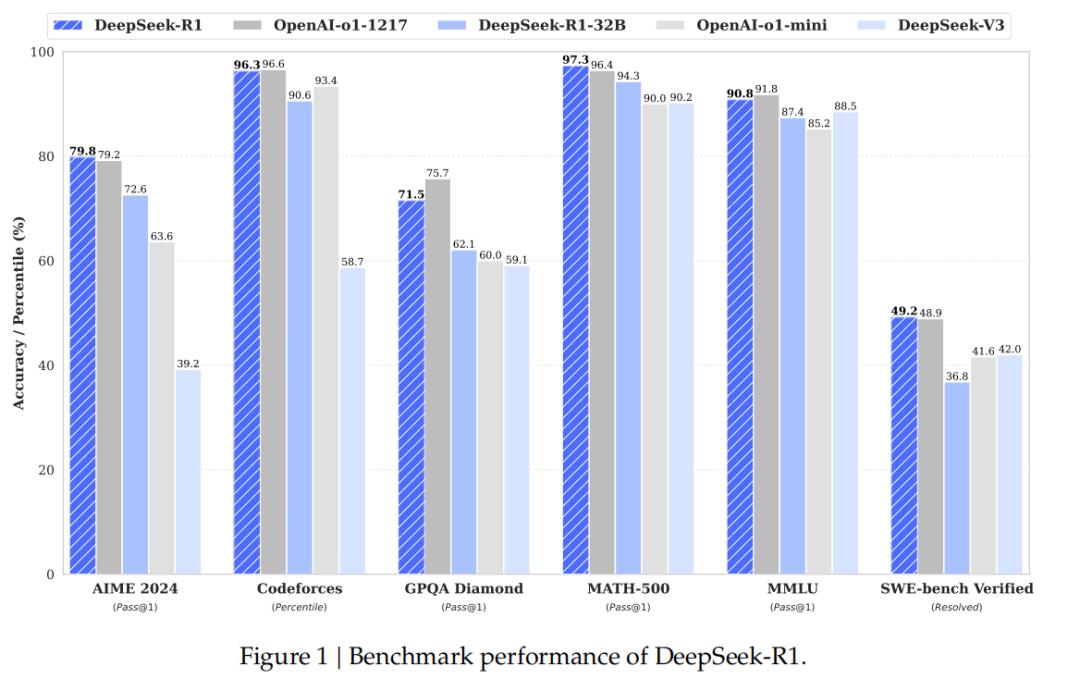
Kimi k1.在long2short思维链中首创5,通过奖励制度,让LLM探索性学习,自主拓展训练数据,扩大前后文章的长度,从而优化RL训练的表现,在短链思维推理方面取得SOTA成绩。
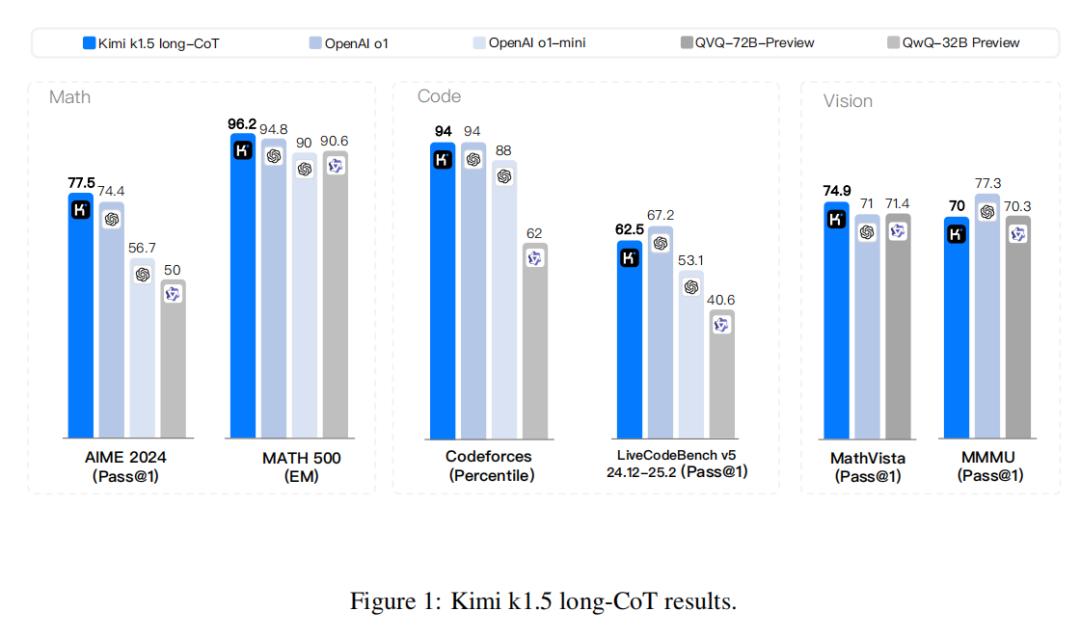
Long-CoT版本Kimimi,性能最强。 k1.数学、代码、多模态推理能力能达到长期思考SOTA模型OpenAI O1官方版本水平。
short基于long-CoT版本的简化。-CoT,性能依然强大,但推理效率更高,大大超越了SOTA模型GPT-4o和Claude的全球范围。 3.5 Sonnet的水平领先550%。
此外,国内两大推理模式也各有亮点。
DeepSeek-R1延续了“AI拼多多”的优秀传统,每百万的API导出tokens 16 人民币,每百万的o1导出tokens。 60美元的定价一比,性价比打满。
Kimi k1.除了OpenAI之外,第一个实现o1多模态推理性能模型,k1.5支持多模式输入的文本、图像重叠,可以进行联合推理,填补国内多模式思维模式的空白。
视觉信息占人类感官的70%以上,具有多模态能力,认识自己的Benchmark图表自然不言而喻。
众所周知,o1是否昂贵(每月订阅费200美元),或者根本不需要(OpenAI不向中国提供服务)。因此,国内推理模式的这些亮点并没有给国内外AI开发者带来太大的价值,很多开发者都深感兴奋。
一位开发者在论坛上表达了自己的感受,这两个中国实验室“用更少的资源做更多的事情,他们非常关注模型的效率和简洁,惠及我们所有人”。

Mark开发者Amarok 在社交平台上,Kretschmann也毫不犹豫地称赞K1.5是“多模态AI领域的重大进步”。
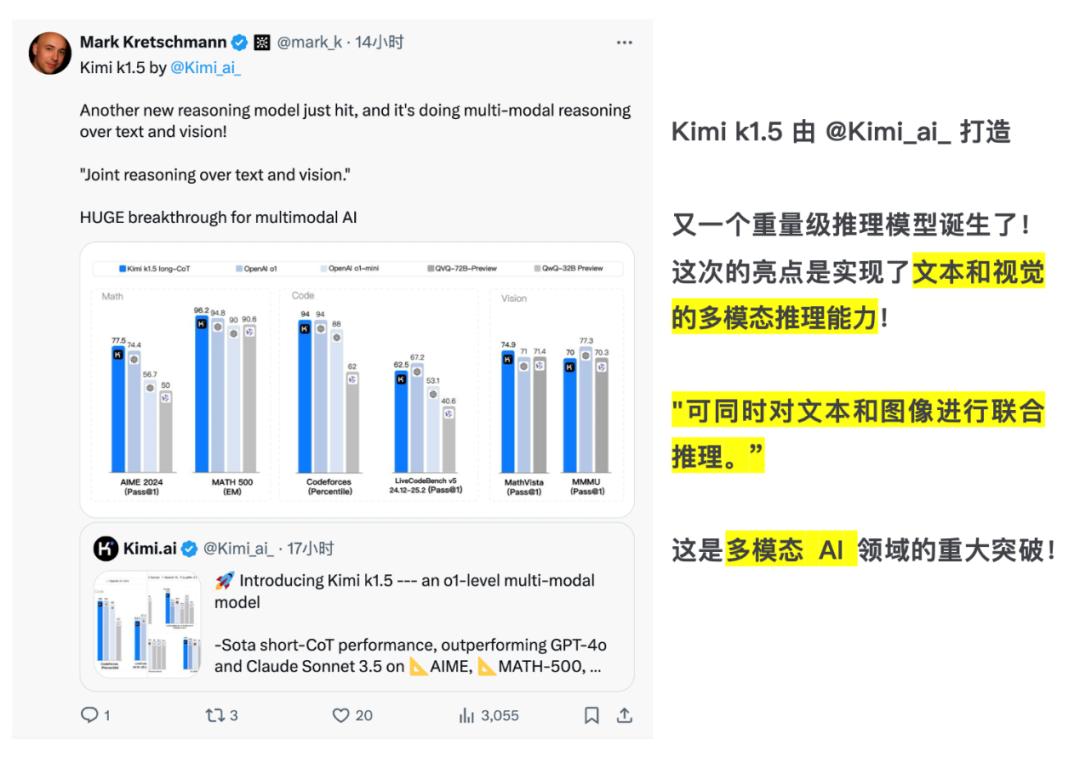
可以看出,面对全新的“推理扩张”技术领域,中国AI“双子星”以其原有的硬实力稳步获胜,走上了与OpenAI不同的发展创新之路。
中国AI,按下推理模型的应用加速键。
OpenAI奥特曼建议大家降低预期,那么,中国AI企业使力推理模型,到底有没有价值,有多大?
对中国AI公司而言,点亮推理模型的技术版图,有两层含义:
第一,仰望星空,可以缩短中美AI的技术距离。领先的大模型不会从天上掉下来,而是努力让中国AI的水平得到快速提升,保持最新的技术路线跟进。与ChatGPT相比,大约需要半年时间,但与正式版o1相比,只需要不到三个月的时间。
以Kimi为例,k0-math数学模型于去年11月推出,k1视觉思维模型于12月推出,k1.5多模态思维模型于今年1月推出,三个月迭代三次,进化速度极快。表明对天花板技术的贴身跟进,是中国AI最快、最好的训练场。

第二,脚踏实地,中国工业沃土为国产AI提供了更广阔的落地场景,推理模型的落地情况要好于o1。海外AI主要是个人客户,o1的主要用例是程序员的代码助手、数据分析师和个人开发者,普通人的入门门槛很高。然而,国内大型模型更多地面向行业场景。AI改造的需求场景包括大量容错率低的严肃生产场景。以前的大语言模型很难解决复杂的任务,需要少幻觉、高可靠的推理模型。因此,国内推理模型的落地可能会更快更广。
从这些角度来看,恐怕国内AI还是会以各行各业引入专家AI的推理模式为榜样,加速行业智能化。k1.5、R1等国产推理模式将为其中不可或缺的基础价值做出贡献。Kimi官方还表示,2025年将继续跟随路线图,加快K系列升级,强化学习模式,带来更多的模式、更多的领域能力和更强的通用能力。
所以不出所料,我们很快就可以用上花钱少、生活好的专家级国产AI了。
2025年中国AI“双子星”大模型开启,特别精彩。推理模型作为模厂的下一个分界点,谁抓住了国产推理模型的崛起时刻,谁就先抓住了未来。
本文来自微信微信官方账号 “脑极体”(ID:作者:藏狐,36氪经授权发布,unity007)。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com