
“卷王”豆包上菜,压力给谁?








大型跑道打了一年的价格战,还在继续…
新年前一天,阿里云宣布2024年第三轮大模型降价,通义千问视觉理解模型全线降价80%以上。
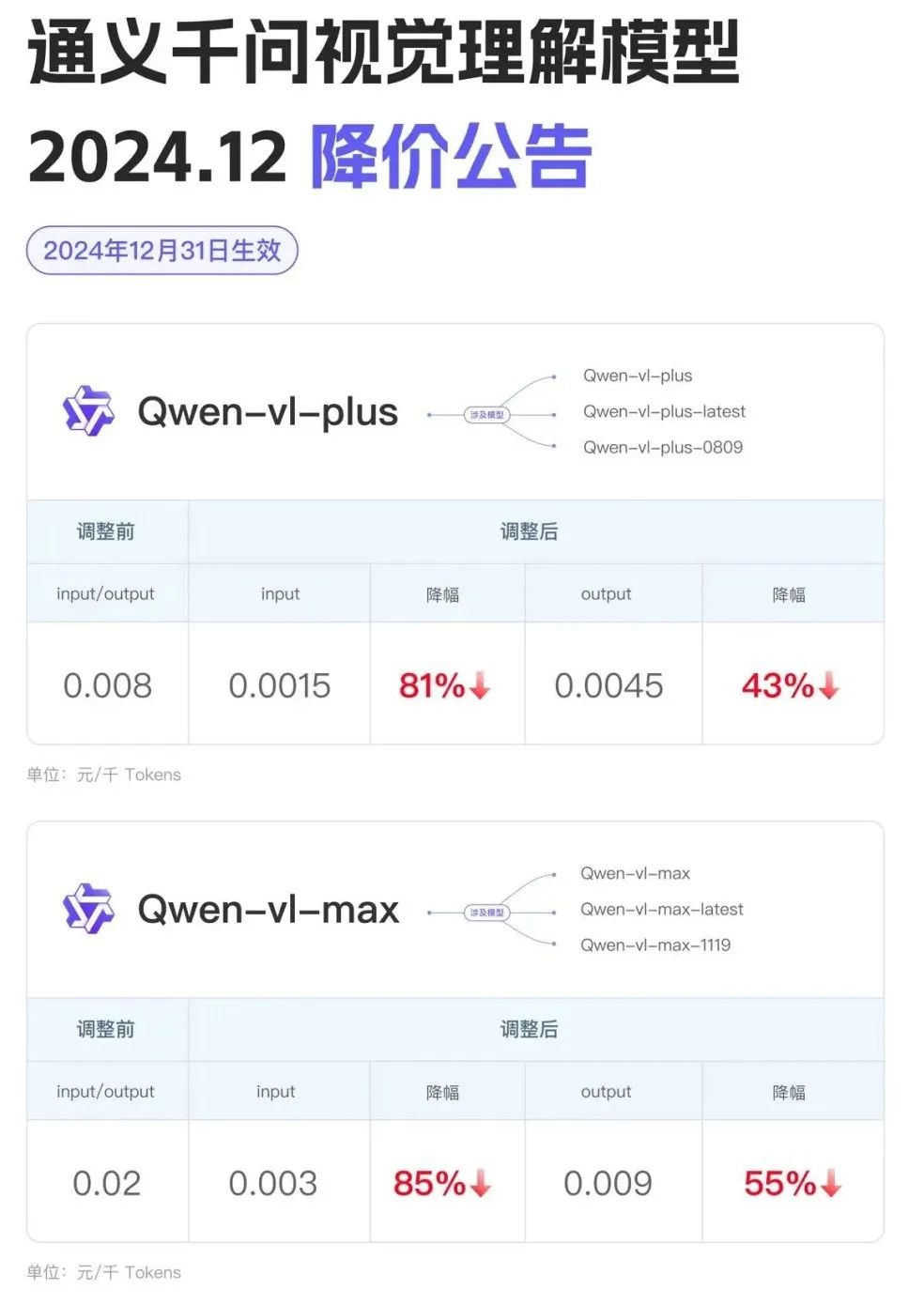
同样,在不久前的火山发动机Force会议上,除了大力宣传豆包外,最值得关注的还是价格再次下跌。现在豆包视觉理解模型的输入价格是0.003元/千tokens,1元可以处理284张720P照片。
去年5月,豆包通用模型pro-32k版,推理输入价格为0.0008元/千tokens,价格不到1厘米。这一举动迫使阿里云在新一轮降低了三款通义千问核心模型的价格,降幅高达90%。百度智能云更加激进,宣布文心大模型旗下的两款主要产品——ENIRE Speed和ENIRE Lite,全面免费开放。
根据火山发动机总裁谭待的说法,“市场需要充分竞争,降低成本是技术优化的结果,最好是生存”。显然,在这场大型军备竞赛中,豆包想上演一出“大力创造奇迹”的戏码。
然而,在字节的大卷下,也有不断的质疑:豆包的价格真的够便宜吗?为什么大模型要卷价?未来价格会成为企业下单的重点吗?
01 减价夸张?充满了招数
要了解大型商业模式,就必须了解大型商业模式。根据“远川科技评论” "整理,目前各家提供的服务主要可以分为三类:
第一,包括模型推理的基本服务,是指根据输入的信息内容给出答案的过程。简单来说,就是“实际应用”模型的过程。这部分每个家庭都有不同的模型标准。
第二,模型调整得很好,制造商可以根据客户需求使用token(训练文本)*训练迭代次数)收费,训练结束后付款,按量付款。
第三种是模型部署,相当于一个客户垄断了一部分计算率资源,属于大客户。它的收费模式也是根据消耗的计算资源或模型推理的token数量来计算的。
这三种收费模式也代表了大模型开发的循序渐进过程。其实各大科技公司疯狂讨价还价的是第一个基础服务,也就是专业版模型推理费。这部分定价分为“输入”和“导出”两部分。简单来说,输入就是用户提问的内容,导出就是大模型的答案。
通常情况下,在调用大型模型时,会根据输入输出的token数量进行双向收费。这一小小的差别,很容易成为大型企业的套路。
例如,Doubaoubao是豆包的通用模型。 Pro-32k,输入价为“0.8元/百万tokens”,官方表示比行业便宜99.3%,一些主流模式也开始降价,比如阿里云三款通义千问主力模式Qwen-Turbo的价格比以前大幅下降85%,低至百万tokens。 0.3元,Qwen-Plus和Qwen-Max的输入价格分别降低了80%和50%,分别是0.8元/百万tokens和20元/百万tokens。
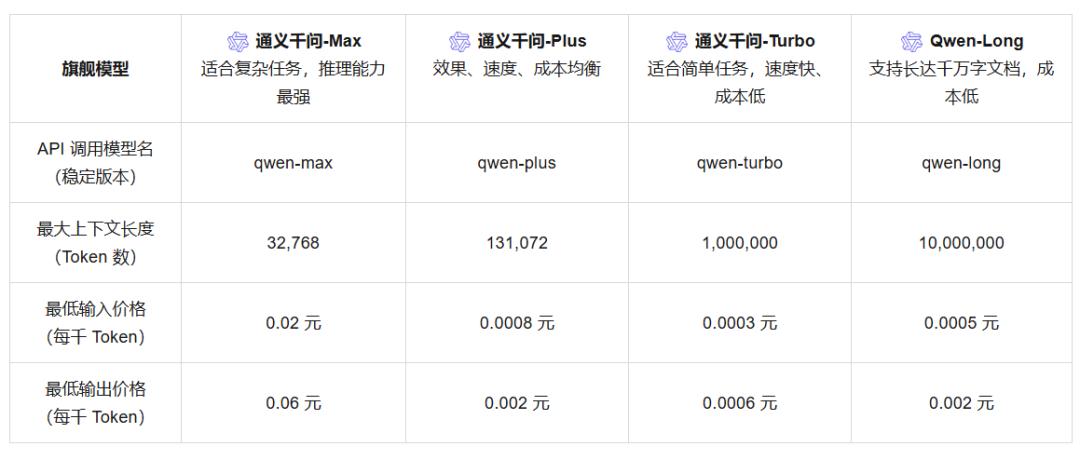
但是导出价格是不一样的,2元/百万tokens的价格和Qwene-Plus、DeepSeek-与Qwen相比,V2等同行持平,甚至比较-Turbo、GLM-一些同行的商品,比如4-9B,价格更高。
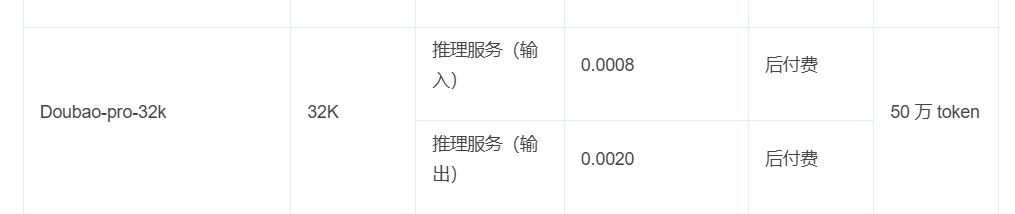
再次查看最新的豆包视觉理解模型Doubao-vision-pro-32k,输入化为每百万tokens的价格为3元,大约是0.4美元,直接导出到9元,大约是1.23美元。根据豆包的说法,这个价格比行业平均价格便宜85美元%。
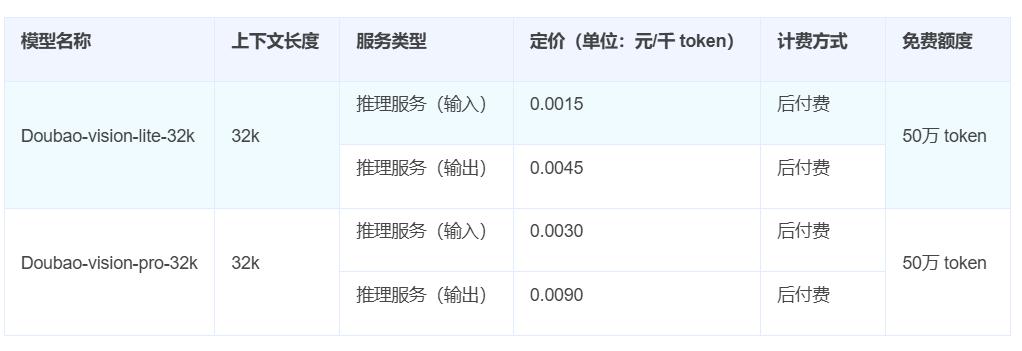
但是对比几个直接竞争对手:阿里的多模态模型Qwen-VL系列在最近降价后与其价格一致;Geminini多模态 1.5 每百万输入tokens的Flash模型报价为0.0755。 每百万美元导出的tokens费用为0.3美元,对较小的前后文(低于128k)还有其他折扣价格;GPT-4o mini输入0.15美元,导出0.6美元。
然而,不仅是豆包,国内其他厂商基本上也有类似的降价“招数”。例如,百度宣布免费ERNIE-Speed-8K,如果实际安排,费用将变成5元/百万tokens。还有阿里的Qwen。-Max,实际上,豆包通用模型Pro-32k与字节跳动相同,只是降低了输入价格。
值得一提的是,标准模型推理的降价确实可以降低中小开发者的成本,但只要进一步使用,就涉及到模型的微调和模型的部署。但是这两项服务从来都不是价格战的主角,降价幅度也不大。
简单来说,每个家庭最难降价的其实就是轻量级的预设模式;相比之下,性能更强的“超大杯”模式实际降价幅度并没有那么夸张。比如精品Doubao-pro系列的价格是50元/百万tokens,比阿里、腾讯等厂商的主要旗舰模式还要贵。
各大厂商掀起的价格战,就像打网游一样,以各种形式吸引玩家,在游戏中加入各种玩法。反正想变强就需要氪金。当然,即便如此,每一个大厂商都付出了很多真金白银,那么为什么这些厂商总是在价格上下功夫呢?
02 要做好,热度不能停止
纵观大模型行业,字节跳动不可能是起步最快的玩家。甚至今年年初,字节跳动CEO梁汝波在内部演讲中指出了“缓慢”二字,直接指出字节对大模型不如创业公司敏感。
“GPT直到2023年才开始讨论,2018年至2021年创办了行业内做得不错的大型创业公司。”他说。
后来者往往是最需要内卷的人,字节跳动也是如此。从今年年中开始,一轮又一轮的热度开始产生。
除上面提到的豆包在B端有明显的降价意图外,C端市场豆包也是全力出击。
面向C端,无论是线上平台,还是线下公共场所,都可以看到豆包。根据“Insight连线”的说法 引用AppGrowing统计,截至11月15日,Kimi和豆包是国内十款AI原生应用中最疯狂的两款产品,分别投入5.4亿元和4亿元。
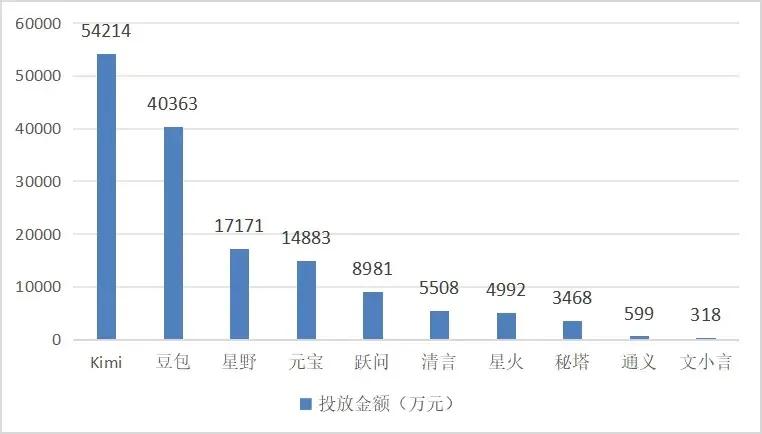
从时间线来看,豆包的投流显然更加强烈。根据AppGrowing的统计,2024年4-5月,豆包投放额度预计为1500万-1750万元。六月初,豆包再次推出新一轮大规模的广告投放活动,投放额达到1.24亿元。
除了流量,豆包还有抖音的流量池,字节几乎屏蔽了除了豆包之外所有AI应用于抖音的流量池。目的也很明确,就是彻底解决大模型使用的“客户焦虑”。
然而,现实往往适得其反。据“智能出现”报道,字节内部反思——豆包目前的用户活跃度不高。豆包一周只活跃2到3天,客户每天只发消息5到6次,一次2分钟,客户人均使用时间只有10分钟。这些信息在过去一年中的增长并不明显。
简单来说,尽管豆包已经成为国内用户数量第一的AI软件,但它仍然不是killer。 app。
字节管理层对此的判断是,像豆包这样的AI对话产品可能只是AI产品的“中间状态”。从字节内部判断,付费订阅模式在中国不太可能通过。但时长和轮数太低,导致隐藏广告空间小,形成了这类产品的隐形天花板。
所以从长远来看,门槛更低、模式更“多”的产品形式更有可能落地,剪影和即梦可能是一个合适的入口,这也是豆包把一些重点放在视频模型上的本质原因。
但从用户的角度来看,据《财经杂志》报道,大多数用户支付的原因是产品和服务可以带来价值。价值不仅仅是为了解决实际问题,比如提高工作效率,提供情感陪伴。市场上还有一种价值是“符合政策方向”。更重要的是要有能力找到具体的客户并交付,这考验的是AI企业除了技术和产品之外的能力。甚至在很多情况下,这种能力比技术水平更能帮助AI公司成长。
与美国不同,中国的AI市场很难通过平台销售软件打开市场。很多时候,我们需要抓住每一个项目和项目来实现商业化。这些项目和项目的来源通常与自身的受欢迎程度有关。
“一个完美的企业在布局一个大模型时,很难考虑一个不成熟的产品或企业。大品牌通常是不考虑成本的首选,这不仅是技术上的信任,也是服务和质量水平的认可。”一位科技企业经理向「科技新知」说:“毕竟小厂的风险还是有的,就像买车一样,开着车厂倒闭,那么损失就大了。”
创业公司制造热门新闻的概率很大,是为了融资和生存。但是豆包有背景,想靠热度找到更多的客户,固定更多的客户。然而,圈子里的一个默认事实是,无论是谁,无论技术有多强大,他们都应该善于保持热度。毕竟好酒怕巷子深。
03 淘汰赛,或者告别价格战
其实不仅仅是豆包。目前市场上所有二线及以下大型厂商为了留住用户,都处于花钱买流量的阶段。因为这场名副其实的“卷王秀”背后是疯狂的产品能力和R&D速度,也意味着这场关于“挤泡沫”的大型服务商淘汰赛再次吹响了号角。
2024年,经过一轮淘汰赛的训练,大模型可以九存一,产业格局更加合理,进入决赛圈的大模型只有10%左右。
不过,这并非终点,而是开始。只是「科技新知」看起来,新一轮淘汰赛的重点,价格不再是主导因素,而是技术。
目前,科技公司已经开始意识到,仅仅发布一个免费应用并不能给公司带来直接利润。C端用户数量难以增加,推广成本明显增加。更重要的是,直接接触那些愿意付费的B 终端客户,如金融、政务、汽车等领域。
然而,当大量企业集中进入某个行业时,通常会有长期的价格战,因为每个家庭都需要建立一个标杆客户来为未来的市场发展铺平道路。简单粗暴的价格战会让一些公司主动或被动撤出,然后在市场稳定后恢复正常价格。
但不同的是,每个人都想进入“富裕”的行业。在长期的价格战下,技术成本成为取胜的关键。简单来说,在同样的解决方案和价格下,谁的技术成本低,谁就能损失更少,活得更久。
技术成本取决于公司的硬件成本和算法逻辑,目前国内主流大模型厂商基本处于同一水平,迭代和相互追逐的速度相当,但这并不意味着他们可以无忧无虑。
今年9月,OpenAI“王炸”o1模型的出现也让每个家庭看到了差距。与现有的大型模型相比,o1最大的特点是“推理AI”,在回答复杂问题时会花更多的时间逐渐演绎问题。这种延迟思维不是缺陷,而是让o1更接近人类真实的逻辑判断。
o1的推出意味着AI已经进入了一个全新的阶段,从“生成式AI”到“推理式AI”。更令人震惊的是,o1发布3个月后,o3出现了下一代o系列产品,o3有完整版和mini版。新功能是将模型推理时间设置为低、中、高。模型的思维时间越高,效果越好。更加精简的mini版本,对特定任务进行了微调,将于1月底推出,之后不久将推出o3完整版本。

它还意味着,在快速迭代下,目前主流的生成式AI,即将成为历史商品。
"价格是影响大型企业的因素,但更重要的是技术能力,"一个大型应用程序开发者向「科技新知」他说:“目前我国如阿里、昆仑万维等公司也都推出了类o1模式,虽然存在差距,但也代表着他们都认同这种趋势。”
一位业内人士还表示,国内公司的思路是整合思维链,通过搜索提高深度推理能力,加入反思方案和算法来提高逻辑判断性能,但目前还没有完全超越OpenAI。
值得注意的是,DeepSeek-V3是国内最近比较流行的一种蒸馏技术,它为行业提供了新的思路,但同时也引发了“GPT升级”的争论。
对于可能使用生成数据(大模型生成数据)进行AI培训的话题,伦敦大学学院(UCL)名誉教授和计算机科学家彼得·本特利表示担忧,称“如果你一直在其他AI输出方面训练AI,结果可能是模型崩溃。保证高质量AI的唯一方法就是为它提供人类高质量的内容。”
该专家补充道:“缺乏参考现成的开源架构,不清楚o1模型在后续培训中加强学习形式和使用的数据集。树木搜索和COT没有开源,难以培养数据污染和提高国产模型的推理性能。这些都是目前国内企业的难点。”但是,如果出现支持o1架构的开源模型,这个过程会加快。在这个过程中,两三个会先跑,其他会跟进。”
如果按照以往GPT系列的发展节奏,2025年上半年全厂商很有可能会跟上O系列的步伐,之后,目前的技术会逐渐退出历史舞台。所以对于大型厂商来说,最好让迭代技术在淘汰前发挥更大的作用,而不是等待被淘汰。
总的来说,虽然未来价格仍将是影响企业订单的因素之一,但随着技术的快速迭代和行业的发展,技术能力将变得越来越关键。只有不断提高技术,降低成本,提高服务,大型厂商才能在即将到来的淘汰赛中生存。
参考资料:
[1]“豆包再次降价,字节“饱和”进攻仍在继续”, Insight连接
[2]远川科技评论《大模型价格战,还可以再狠一点》
[3]“中国大模型洗牌年即将开始,隐藏两大逻辑”,财经
[4]“字节内部判断AI对话产品的天花板可能不高,提高剪影即梦的优先级”,智能涌现
本文来自微信微信官方账号“科技新知识”(ID:kejixinzhi),作者:思原,编辑:蕨影,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com