
谷歌 DeepMind 提升 AI 模型新思路,计算效率和推理能力兼顾






IT 世家 12 月 28 日消息,谷歌 DeepMind 该团队最近推出了“可微缓存增强”(Differentiable Cache Augmentation)的新方法,可以显著提高大语言模型的推理性能,而不会明显增加额外的计算负担。
项目背景
IT 世家注:在语言处理、数学和推理领域,大型语言模型(LLMs)它是解决复杂问题不可缺少的一部分。
增强计算技术偏重于使计算技术 LLMs 它能更有效地处理数据,产生更准确的响应,并与上下文相关。随着这些模型的复杂性,研究人员努力开发一种在固定计算预算中运行而不牺牲特性的方法。
提升 LLMs 其中一个主要挑战是,它们不能有效地跨越多个任务进行推理或超越预训练结构的计算。
目前提高模型特性的方法涉及任务处理过程中产生的中间步骤,但代价是延迟增加,计算效率低下。这种限制阻碍了他们执行复杂推理任务的能力,尤其是那些需要更长时间依赖或更高准确性的任务。
项目简介
“可微缓存增强”(Differentiable Cache Augmentation)选择一台训练有素的协处理器,通过潜在的嵌入来提高。 LLM 的键值(kv)缓存,丰富模型内部记忆,关键在于保持基础。 LLM 同时对异步运行的协处理器进行冻结训练。
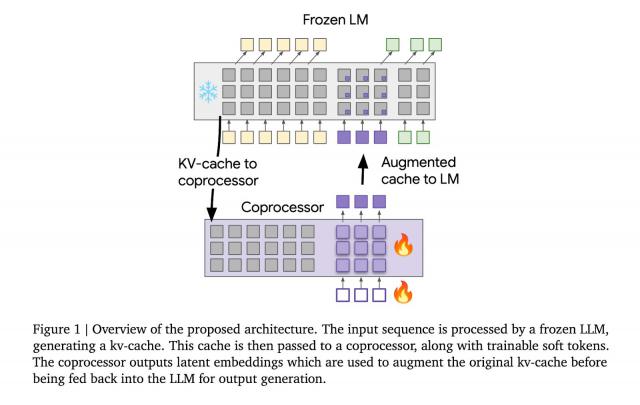
整个过程分为 3 每个阶段,冻结 LLM 产生输入序列 kv 缓存;协处理器使用可训练软令牌处理 kv 缓存,产生潜在嵌入;强化的 kv 缓存反馈到 LLM,产生更丰富的导出。
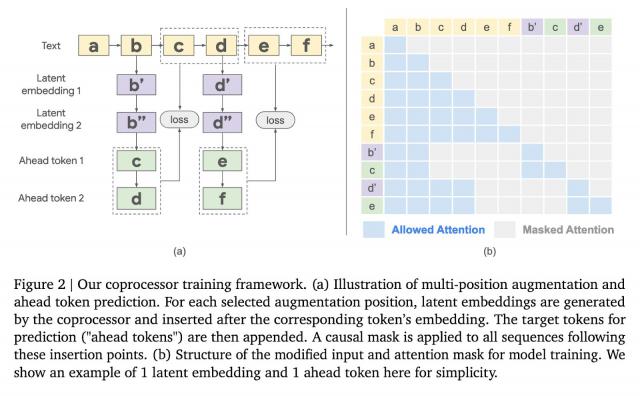
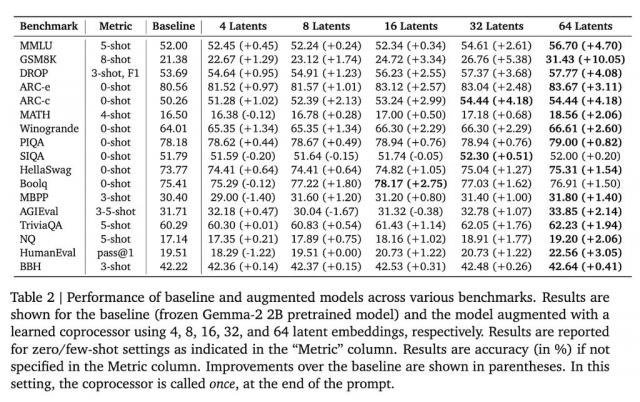
在 Gemma-2 2B 在模型上进行测试,这种方法在多个基准测试中取得了显著的效果。例如, GSM8K 在数据方面,精度提高了。 10.05%;在 MMLU 上,性能提高了 4.70%。另外,这种方法也减少了模型在多个标记位置的混乱。
谷歌 DeepMind 这项研究是为了加强 LLMs 推理能力提供了新的想法。通过引入外部协处理器来增强 kv 缓存,研究者在维持计算效率的同时,显著提高了模型性能, LLMs 更复杂的任务处理铺平了道路。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com