
英伟达的机器人新魔咒:一个指令让双足机器人“自由行动”




近日,加州大学科研人员和英伟达在联合发表的新文章中提出NaVILA模型的关键创新在于,机器人只需“了解”人类的自然语言指令,结合实时视觉图像和激光雷达信息,就可以自主导航到指定位置,而无需事先的地图。
想像一下这样的场景:你早晨醒来,家里的智能机器人正在等待你的指令。
你们轻声说:“去厨房,拿一瓶水过来。” 不到一分钟,机器人就小心翼翼地穿过客厅,避开沙发、宠物和玩具,稳稳地站在冰箱前,打开冰箱门,拿出一瓶矿泉水,轻轻地送到你手里。
这个场景曾经只出现在科幻电影中,而现在,归功于NaVILA模型的出现,这正成为现实。
NaVILA不仅摆脱了对地图的依赖,而且进一步将导航技术从轮试扩展到腿部机器人,使机器人在更复杂的场景中具有跨越障碍和自适应路径规划的能力。
在文章中,加州大学的研究人员使用宇树Go2机器狗和G1人形机器人进行了实际测量。根据团队统计的实际测量结论,NaVILA的导航成功率在生活、户外、工作区域等真实环境中高达88%,在复杂任务中高达75%。
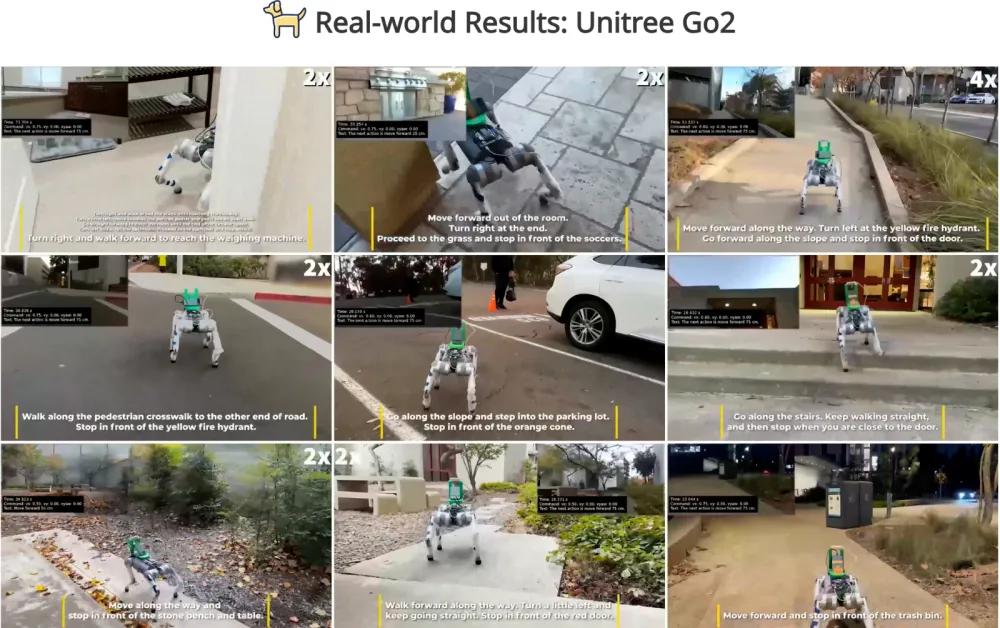

(使用NaVILA测量机器狗和机器人听取指令)
这项研究创新了机器人导航范式,使机器人的路径规划从“地图依赖”向“即时感知”转变。那NaVILA采用了哪些技术原理呢?这会给机器人带来什么新的能力?
提出“中间指令机制”,机器人可自行拆解指令。
机器人需要依靠激光雷达来实现传统的VLN(视觉语言导航系统)(LiDAR)以及SLAM算法绘制和维护静态地图。这种机器人只能在已知的环境中运行,无论是家用扫地机器人还是储存中的AGV汽车。
一旦面临动态环境,如宠物在家行走、更换储物架等场景,静态地图的效用将大大削弱,机器人必须频繁重绘地图,这将增加系统成本和计算负担。
但是NaVILA不同,它可以实现“无图导航”。
高层控制器(视觉-语言-行动-行动)主要由两个机制完成。(VLA)模型),一种是低层控制器。
就高层控制器而言,NaVILA 通过视觉-语言-行动(VLA)模型可以实现“无图导航”,即机器人可以通过视觉图像、激光雷达和自然语言的多模态输入,即即时感知环境中的路径、障碍物和动态目标。
这种视觉-语言-行动(VLA)模型分为三个工作流程:
● 输入阶段:机器人会接收自然语言的指令和摄像头的图像,结合人类的语言信息和摄像头看到的场景,识别路径中的关键目标,如前墙、左障碍物、右楼梯等。;
● 生成中间指令:生成一个“路径规划表”,VLA将在中间生成一系列高层动作指令,这些指令可能是“前进50厘米”、向左转90度”、类似于“简化路径操作说明书”等“跨越障碍物”;
● 高频率控制器调用,其任务是实时控制每个关节的运动。
这个工作流程中,NaVILA最大的亮点是提出了一种“中间指令机制”,这种机制使机器人不需要“死记硬背”每个关节的动作,而是像人类一样,在理解高层的指令后,将其拆解成具体的动作。
“中间指令机制”可以让机器人理解客户的日常交流语言,不同类型的机器人可以根据自己的“身体结构”完成动作。
一般来说,传统的导航机器人就像一个“机械搬运工”。每次你都要告诉它“先抬左腿,再抬右腿,再往前走5厘米”。这种控制方法非常繁琐。
而且NaVILA的VLA模型更像是一个懂事的助手,你只需说“向前走50厘米”,它也会自己拆解成“抬左腿、抬右腿、移重心”等动作。
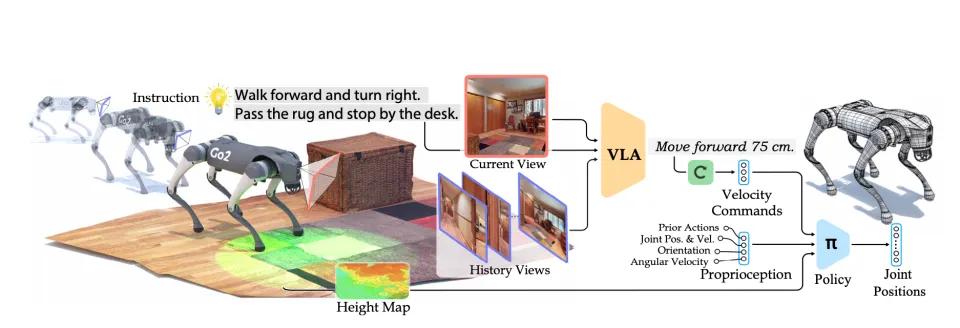
(NaVILA是将高级视觉语言理解与低级运动控制相结合的二级框架)
高层控制器(VLA)它为机器人生成了一个路径规划表,但是“路径规划表”只能告诉机器人去哪里,而不能告诉它怎么去。
此时需要一台“低层控制器”来接手,控制机器人的特定关节动作。
假设你让一个孩子学会走路,如果你只对他说“去客厅”,他会问你“怎么走?怎样迈步?先走左腿还是右腿?” 在这一幕中,VLA就像是父母的语音命令(“去客厅”),而低层控制器就是孩子自己的“肢体控制系统”。它需要控制每只脚的步幅和着陆角度的重心平衡,以确保它不会摔倒。
低层控制器NaVILA 使用了一种强化PPO学习算法,Isaacac通过NVIDIA Sim虚拟模拟平台训练机器人,让机器人学会如何站稳和行走。它的强化学习系统将反复训练机器人在草坪、台阶、楼梯、石地等不同地形行走,并确保机器人不会在这些不规则的环境中摔倒。不是靠计算,而是靠模拟。
NaVILA在高层控制器与底层控制器的联系下,有利于使机器人更加通用。
NaVILA给机器人带来了什么新的可能性?
NaVILA将导航技术从轮式机器人延伸到腿式机器人。
传统的VLN基本上是为轮式机器人设计的。轮式机器人通常在平坦的道路上工作,其导航指令通常是“前进X米,左转X度”。
这类指令适应轮式机器人非常方便,但是腿式机器人需要更细致的控制,因为它们通常要面对更复杂的地形和障碍。
然而,NaVILA的“中间指令”更贴近百姓。用户只需说“去厨房帮我拿瓶水”,机器人就可以理解这个意思,规划路径,做任务,而不是说“前进2米,左转90度”。
另外,使用NaVILA的指令还包含了更具体的动作信息,例如“迈出一小步”、抬腿越过障碍物等等。
这样NaVILA就可以解耦高水平的路径规划和底部的腿部运动,使同一套VLA控制逻辑能够适应不同的机器人平台。
从这个角度来看,NaVILA可以用来控制四足机器人和人形机器人等不同形式的机器人。
工作人员使用NaVILA通过语言顺利指令宇树Go2机器狗和G1人形机器人在论文发布的测试视频中锻炼。
根据实际测量,NaVILA无图导航能力还有助于扩大足式机器人的具体使用场景,以适应人类环境。

(宇树Go2机器狗接受行动指令:向左转一点,向肖像海报走,你会看见一扇开门)

(宇数G1人形机器人接受行动指令:立即左转并直行,踩垫继续前进,直至靠近垃圾箱时停止)
为何如此?因为在传统的VLN系统中,没有地图,机器人无法移动,一旦环境发生变化,机器人就很难处理。
所以,尽管NaVILA没有让机器人“长腿”,但是它让“长腿机器人更聪明”。
以前,足式机器人虽然有“腿”,但每一次驱动它们都需要同时控制膝盖骨、髋关节、脚踝等多个关节。
如果采用传统的控制逻辑进行设计,需要对每个关节进行代码敲击,并不断优化。NaVILA降低了足式机器人的运行成本。
与此同时,这也扩大了机器人的应用场景。
比如在家庭场景中,过去的扫地机器人只能在单个房间里打转,因为它无法跨过几厘米高的门槛。然而,足式机器人可以像人一样一步一步地跨过门槛,走进厨房,给你取一瓶水。当你说“去厨房拿一瓶水”的时候,它不仅能理解,还能绕过宠物,避开家里的玩具,灵活自如地实现目标。
足式机器人在地震废墟中行走在砾石、砾石、钢筋等不规则路面上。在搜索救援和灾后救援场景中,它可以跨越障碍物,爬过砾石,深入废墟深处,帮助搜救人员找到幸存者。NaVILA的“无地图导航”能力也意味着,即使救援环境不断变化,机器人也可以根据实时路径感知自动调整路线。
结语
NaVILA帮助机器人摆脱刻板的地图或复杂的传感器依赖。机器人可以通过语言和视觉的融合,在复杂的环境中找到自己的路,就像人类一样。
尤其对四足机器人而言,NaVILA给它们带来了更多的自由,使足式机器人能够灵活地应对不规则的地形和障碍。
相关资料:
NaVILA: Legged Robot Vision-Language-Action Model for Navigation
本文来自微信微信官方账号“腾讯科技”,作者:周小燕,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com