
曝光OpenAI新旗舰模型“难产”,或者明年年初发布。






随着GPT的放缓,OpenAI撞上了数据墙,试图找到出路。
据Thee报道,智东西11月11日。 据Information报道,OpenAIGPT系列模型的改进速度放缓,公司正在调整策略来应对这一挑战。根据OpenAI员工的说法,下一代旗舰模型Orion已经完成了大约20%的练习。在英语任务方面,Orion表现出色,但是在编码等方面并没有超过GPT-4,而且使用成本更高,增长幅度也低于预期。另外,Orion在明年年初发布的时候,或许不会使用传统的“GPT“命名规范,而是采用新的命名方法。
R&DOrion暴露了高质量文本数据短缺的问题。Scaling 根据Law理论,模型性能应该随着信息量和计算能力的增加而提高。然而,高质量数据的限制限制了Orion的训练效果,限制了Scaling。 Law的适用性受到质疑。即使投入了更多的数据和计算率,模型的提升速度也可能不会像前几代那样显著。
所以OpenAI成立了一个专门的团队,研究如何克服数据短缺的挑战,评估Scaling Law还能适用多长时间?
01.撞上数据墙,Orion在许多方面看起来像旧模型。
根据OpenAI员工的说法,由于高质量文本和其他数据的短缺,GPT改进速度放缓的重要原因。大语言模型(LLM)预训练需要大量的数据来建立模型对世界和概念的理解,以确保它们能够完成写作或编程等任务。然而,随着数据库的日益充分利用,模型的改进面临瓶颈。
为了解决数据不足的问题,OpenAI已经建立了前训练负责人尼克·莱德(Nick Ryder)该团队致力于探索如何克服数据短缺和Scaling 未来Law的适用性。
Orion模型的一些训练数据来源于AI产生的数据,即由GPT-4等旧模型产生的合成数据。但是,这种方法可能会导致Orion在许多方面表现出旧模型的特征。
OpenAI正在通过其他方式提高LLM处理任务的能力,例如要求模型从大量的数学或编程样本中学习,并通过强化学习来提高答案的效率。此外,人工评估师还会对模型的编码和问题解决表现进行评分,这是基于人类反馈的强化学习对模型优化的重要支持。
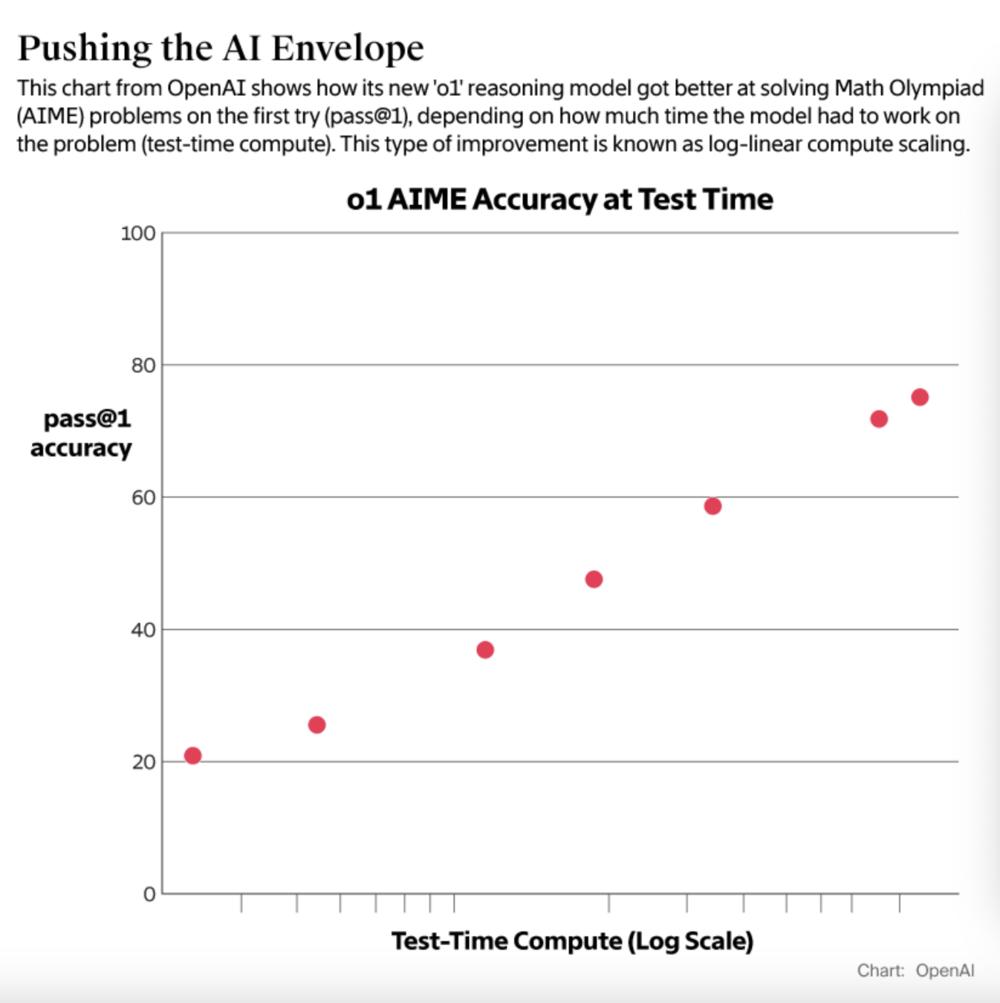
OpenAI于今年9月推出了o1推理模型。与传统模型不同,o1在回答之前“思考”的时间更长,通过增加计算资源来提高响应质量,显示出“测试时计算”(Test-Time Compute)的效果。虽然o1的使用成本是一般模型的六倍,而且这个模型的客户群比较有限,但是阿尔特曼认为它会给科学研究和复杂的代码生成带来突破。
02.在LLM开发平台期,投资基础设施的效果存疑
据The Information报道,Meta 马克·扎克伯格(Mark Zuckerberg)、阿尔特曼和其他AI开发公司的首席执行官都公开表示,目前的技术还没有达到Scaling。 Law设定的极限。为了进一步提高预训练模型的性能,这可能是包括OpenAI在内的公司仍在投资数十亿美元建设大型数据中心的原因之一。
不过,OpenAI研究员诺姆·布朗(Noam Brown)在上个月的TEDAI会议上,我们分享说,开发更先进的模型可能会在财务上变得不可持续。布朗提出异议:我们真的需要花几千亿甚至更多的钱来训练新模型吗?扩展模式最终会达到瓶颈。
OpenAI仍在长期测试下一代模型Orion的安全性。根据公司员工的说法,Orion可能不会在明年年初发布时使用传统的“GPT“命名标准,而是采用新的命名方法。OpenAI官方对此没有评论。
一些已向AI开发商投资数千万美元的投资者,也担心LLM是否已开始保持稳定。
本·霍洛维茨(Ben Horowitz)在投资Mistral和SafeenAI的同时,它也是OpenAI的股东 竞争者,如Superintelligence。OpenAI曾经说过,训练AI所需的GPU数量一直在增加,但是似乎并没有得到预期的智能改进。然而,他并没有进一步详细解释。马克·安德森,霍洛维茨的同事(Marc Andreessen)据说,许多聪明的研究者都在努力突破技术瓶颈,努力提高推理能力。
公司软件供应商Databricks联合创始人Ion董事长Ion Stoica说,LLM在许多方面可能已经进入瓶颈期,但是在其它方面仍在不断进步。Stoica表示,他们的平台允许应用程序开发者对不同的LLM进行评估,发现虽然AI在编码和处理复杂的多步问题上不断改进,但在执行一些通用任务(如分析文本情绪或描述医疗疾病)时,他们的能力似乎放缓了。
Stoica还表示,LLM在常识问题上的表现可能接近极限。公司需要更多的事实数据来进一步提高模型能力,而生成数据的支持是有限的。
03.结论:加强学习,提高模型性能,持续投资,保持竞争力
OpenAI正在通过各种策略来应对当前的技术瓶颈,尤其是LLM面临的高质量数据短缺和性能提升的困境。为了克服这些挑战,OpenAI不仅依靠AI数据平台Scale来提高模型在数学和编程方面的表现,而且依赖于Scale。 为了支持培训过程,AI和LLM培训商Turing等创业公司来管理大量的外包承包商。
尽管目前AI基础设施的投资回报并不明显,而且在LLM培训过程中面临着巨大的财务压力和技术挑战,但是市场竞争和投资热情并没有下降,竞争者们也在不断地下注。举例来说,马斯克旗下的大型独角兽XAI与X平台和英伟达合作,已经建成了10万个H100 强大的GPU集群;为了支持Llamama,Meta倾注了400亿打造类似规模的GPU集群。 4模型训练;苹果还在积极推动与富士康的合作,提高自己设备的AI算率。
本文来自微信微信官方账号的“智东西”(ID:zhidxcom),作家:汪越,编辑:Panken,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com