
李飞飞团队提出了ReKep,使机器人具有空间智能,并且可以整合GPT-4o。





视觉与机器人学习的深度融合。
当两台机器手平稳地合作叠衣服、倒茶、打包鞋子时,加上最近的老头条。 1X 人形机器人 NEO,您可能会有一种感觉:我们似乎正式进入机器人时代。
事实上,这些流畅的动作是先进的机器人技术。 精巧的框架设计 多模态大模型产品。
众所周知,有用的机器人通常需要与环境进行复杂而微妙的交互,而环境则可以表现为空间域和时间域的约束。
例如,如果你想让机器人倒茶,机器人首先需要抓住茶壶的摇杆并保持直立,然后稳定地移动,直到锅口与杯口对齐,然后从一定的角度倾斜茶壶。在这里,约束不仅包括中间目标(如对齐壶口和杯口),还包括过渡状态(如保持茶壶直立);与环境相比,它们共同决定了机器人的运动空间、时间和其他组合要求。
但是,现实世界是复杂的,如何构建这些约束是一个极具挑战性的问题。
最近,李飞飞团队在这个研究方向上取得了突破,提出了关键点约束。(ReKep/Relational Keypoint Constraints)。简而言之,这种方法就是把任务表达成一个关键点序列。另外,这个框架也可以很好地完成。 GPT-4o 等待多模态大模型更好地整合。就演示视频而言,这种方法的表现相当不错。该团队还发布了相关代码。本文一作为 Wenlong Huang。

论文标题:ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
论文地址:https://rekep-robot.github.io/rekep.pdf
项目网站:https://rekep-robot.github.io
代码地址:https://github.com/huangwl18//ReKep
李飞飞说,这项工作展示了视觉与机器人学习的更深层次结合!虽然今年文章没有提到李飞飞。 5 专注于空间智能的年初创建 AI 企业 World Labs,但 ReKep 很明显,它在空间智能方面有很大的潜力。
方法
关键点约束关系(ReKep)
第一,我们先看一个 ReKep 案例。首先,假设这里已经指定了一组。 K 一个关键点。具体而言,每一个关键点 k_i ∈ ℝ^3 所有这些场景都有笛卡尔坐标的表面。 3D 点。
一个 ReKep 案例就是这样一个函数:?: ℝ^{K×3}→ℝ;它可以记住一组关键点(记录 ?)投射成无界成本(unbounded cost),当 ?(?) ≤ 0 即时表示满足约束。在具体实现方面,该团队将函数 ? 为一种无状态的状态而实现 Python 函数,其中包含关键点。 NumPy 这些操作可能是非线性的,也可能是非突出的。本质上,一个 ReKep 这个案例编码了一个关键点之间所需的空间关系。
但是一个操作任务一般涉及多个空间关系,可能有多个与时间相关的阶段,每个阶段都需要不同的空间关系。因此,团队的做法是将一项任务转化为 N 每个阶段都可以使用 ReKep 为每个阶段 i ∈ {1, ..., N } 指定两种约束:
一组子目标的约束
一组路径约束
其中
编码了阶段 i 之后要实现的一个关键点关系,
编码了阶段 i 内部每一种状态都要满足的关键关系。以图为 2 以倒茶任务为例,它包括抓取、对齐、倒茶三个阶段。
阶段 1 子目标约束是将末端执行器伸向茶壶把手。阶段 2 子目标约束是让茶壶口位于杯口上方。另外,阶段 2 路径约束是保持茶壶直立,防止茶水溢出。最后阶段 3 子目标约束是达到指定的倒茶视角。
使用 ReKep 将操作任务定义为约束优化问题
使用 ReKep,机器人操作任务可以转化为约束和优化涉及子目标和路径的问题。在这里,末端执行器的姿势记录 ? ∈ SE (3)。为执行操作任务,这里的目的是获得整个离散时间轨迹 ?_{1:T}:
换言之,对于每一个阶段 i,这种优化问题的目的是:基于给定。 ReKep 约束和协助成本,找到一个终端执行器姿势作为下一个子目标(及其相关时间),以及实现这个子目标的姿势序列。这个公式可以看作是轨迹提升中的一个 direct shooting。
实例化的分解和算法
上述公式可以实时求解。 1.团队选择分解整体问题,只优化下一个子目标和实现子目标的相应路径。算法 1 在这个过程中给出伪代码。
解决子目标问题的公式如下:
解决路径问题的公式如下:
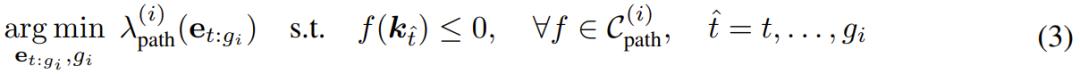
回溯
现实环境复杂多变。有时候,在任务过程中,上一阶段的子目标约束可能不再成立(比如倒茶的时候杯子被拿走了),所以这个时候需要重新规划。这个团队的做法是检查路径是否有问题。如果发现问题,可以迭代追溯到前一阶段。

关键点的前向模型
为了求解 2 和 3 这个团队使用了一个前向模型。 h,它可以在优化过程中根据优化过程 ∆? 估计 ∆?。具体而言,给出终端执行器的姿势。 ∆? 通过应用相同的相对刚度转换来改变 ?′[grasped] = T_{∆?}・?[grasped] 在假设其他关键点保持静止的同时,计算关键点位置的变化。
重点建议和 ReKep 生成
为了让这个系统在实际前提下自由执行各种任务,团队还使用了大模型!具体来说,他们使用大型视觉模型和视觉模型 - 语言模型设计了一套实现关键点建议和关键点的管道流程 ReKep 生成。
关键点建议
给出一张 RGB 图像,先用 DINOv2 提取图块的特性 F_patch。接着执行双线性插值,将特征采样到原始图像大小,F_interp。他们使用了所有的相关物体,以确保建议包含在场景中。 Segment Anything(SAM)从场景中提取所有的掩码 M = {m_1, m_2, ... , m_n}。
对每一个掩码 j,使用 k 均值(k = 5)衡量与余弦相似度的掩码特征 F_interp [m_j] 进行聚类。聚类的质心被用作备选的关键点,然后被校正。 RGB-D 把相机投射到世界坐标上 ℝ^3。距离备选要点 8cm 其他备选内容将被过滤掉。总的来说,这个团队发现这个过程可以识别出大量粗粒度和语义价值的目标区域。
ReKep 生成
得到备选要点后,再将其叠加到原来的重点。 RGB 图像上,并标注数字。结合具体任务的语言指令,然后查询 GPT-4o 以产生所需阶段的数量和每个阶段的数量 i 相应的子目标约束和路径约束。
试验
这个小组通过实验验证了这个约束设计,并试图回答以下三个问题:
1. 这个框架自动构建和合成操作行为的表现如何?
2. 这个系统对新物体和操作策略的泛化效果如何?
3. 每一个部件都会如何引起系统异常?
使用 ReKep 操作两个机械臂
通过一系列任务,他们对系统进行了多阶段的检查。(m)、野外 / 实用情景(w)、双手(b)和反应(r)行为。这包括倒茶。 (m, w, r)、放置书本 (w)、回收罐子 (w)、在盒子上贴胶带 (w, r)、叠衣服 (b)、装鞋子 (b) 和协作折叠 (b, r)。
结果见表 这里报告的是通过率数据。
总的来说,即使没有提供特定的任务数据或环境模型,新提出的系统也能在非结构化环境中构建正确的约束并实施。值得注意的是,ReKep 能有效地解决每一项任务的关键问题。
以下是一些实际执行过程的动画:
操作策略的泛化
该团队在叠衣任务的基础上探索了新策略的泛化性能。简而言之,就是看这个系统是否可以叠不同的衣服。 —— 它需要几何和常识推理。
这里使用了 GPT-4o,提词只包含一般指令,没有前后示例。「策略成功」是指产生的 ReKep 可行,「执行成功」这就是对每一种服装给出可行策略的系统通过率的衡量。
结果非常有趣。我们可以看到,这个系统对不同的衣服采用了不同的策略,有些衣服和人类常用的方法是一样的。

错误的系统分析
这个框架的设计是模块化的,所以分析系统错误非常方便。该团队手动检查了表格。 1 测试中遇到的故障案例,然后在此基础上计算了模块造成错误的概率,同时考虑了它们在设备过程中的时间依赖。结果如图所示 5。
可以看出,在不同的模块中,关键点跟踪器犯的错误最多,系统很难准确跟踪,因为频繁的和间或屏蔽。
本文来自微信微信官方账号“机器之心”,编辑:Panda,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com