
报告称,到2030年,人工智能模型可以扩展10000倍






人工智能(AI)最近的进步主要有以下几点:规模。
大约在本世纪初,人工智能实验室注意到,算法或模型的规模不断扩大,并继续为其提供更多的数据,可以大大提高算法和模型的性能。
最新一批AI模型拥有数千亿到数万亿以上的内部数据连接,通过消耗大量的互联网资源,学会像我们一样编写代码。
训练更多的算法需要更强的计算能力。因此,根据非营利性人工智能研究机构EpochAI的数据,专门用于人工智能训练的计算能力每年翻两番。
如果这种增长持续到2030年,未来的AI模型将比今天最先进的算法(例如OpenAI的GPT-4)具有10,000倍的计算能力。。
Epoch在最近的一份调查报告中写道:“如果我们继续下去,我们可能会在十年末看到人工智能的巨大进步,就像2019年GPT-2的简陋文本生成和2023年GPT-4的复杂问题解决能力的差异一样。”
然而,现代人工智能已经吸收了大量的电力、数万个先进芯片和数万亿个在线案例。与此同时,该行业经历了芯片短缺,研究发现,它可能会耗尽高质量的培训数据。
假定公司继续投资人工智能扩张:这种增长速度在技术上可行吗?
Epoch在报告中讨论了电力、芯片、数据和延迟四个限制因素。总结:技术上有可能保持增长,但不确定。原因如下:
01.动力:我们应该有大量的电力。
根据Epoch的数据,这相当于23000个美国家庭的年用电量。然而,即使效率提高了,2030年训练一款前沿人工智能模型所需的电力也将是现在的200倍,也就是大约6千兆瓦。。它相当于当前所有数据中心用电的30%。
能够提供这么多电力的电站很少,估计大部分电站都签了长期合同。但这是假设一个电厂可以为一个数据中心供电。
Epoch认为,公司将寻找一个可以通过当地电网从多个电站供电的地区。考虑到公共事业在计划中的增长,仍然有可能走这条路。
为方便打破瓶颈,企业可在多个数据中心之间进行分配培训。在这种情况下,他们会在多个位置的单个数据中心之间分批传输训练数据,从而减少任何数据中心的电力需求。
这一策略需要快速、高带宽的光纤连接,技术上是合理的,谷歌双子座超级计算机的运行就是一个早期的例子。
总的来说,Epoch提出了从1千兆瓦(当地电源)到45千兆瓦(分布式电源)的各种可能性。企业使用的电力越多,可训练模型就越大。如果电力有限,可以使用比GPT-4高出10000倍左右的计算能力来训练模型。
02.芯片:能否满足计算要求?
所有这些电力都用于操作人工智能芯片。有些芯片为客户提供完整的人工智能模型;有些人训练下一批模型。Epoch仔细研究了后者。
图形处理器用于人工智能实验室。(GPU)训练新模型,英伟达是GPU领域的佼佼者。台积电(TSMC)生产这些芯片,并将其与高带宽内存夹在一起。预测必须考虑这三个步骤。根据Epoch的说法,GPU生产可能仍然有剩余产能,但内存和包装可能会干扰发展。
考虑到行业产能的预期增长,在AI训练中,他们认为2030年AI芯片可能会使用2000万到4亿次。。有些将用于当前模型,而人工智能实验室只能购买其中的一小部分。
范围如此之大,说明模型存在很大的不确定性。但是考虑到预期的芯片容量,他们认为一个模型可以练习计算能力,比GPT-4高5万倍左右。
数据:人工智能在线教育
众所周知,人工智能对数据的渴望和即将到来的稀缺是一个限制因素。有人预测,到2026年,将会缺乏高质量的公开数据流。但是Epoch认为,数据稀缺不会阻碍模型的发展,至少在2030年之前。。
根据目前的增长速度,人工智能实验室将在五年内耗尽高质量的文本数据,版权诉讼也可能影响供应。
Epoch认为这增强了他们模型的不确定性。但是,即使法院作出有利于版权持有者的判决,比如VoxMedia、《时代》、公司采用的复杂执法和许可协议,如《大西洋月刊》,也意味着对供给的影响将是有限的。
但是,现在的模型在训练中不仅使用文本,而且非常重要。。例如,谷歌的Gemini是通过图像、音频和视频数据来练习的。
非文本数据可以通过字幕和脚本增加文本数据的供应。非文本数据也可以扩展模型能力,比如识别冰箱食品的图片,推荐晚餐。
更可以推断的是,它甚至可能导致迁移学习,即在多种数据类型中训练出来的模型优于仅在一种数据类型中训练出来的模型。
Epoch说,也有证据表明,生成数据可以进一步扩大信息量,但是具体的数量并不清楚。。
长期以来,DeepMind一直将生成数据应用到其强化学习算法中,Meta公司也使用了一些生成数据来训练其最新的人工智能模型。
然而,在不降低模型质量的情况下,可能会有硬性限制使用多少生成数据。此外,生成数据的计算能力更昂贵。
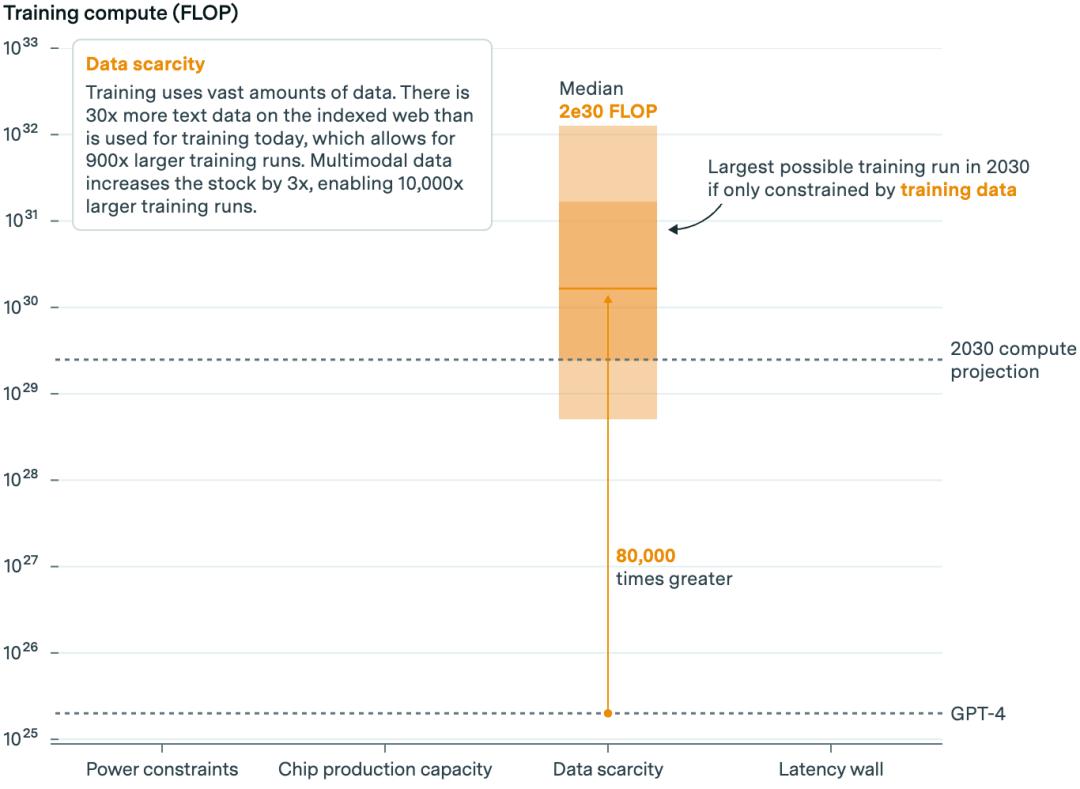
但一般而言,包括文本、非文本和合成数据,Epoch估计有足够的数据来训练人工智能模型,其计算能力是GPT-4的8万倍。
延迟:规模越大,速度越慢。
最后一个限制因素与即将推出的算法的规模有关。算法越大,数据穿越其人工神经元网络所需的时间就越长。这可能意味着训练新算法所需的时间变得不切实际。
这有点技术性。简而言之,Epoch研究了培训数据批号的规模,以及在人工智能数据中心服务器内部和服务器之间处理数据所需的时间,以便对未来模型的潜在规模进行并行计算。通过这种方式,我们可以估计需要多长时间来训练一个规模的模型。
主要启发以目前的设置来训练人工智能模型最终会遇到天花板,但不会持续太久。
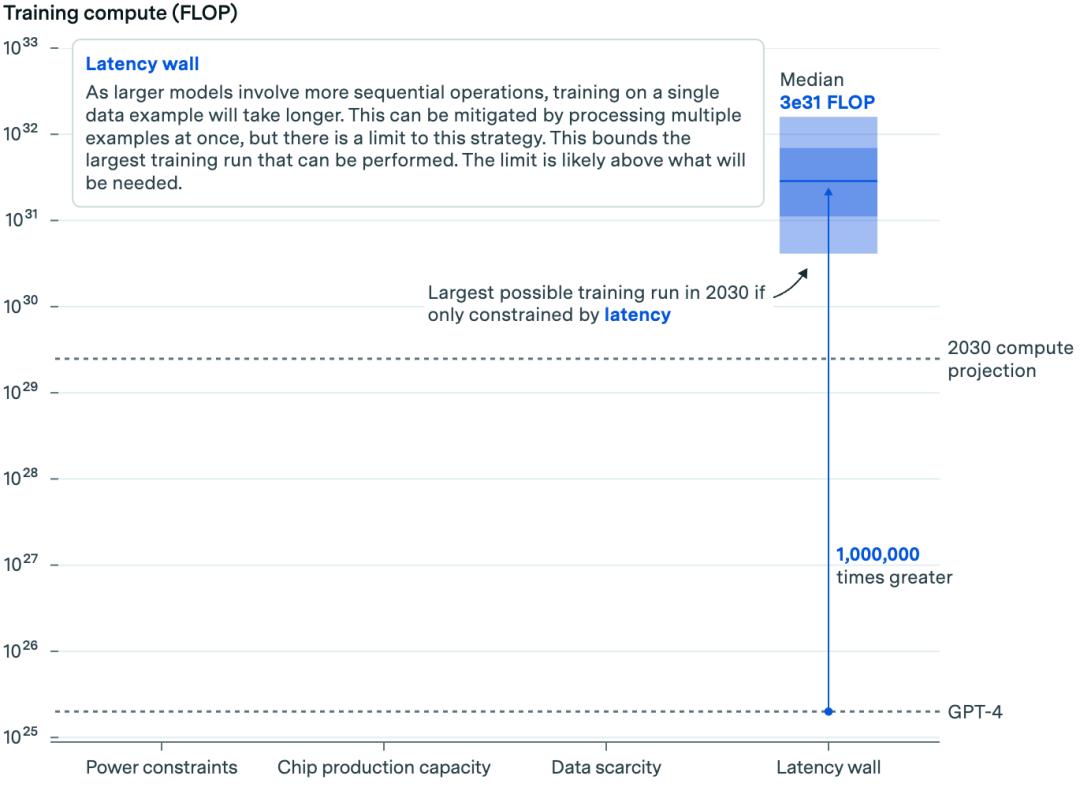
根据Epoch的估计,根据目前的做法,我们可以使用比GPT-4高出100万倍的计算能力来训练人工智能模型。
扩展规模:10000倍
我们会注意到,在每一种约束条件下,可能的人工智能模型规模都会变大,换句话说,芯片上限高于功率,数据上限高于芯片,以此类推。
但是,如果我们把所有的限制放在一起,那么模型只有在遇到第一个瓶颈的时候才能实现。在这种情况下,瓶颈就是动力。即便如此,技术上还是可以大幅度扩展的。
Epoch认为:“如果充分考虑,这些人工智能瓶颈意味着训练运行高达2e29FLOP至本十年末是合理的。”
这样就代表了相对于目前的模型来说,大约是10,000倍的扩展,代表着历史上的扩展趋势可以持续到2030年。。
虽然所有这些都表明技术上有可能继续扩张,但这也做出了一个基本假设:人工智能投资将根据需要增加,以支持扩张,扩张将继续产生令人印象深刻的进步,更重要的是,有用的进步。
目前,各种迹象表明,科技公司将继续投入历史性的高额现金。在人工智能的推动下,新机器和房地产的支出已经跃升到多年来从未见过的水平。
AlphabetCEOSundar 在上一季度的财务报告电话会议上,Pichai表示:“在经历这种曲线时,投资不足的风险远远大于过度投资的风险。
但是费用还需要进一步增加。首席执行官Darioopic公司Anthropic 估计Amodei,如今,训练模型的成本可能高达10亿美元,明年的模型成本可能接近100亿美元。在接下来的几年里,每个模型的成本可能达到1000亿美元。。
这个数字令人眼花缭乱,但是企业可能愿意为此付出代价。据悉,微软已为其Stargate人工智能超级计算机投入了大量资金,该项目是微软与OpenAI的合作项目,将于2028年推出。

显然,投资数百亿或数千亿美元的想法是无法保证的。归根结底,这个数字超过了很多国家的GDP和科技巨头目前年收入的很大一部分。伴随着人工智能的光芒逐渐褪去,人工智能能否持续增长可能成为“你最近为我做了什么”的问题。。
投资者已经在检查底线。如今,投资金额与收益金额相比相形见绌。为了证明加大努力是合理的,企业必须确保其规模不断扩大,能够生产出更多更强大的人工智能模型。
这意味着即将推出的模型面临越来越大的压力,必须超越渐进的改进。如果收入下降,或者有足够的人不愿意为人工智能产品买单,情况可能会发生变化。
此外,一些评论家认为,大型语言和多模式模型可能只是一条昂贵的死路。。而且,总有突破的可能,就像这一轮的突破一样,意味着我们可以用更少的资源完成更多的任务。我们的大脑不需要像互联网那样庞大的数据量,只需要一个灯泡能量就可以继续学习。
Epoch表示,即便如此,如果目前的方法“能够自动化相当一部分经济任务”,其经济回报可能高达数万亿美元,这足以证明成本的合理性。很多业内人士都愿意下载这个筹码。但目前还不知道结果如何。
文本来源:
1.https://singularityhub.com/2024/08/29/ai-models-scaled-up-10000x-are-possible-by-2030-report-says/
本文来自微信公众号“元宇宙之心MetaverseHub”,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com