
Stable 原始作者Diffusion创业,井喷AI视觉再添新玩家。








假如2023年是文本生成大模型爆发的一年,那么从2023年下半年到2024年上半年,就是视觉大模型(包括图片和视频)的井喷期,MidJourney V6,Sora,Stable Diifusion 3-Ultra等模型引领这一趋势。
现在,视觉模型创业井喷还在继续,最新的例子是Black Forest Labs,这是由Stable制成的 创建了Diffusion的原始团队,并且刚刚推出了12B尺寸,选择DiT。(Diiffusion Transformer)FLUXX视觉大模型.具有与最先进模型相媲美的导出性能。

这个照片是FLUX的.作者viet生成
Black Forest 最近,Labs获得了Andreessen Horowitz领先投资(a16z),Brendandan天使投资者 Iribe、Michael Ovitz、Garry Tan、Timo Aila和Vladlen Koltun和其他著名的AI研究和公司建设专家投资了3100万美元的种子轮融资。它还表示Generalal Catalyst和MäTchVC的后续融资也已经有了眉眼。
FLUX.1文字生成图像模型有三个版本,它不仅可以通过API提供闭源,还可以在Apache2.0的许可下开放获取。如今,StabilityAI动荡不安,它使开发者拥有强大的视觉基础模型,成本低廉,为开源人工智能社区注入了新的活力。
构造新型,大型开源视觉模型
Black Forest 由优秀的AI研究人员和工程师组成的Labs,在学术界、工业界和开源界都有很好的积累。之前,他们创建了VQGAN和潜在扩散(Latent Diffusion)模型,Stable 例如Stableblee(Stable),Diffusion图像和视频生成模型 Diffusion XL、Stable Video Diffusion、Rectified Flow Transformers),对抗性扩散蒸馏,用于快速即时图像合成。(Adversarial Diffusion Distillation)。
Robin的核心领导团队 Rombach、Patrick Esser和Andreas 特别是Robinn,由Blattmann组成 Rombach,这是Stable 两个主要的Diffusion创始人之一。Stable可以说是他们在潜在扩散模型上的工作。 Diffusion为DALLLL等DALL奠定了基础。-E 模型的核心结构元素,如2和3,Sora。
Black Forest Labs表示,他们的核心信念是,普遍可访问的高性能模型不仅可以促进社区和学术界的创新和合作,还可以提高透明度,这对于信任和广泛应用尤为重要。
FLUX.1模型家族
Black Forest FLUXX是Labs最新发布的。.1文生图模型家族,本系列模型均采用DiT(Diiffusion Transformer)混合式结构,宽度为12B(在视觉模型中属于超大尺寸),它还采用了构建流匹配。(flow matching)新的扩散模型训练方法,如方法,并引入转动位置嵌入和并行注意层,以提高模型性能和硬件效率。
在图像细节、提醒跟踪、风格多样性、情景复杂性等方面,这一系列新模型取得了良好的效果。例如,它能产生高分辨率的图像,使身体产生更加解剖合理,并且由于Transformer的加入,在复杂的指令跟踪方面表现更好。
FLUX.1共有3个版本,FLUX.1 [pro],FLUX.1 [dev]和FLUX.1 [schnell]。
FLUX.1 [pro]它是最好的性能版本,具有一流的提醒跟随、视觉质量、图像细节和输出多样性。它可以通过Black Forest API、Replicate和fallabs.获取ai等模型云平台。
FLUX.1 [dev]它是一种指导蒸馏模型,具有开源权重,从FLUXX开始。.1 [pro]蒸馏而来,FLUX.1 [dev]比同等大小的标准模型更有效率,同时保证相似质量和提醒遵循能力。FLUX.1 [dev]它的权重可以在HuggingFace上获得,但是它不是一个商业开源模型。
FLUX.1 [schnell] 专门为当地开发和个人使用量身定做,它采用宽松的Apache2.0开源协议,推理代码可以在GitHub和HuggingFace的Diffusers中找到。该模型优化了推理速度。
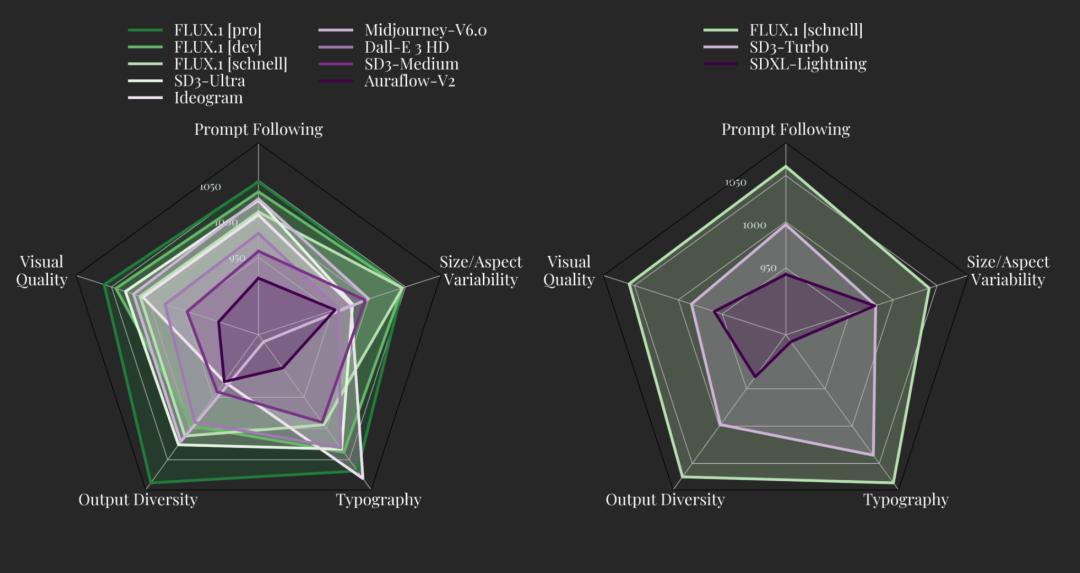
Black Forest Labs将FLUX.Midjourney系列模型 v6.0、DALL·E 3(HD)与SD3-Ultra等主流视觉模型相比,它已经达到了SOTA,无论是测试场ELO成绩、模型尺寸、生成质量、指令遵循等数据平衡。它的两个开源模型也超越了Stable Diifusion 3系列相应类型模型。
事实上,今年的视频模型比文生图更受欢迎,Black Forest Labs还预测了它的视频模型,这个视频模型将使用FLUX.以高精度、高清晰度、高速度为基础。

A16z在一篇博文中说:“视觉AI正面临供应链问题。虽然图像和视频生成的基本模型发展迅速,但这些基本模型只是AI价值链的开始。为了充分发挥这些模型的最大潜力,需要世界上最好的产品和工程团队来创造一个愉悦、简单、量身定制的工作流程和终端用户体验——这是价值链的终点——而不是成为生成模型探索的专家。
所以,我们很高兴地向Black宣布。 Forest Labs(BFL)种子投资。这个团队旨在为开发者构建世界上最好的开源视觉模型。BFL致力于满足这一需求,只关注价值链的开始部分,让开发者和产品工程师能够致力于结束部分。"
良好的模型能力 强大的商业化能力,是视觉大模型创业的光明大道。
为什么会有视觉模型井喷?一方面是需求造成的,视觉模式对人的刺激明显大于简单的文字;另一方面,这与AI模型的本质和实现AGI的道路有关。
Transformer模型的本质是预测下一个Token。AI模型的本质是“压缩”数据,所以视觉模型预测的是下一个视觉图像,压缩的是视觉数据,这使得汉字的压缩更接近现实世界。一些学者也认为它更接近实现AGI。
顶级AI学者认为视频不够,模型数据应该是3D的,需要引入“空间”属性。例如,美国国家工程院教授李飞飞告诉国内媒体,实现AGI的关键环节是“空间智能”,而不是二维智能。只有通过空间智能,我们才能看到世界,感知世界,理解世界,让机器人做事,从而形成良好的闭环。
从学术世界回到AI视觉模型的创业和应用。现在的格局类似于文本大模型,分为模型派和应用派。
以OpenAI为例,模型派的杀手产品仍然只有ChatGPT,DALL·E 第三,作为一种功能嵌入应用程序,它不是专门为视觉模型开发应用程序,也不是针对某一特定场景进行针对性提升。
APP学校,MidJourney在ToC方向比较典型,已经有了自己完善的APP生态,也有了自己不断迭代的模型。在ToB方向,大厂的Adobe将AI视觉模型能力融入到其视觉工具套件Firefly中,也有Synthesia这样的创业公司,致力于使用AI视觉模型为企业生成真人avatar。
在中国,有快手可灵、智谱CogVideoX(开源)等视频模型,当Sora还是“期货”时,它们已经逐渐开放,其效果也具有很强的竞争力。
还有一种类型的创业企业是模型 在中国,应用程序的典型例子是Hidream.ai。它有自主研发的DiT架构大尺寸视觉模型,不仅有专业创作者的文学图片和文学视频应用,还有电子商务、视频铃铛等垂直场景的专用工具。
这种类型的创业公司是具有学术/商业/大厂背景的顶级企业家,在AI创业时应选择的方向。
也许你已经注意到了,Black Forest Labs的FLUX.在1系列模型中,有两种模型是开源的。事实上,开源模型对AI的开发者生态、创业和应用生态非常重要。一方面,开源模型可以使开发者社区探索更广泛的应用和用例,并允许外部研究者分析模型中的潜在偏见或问题,从而帮助模型建立信任,提高可靠性。
另一方面,开源模型对初创企业和小企业使用AI非常重要,这有助于这些企业减轻模型培训负担,进而促进小团队在应用上的创新。要知道,当MidJourney获得1亿美元的收入时,整个团队只有十几个人。
本文来自微信微信官方账号“阿尔法公社”(ID:alphastartups),作者:发现非凡企业家的,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com