
著名的BERT在哪里?这一问题的答案显示了LLM范式的变化





机器之心报道
编辑:Panda
编码模型在哪里?假如 BERT 效果很好,那为什么不扩展呢?编码器 - 解码器或者只是编码器模型怎么样?
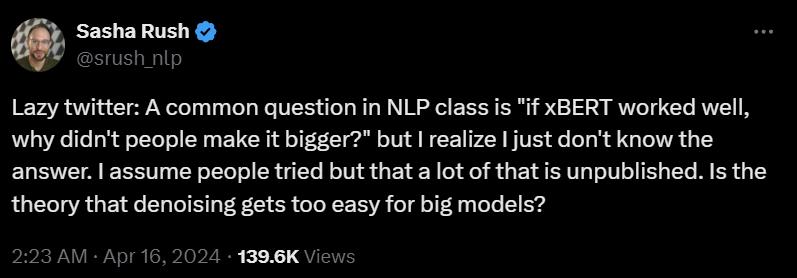
各种语言模型(LLM)领域,现在只是解码器模型(例如 GPT 系列模型)引领风骚时代。那个编码器 - 解码器或者只是编码器模型的发展情况如何?为什么曾经出名一时? BERT 但是逐渐没有人关注呢?
近日,AI 创业公司 Reka 首席科学家和创始人 Yi Tay 发表了一篇博客文章,分享了他的观点。Yi Tay 在参加创立 Reka 之前曾在 Google Research 与谷歌大脑一起工作了三年多, PaLM、UL2、Flan-2、Bard 等着名 LLM 以及 PaLI-X 和 ViT-22B R&D等多模态模型。下面是他的博客文章内容。

基础简介
总的来说,过去几年的事情 LLM 模型架构主要分为三种类型:仅编码器模型(例如 BERT)、编码器 - 解码模型(例如 T5)、仅解码模型(例如 GPT 系列模型)。在误解这些分类方法和结构的同时,人们通常对此感到困惑。
首先要理解的是:编码器 - 事实上,解码器模型也是自回归模型。编码器 - 在解码器模型中,解码器本质上仍然是因果解码器。它会将一些文本卸载到编码器中,然后通过交叉注意力发送给解码器,而不是预填充解码器模型。是的,T5 模型也是语言模型!
这一模型的组合是前缀语言模型。(Prefix Language Model),简称 PrefixLM,它的工作模式几乎是一样的,只是没有交叉注意力(还有其他小细节,比如编码器。 / 在没有编码器瓶颈的情况下,解码器之间共享权重。PrefixLM 有时候也叫非因果解码器。简而言之,编码器 - 解码器,只有解码器模型和 PrefixLM 总的来说,差别不大!
在 Hyung Won 在最近的精彩讲座中,他熟练地解释了这些模型之间的关系。详情请参考机器之心的报道:《》
同时,BERT 这种只有编码器模型的除噪方式不同(即 in-place);而在某种程度上,只有编码器模型才能在预训练后真正发挥作用,需要依靠分类。「任务」头部。T5之后 等待模型采用了一种「修改版」去噪目标,它采用了序列到序列的格式。
所以,需要指出:T5 里面的噪音去除不是一个新的目标函数(从机器学习的意义上来说),而是一个跨输入数据转换,也就是你也可以用一个因果解码器训练跨度损坏目标。(span corruption objective )。
人们总是假设编码器 - 解码模型必然是去噪模型,部分原因是 T5 太有代表性了。但事实并非总是如此。您可以使用常规的语言建模任务(如因果语言建模)来训练编码器。 - 解码器。另一方面,因果解码器也可以通过跨距损坏任务进行训练。正如我前面所说,这基本上是一种数据转换。
还有一点值得注意:一般而言, 2N 一个参数编码器 - 解码器的核算费用和 N 一个参数就像解码器模型一样,这样,它们的 FLOP 与参数的比例不同。它就像在输入和目标之间分配一样「模型稀疏性」。
那不是什么新鲜事,也不是我自己想出来的。2019 年 T5 这篇论文里有,而且 UL2 这篇文章也再次强调了这一点。
现在看来,很高兴能够把这个说清楚。现在就是目标。
对于去噪目标(它不起作用吗?不能扩展吗?还是太容易了?)
这儿的除噪目标指的是「跨距损坏」任务随意组合。有时被称为任务。「添充」或「填空」。有许多方法可以表达它,例如跨距长度、随机性、sentinel token 等等。想想你已经明白了其中的关键。
虽然 BERT 模型除噪的目标基本上是就地(in-place,比如分类头位于掩码 token 上),但「T5 风格」要更加现代化,也就是通过编码器 - 解码器或者只是解码器模型来处理数据转换。在这种数据转换中,被掩盖的 token 只是会被「移回去」这样就可以预测模型了。
预训练的主要目标是以尽可能高效有效的方式构建与下游任务对齐的内部表征。这种内部表征越好,后续任务就越容易使用这些学到的表征。众所周知,下一个词的简单预测「因果语言建模」目标表现出色,并且已经成为 LLM 革命的关键。目前的问题是去噪目标是否同样出色。
据公开信息,我们知道 T5-11B 即使在对齐和监管微调之后,效果也相当不错,(Flan-T5 XXL 的 MMLU 分数是 55 ,那时候,这个规模模型已经很好了)。所以我们可以得出这样的结论:去噪目标的转移过程(预训练→对齐)在这一规模上相对有效。
在我看来,去噪目标的效果很好,但是不足以独立作为目标。一种巨大的缺陷源于所谓的更少。「损失暴露(loss exposure)」。只有少量的噪声去除目标。 token 会被掩盖和学习(也就是说,考虑到损失)。另一方面,在常规语言建模中,这接近于常规语言建模。 100%。这使得每个 FLOP 样品效率很低,这使得样品效率很低。 flop 在基本对比中,去噪目标有很大的劣势。
除噪目标的另一个缺点是,它比常规语言建模更不自然,因为它会以一种奇怪的方式重新设置输入。 / 导出格式使其不适合少样本学习。(但是,在少样本任务中,这些模型仍然可以通过调整来表现得相当好。)所以我觉得去噪目标只能作为常规语言建模的补充目标。
统一的初始阶段和 BERT 类型消失的原因
类似 BERT 模型逐渐消失,现在已经没有多少人谈论它们了。这样还可以解释为什么我们现在看不到超大的规模。 BERT 模型了。原因是什么?这样做很大程度上是因为任务 / 统一和改变建模模式。BERT 模型非常繁琐,但是 BERT 弃用模型的真正原因是:人们希望一次完成所有的任务,所以采用了更好的除噪方法。 —— 采用自回归模式。
在 2018-2021 在过去的几年里,出现了一种隐含的范式转变:从微调单任务转变为大规模多任务模式。这样就逐渐把我们引向了统一。 SFT 模型,这就是我们现在看到的通用模型。使用 BERT 却很难做到这一点。我认为这与「去噪」关系不大。对还想要使用这种模型(也就是 T5)人们,他们找到了一种再一次表达去噪预训练任务的方法,这使得现在 BERT 由于我们已经有了更好的替代方案,所以模型基本上被抛弃了。
更加准确地说,编码器 - 解码器和只有解码器模型可以用于各种任务,而不需要特定于任务的分类头。对编码器来说。 - 解码器,研究者和工程师开始发现放弃编码器的效果就像 BERT 编码器也差不多。另外,这样可以保留双向专注的优点。 —— 该优势让 BERT 可以在小规模(一般是经营规模)上与 GPT 竞争。
噪声目标的价值
去噪预训练目标也可以通过类似常规语言建模的方式学习和预测下一个单词。但与常规因果语言建模不同,这需要使用一种数据对序列进行变换,从而促进模型的学习。「填空」,与其简单地预测从左到右的自然文本。
值得注意的是,除噪目标有时也被称为「添充任务」,在预训练过程中,有时会与常规语言建模任务混合使用。
虽然精确的设备和实现细节可能有所不同,但今天的现代 LLM 语言建模和添加可以在一定程度上结合。有意思的是,这个「语言模型 添充」事实上,混合物也可能在同一时期到处传播(例如 UL2、FIM、GLM、CM3),许多团队都带来了自己独特的混合方案。顺便说一下,目前已知的这种训练方法的最大模型很可能是 PaLM-2。
还需要注意的是,预训练任务混合也可以按顺序堆叠,不一定要同时混合,比如, Flan-T5 起初是在 1T 跨距损坏 token 进行训练,然后改为前馈语言建模目标。 100B token,之后再进行 flan 指令微调。在一定程度上,这种方法适用于混合和去噪 / LM 目标模型。需要明确的是,前缀语言建模目标(不要混淆结构)只是因果语言建模,它有一个随机确定和发送到输入端的分割点(没有损失或非因果掩码)。
对了,添加可能源于代码。 LLM 领域,其中「填空」这更像是一个键入代码所需要的功能。同时,UL2 更多的动机是去噪目标和双向动机 LLM 所擅长的任务类别与固有的生成任务(如总结或开放生成)相结合。这是一种自回归解码「向后移」优点是:它不仅可以让模型学习更长时间的依赖关系,还可以让它隐藏得益于非显眼的双向注意力(因为你已经看到了未来填空)。
传说中有一种经验:去噪目标学习表现在特定的任务类别上更好,有时样本效率更高。在 U-PaLM 在本文中,我们展示了少量的跨度损坏 up-training 怎样改变在一组 BIG-Bench 行为和任务中的出现。在此基础上,微调使用该目标训练模型通常可以获得更好的监管微调模型,尤其是在规模较小的情况下。
就单个任务微调而言,可以看到 PaLM-1 62B 这个模型要小得多 T5 战胜模型。就相对较小的规模而言,「双向注意力 去噪目标」这是一个漂亮的组合拳!我想许多实践者也注意到了这一点,尤其是在生产应用中。
双向注意怎么样?
对于语言模型来说,双向注意是一种有趣的方法。「归纳偏置」—— 它通常与目标和模型骨干混为一谈。归纳偏置在不同的计算领域有不同的用途,也可能对扩展曲线产生不同的影响。即便如此,与较小的规模相比,双向注意力在规模巨大时可能并不那么重要,或者可能对不同的任务或模式有不同的影响。举个例子,PaliGemma 使用了 PrefixLM 架构。
Hyung Won 还在他的演讲中指出:PrefixLM 模型(只有解码器模型使用双向专注力)也存在缓存问题,这是这种结构的固有缺陷。但是,我认为解决这个缺陷的方法有很多,但这超出了本文的范围。
编码器 - 解码器架构的优缺点
与仅解码器模型相比,编码器 - 解码器结构有优点也有缺点。第一种情况是编码器端不受因果掩码的限制。在一定程度上,你可以在不担心自回归的设计限制的情况下,在注意力层面放开手脚,激进地执行池化或任何方式的线性注意力。这是一个不太重要的「前后文」卸载到编码器的好方法。您还可以将编码器做得更小,这也是一个优势。
必需编码器 - 一个解码器架构的例子 Charformer,其中,编码器的大胆使用减少了字节模型速度的劣势。创新编码器可以快速受益,同时不用担心因果掩码的重大缺陷。
与此同时,相比较 PrefixLM,编码器 - 解码器的一个缺点是输入和目标必须分配固定的预算。例如,如果输入预算是 1024 token,因此,编码器端必须在此值中填充,这可能会浪费大量的计算。相反,现在, PrefixLM 在中间,输入和目标可以直接连接起来,从而可以缓解这一问题。
相关性和关键点与今天的模型有关。
当代社会,要成为一个合格的社会。 LLM 研究人员和实践者的关键能力之一是从结构和预训练方面推断和总结偏差。理解细微的差异可以帮助我们推送和不断创新。
下面是我的要点:
编码器 - 解码器和仅解码器模型都是自回归模型,在推广角度上有差异,各有优缺点。它们有不同的归纳偏差。选择哪一个取决于下游用例和应用限制。同时,对于大多数人来说, LLM 就用例和冷门用例而言,可以认为 BERT 编码模型已经过时。
除噪目标主要可以作为因果语言模型的补充。它们已成功应用于训练阶段「支持目标」。使用除噪目标训练因果语言模型一般可以带来一定程度的帮助。虽然这在代码模型领域很常见(即添加代码),但使用因果语言模型和一定的除噪目标进行预训练是相当常见的。
双向注意力可以给小型模型带来很大的帮助,但对于大型模型来说并不重要。这大多是谣言。我觉得双向注意力有一种归纳偏差,类似于对。 Transformer 许多其他类型的模型进行修改。
最后,总结一下。目前还没有大规模版本。 BERT 模型正在运行:BERT 该模型已被弃用,随之而来的是更加灵活的去噪(自回归)T5 模型。这主要是因为范式统一,即人们更喜欢使用通用模型来执行各种任务(而不是使用特定的任务模型)。同时,自回归噪音有时可以作为因果语言模型的副目标。
原文链接:https://www.yitay.net/blog/model-architecture-blogpost-encoders-prefixlm-denoising
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com