
“谷歌正抓取一切”






从今往后,你在网上公开说的每一句话,都有可能被Google拿去训练AI!
是的,继画画之后,文字作品也要拿来给大模型喂饭了。
无论是技术博客、代码、论文,还是所有你在网上公开的帖子,都有可能被扔进“Google大模型搅拌机”,即使有版权也一样。
就在上周,谷歌更新了一版隐私政策,明确表示他们保留抓取所有在线公开内容的权利,以构建其AI工具。
网友们顿时炸开了锅。有人警告说,“谷歌正在抓取一切”。
一旦谷歌能够读取你写的东西,就意味着这些都是他们的“所有物”了。
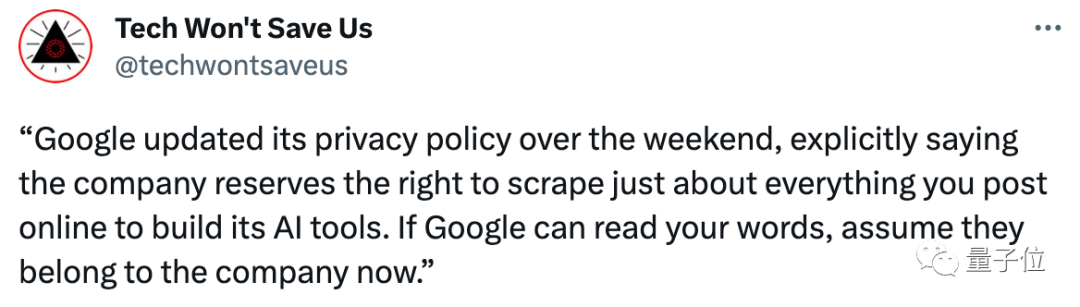
也有网友持比较悲观的看法:
很快啊,所有内容产出者就都会是AI了。

所以,这版隐私政策究竟是怎么回事?
用于训练Bard等AI产品
事情还得从谷歌这几天更新的隐私政策说起。
在最新的隐私权政策中,谷歌增加了一个关于“研究和开发”的AI模型条款:
Google会利用信息来改进我们的服务并开发新的产品、功能和技术,以惠及我们的用户和公众。
例如,我们会利用公开信息来帮助训练Google的AI模型并打造实用产品和功能(比如Google翻译、Bard和Cloud AI功能)。
换句话说,就是将所有可能收集到的公开信息,用于Google翻译、Bard和CloudAI等AI相关产品或功能的训练中。
那么,这些公开资料具体包括哪些内容呢?
例如互联网、网络和其他活动信息,包括搜索字词、应用程序和浏览器与Google服务互动的相关信息,以及在第三方网站和应用程序中使用Google服务等。
换言之,不仅仅是以前已经公开的的内容,包括谷歌文档、或者公开到网上的一些包含个人信息的帖子,也有可能被Google收集用于大模型培训。
当然,这些内容目前还仅限于"公开信息"。
像Google提供的Gmail等电子邮件服务,应该还是不会被爬进数据里。
而且谷歌在隐私权政策中也明确表示,在其他原因如安全威胁防范、信息审核、服务维护、个性化广告或法律等情况下,同样可以使用这些个人或公开信息。
然而,谷歌为什么要在这个节骨眼上更新这一政策呢?
“AI正挑战文字版权”
也许是和Reddit和推特等公司的“限流”操作有关。
首先,今年4月,Reddit宣布开始对接入API的公司收费。
该公司首席执行官认为,Reddit的数据库很有价值,但是他们不想把这些有价值的内容免费提供给大型科技公司。
随后,推特也开始以“不想让AI公司白嫖数据”的理由,来给推特限流,未验证用户的日浏览量只有600,验证后增加到6000。
这一系列政策对用户和第三方工具造成了严重的影响,比如Reddit引发了大规模的讨论论坛抗议,很多版主直接关闭了自己管理的论坛,以抗议Reddit,很多人也在推特上声讨,甚至有网友说“推特被杀死了”。
但无论如何,让AI白嫖数据现在是一个不可忽视的矛盾。
有网友对谷歌AI抓取数据表示质疑:
为什么之前互联网如搜索引擎也有爬取数据一类的操作,但人们却偏偏对“AI抓取”感到抗拒。

有网友回应称:
本质上还是版权的问题。如果只是引用受版权保护的材料,那么不一定侵犯版权,但如果用AI对有版权的内容进行“搅拌清洗”,而且这事儿合法化了,那么本质上版权已死。

正是由于这个原因,他对这件事持悲观态度:
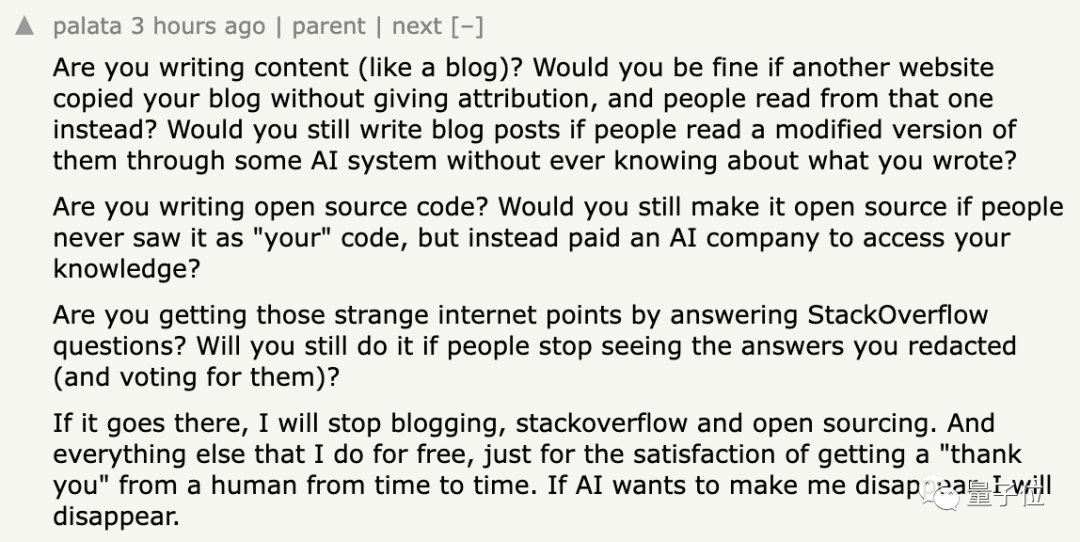
如果有人在不标注来源的情况下复制了你的博客,或是将你的开源代码拿去做付费服务,又或是将你在StackOverflow上的答案用作答题方法,你能接受这些情况发生吗?
我之前做的一切都是免费的。但现在如果AI想让我消失,那我就会消失。
当然,一些网民已经接受了这一政策的退出,警惕大家自身的防范意识不可或缺:
细读新政策,注意我们泄露了多少信息到网上。

那么,这件事你怎么看?
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com