
苹果打“道德牌”,AI训练声明或成“免责声明”




志在打造“超级智能”的Meta成了当下硅谷的焦点,AI科学家的“转会费”堪比足球明星。其中,以2亿美元身价加盟Meta的苹果基础模型团队负责人庞若鸣 (Ruoming Pang) 最为知名。
日前,苹果公开了庞若鸣在该公司的最后一份成果《Apple Intelligence Foundation Language Models – Tech Report 2025》,展示了2025年后在基础模型领域的技术革新。

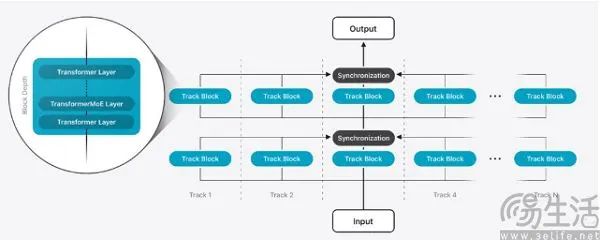
论文显示,他们持续优化端云协同的混合模型。30亿参数的端侧模型Apple On-Device内存占用降低约37.5%,让iPhone在不增加内存的情况下,用户运行端侧模型时能打开更多应用。云端的Apple Server模型获得“并行轨道混合专家”,在保持智能水平的同时,提升了效率与扩展能力。
除了模型技术解析,论文最大亮点是Apple Intelligence训练未使用任何非法从网络抓取的数据。苹果强调训练数据包括授权数据、公开或开源数据集,以及通过Applebot网络爬虫抓取的公开信息,还承诺不抓取明确反对数据抓取的出版商内容。
美国加州法院裁定AI初创企业Anthropic使用受版权保护作品训练AI大模型符合“合理使用原则”,这让AI厂商如脱缰野马。该原则曾庇护互联网产业,如今惠及AI行业。
但在版权方看来,AI行业对版权内容的“合理使用”破坏力更强。上世纪90年代互联网萌芽,谷歌数字图书馆项目扫描图书资源并电子化,互联网厂商合理使用版权内容还需费一番周折。
随着互联网经济发展,版权方为传播内容进行数字化转型,将内容搬到网上,却使内容暴露在AI厂商爬虫面前。由于技术差距,版权方面对AI爬虫几乎无计可施,而法院又偏向AI厂商。此时,苹果与其他AI厂商划清界限,称将遵循最佳伦理抓取实践,遵守robots.txt协议,允许网页所有者选择是否让内容用于训练苹果生成式基础模型。

此外,苹果承诺网站方拒绝Applebot不会被“刁难”,网页所有者能细致控制Applebot访问页面及使用方式,页面仍可出现在Siri和Spotlight搜索结果中。显然,这一声明会为苹果在版权方面赢得不少好感。
然而,在AI从业者看来,苹果此举是在为自己开脱,也为其在AI领域可能长期追赶打预防针。业内都知道,2023、2024年AI大模型技术突飞猛进,性能大幅提升,是AI厂商消化互联网三十年积累的结果。
像Common Crawl、The Pile、维基百科等公开或开源数据集,已被AI厂商用得差不多了,苹果强调使用“获得授权的数据”。虽说尊重出版商权益是好事,但并非每个出版商都愿给苹果机会。
现有开源数据集几乎都用于AI大模型预训练,苹果只能指望出版商新内容。可哪些出版商会愿意数据被抓取用于AI训练呢?
互联网内容平台方面,除Reddit外,全球主流平台基本都有AI业务。马斯克的X有xAI,Instagram、Facebook、Thread属Meta,YouTube背后是谷歌。

传统出版商情况更复杂。AI助手分走搜索引擎流量,其整合内容的特性让出版商对新闻编辑和采集方式的改变越发不安。有人会问,新闻集团、Axel Springer、康泰纳仕和美联社等与OpenAI达成了协议。
但OpenAI和苹果不能相提并论。这些因作品被擅自使用而愤怒的出版商,是无奈接受OpenAI的事后补偿。而且,谷歌以AI Mode改造搜索引擎,搜索市场格局改变。AI Mode让用户无需点击链接获取信息,谷歌降低了对外部网站的引流。
AI Mode减少用户访问网站,降低了出版商广告变现能力。OpenAI推出SearchGPT,给了出版商谷歌搜索的替代选项,而苹果没有这样的筹码,Spotlight作为搜索引擎都不够格,更不用说AI搜索了。
苹果缺乏获取授权数据的筹码,公开数据又已耗尽,所以这个声明现实意义不大,更像“免责声明”。
本文来自微信公众号“三易生活”,作者:三易菌,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com