
突破英伟达垄断:AI产业的另一条突围之路






本文来自微信公众号: 01Founder ,作者:一直在路上的Max
2006年冬天,黄仁勋做了一个被华尔街 deemed 极其荒唐的决策:要求英伟达全系列产品必须支持全新的CUDA技术。
为了这个在当时看不到任何盈利前景的项目,这家以显卡销售为核心业务的公司,年研发投入直接飙升至5亿美元,利润常年徘徊在盈亏线附近。
股东怒斥,媒体嘲讽,说这是对不存在的市场盲目砸钱,可黄仁勋始终没有停下脚步——他骨子里本就带着赌徒的偏执。
后续的发展所有人都耳熟能详:如今硅谷科技巨头抢英伟达显卡,几乎要挤破头。
马斯克一口气往得州机房塞了十万张英伟达显卡,转头就能以每月12.5亿美元的价格把算力租给Anthropic;扎克伯格甚至会在Meta财报里主动炫耀,公司已经囤了三十万张H100。
大模型行业如今奉信一条简单粗暴的“规模法则”:模型越大性能越好,能拿到的算力越多越有优势。
在这套规则下,英伟达拿走了AI产业绝大多数利润:云厂商高价买下显卡,再把算力切割成小块,按Token向创业者和普通用户收费;每一次AI生成内容,本质上都是在消耗英伟达的算力,都是给硅谷的这座AI王座上供。越来越多从业者开始感叹:整个行业都被英伟达卡了脖子。
这样的垄断看似是死局,但已经有一批人站出来,想要打破现状。
PART.01
算力突围:啃下生态这块硬骨头
要反抗英伟达的垄断,第一枪必须打在最核心的算力芯片上。
前段时间华为发布的芯片论文刷遍全网,国产芯片领域也不断传出突破消息,资本市场反应热烈。但如果问问真正在大模型一线开发的工程师,大多会得到一个残酷的答案:黄仁勋脚下,还藏着一条深不见底的护城河——那就是CUDA生态。
英伟达用了整整15年时间,吸引全球数百万开发者在这个生态里开发、调试,终于打磨出了一套流畅成熟的开发环境,成为AI行业默认的基础设施。
平心而论,如今华为昇腾和其他国产芯片已经在硬件参数上追上了国际水平,但因为缺少成熟的软件生态,模型部署后经常出现运行中断、崩溃的问题,哪怕算力参数达标,实际体验也差强人意。很多手握资金的国内大厂,最终还是只能通过特殊渠道高价求购英伟达显卡。
但再硬的骨头,总得有人啃。在这场摆脱英伟达依赖的算力突围中,已经有少数中国企业选了最艰难的那条路。比如在硅谷都声名远扬的DeepSeek,为了让大模型稳定跑在华为等国产芯片上,直接抽调了核心工程团队,逐行重写底层算子。
这种在技术细节里死磕的代价,就是整个模型的发布进度被大幅推迟。这当然称得上是“孤勇者”的故事,但也暴露出一个现实问题:如果国产大模型只能靠顶尖工程师拼时间、拼体力,去填英伟达15年攒下的生态坑,我们要多久才能真正实现翻盘?或许,我们需要换一条赛道。
PART.02
换道端侧:把智能装进终端设备
硬件端的突破固然重要,但如果只盯着算力硬件,还不足以彻底打破英伟达的垄断。翻一翻科技巨头的财报就能发现一个荒诞的现状:无数产品经理和高管天天绞尽脑汁,想着怎么让用户多对话、多生成内容,怎么多卖API、多卖会员,大厂为了抢市场打起了近乎赔本的API价格战,可最后大部分利润,还是流进了英伟达和云厂商的口袋。说白了,整个AI行业都在给黄仁勋打工。
黄仁勋和云厂商构想的终极商业模式,就是把所有大模型都锁在云端数据中心,让用户永远为Token付费、为算力付费——只要模型还在云端运行,计费表就会一直转下去。哪怕API价格战打得再激烈,只要英伟达显卡还需要供电,AI服务的边际成本就永远不可能降到零。
要彻底终结这种垄断,必须换一个战场,换到英伟达显卡触及不到的地方:那就是端侧模型。
所谓端侧模型,就是直接在用户自己的设备上运行大模型,把AI智能直接放进你口袋里的手机、桌上的笔记本,甚至是手腕上的智能手表。
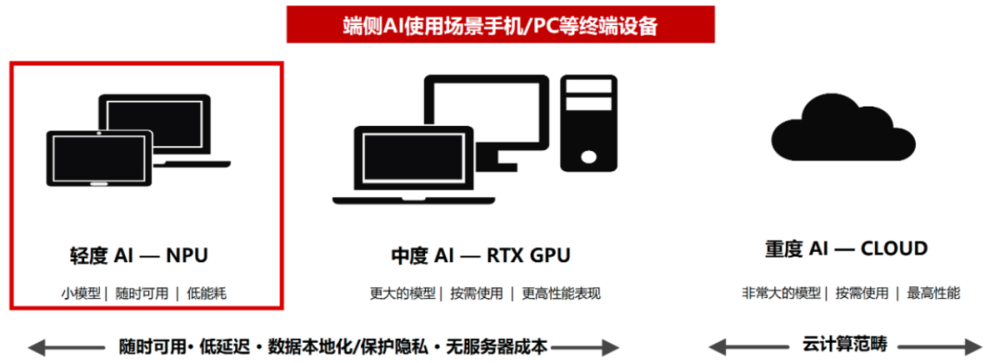
端侧模型能带来两个颠覆性的优势:
第一就是彻底降低成本。一旦模型在本地设备运行,云端按Token计费的模式就直接被淘汰了。用户不需要每次提问都算着成本控制内容长度,哪怕让AI读几十万字的研报、写一整夜的代码,边际成本都是零,没有中间商赚算力差价,更不需要给任何厂商交算力过路费。
第二是彻底解决隐私问题。AI巨头再也没办法通过云端收集用户数据,企业的机密报表、个人的私密内容,全都牢牢锁在用户自己的设备里,物理隔绝外人访问;哪怕你在没有信号的高铁隧道里,AI依然可以正常运行。
但这条路走起来格外艰难。过去两年,行业里曾经涌出一大批喊着要做端侧大模型、把AI装进手机的团队,可资本是极度现实的:摸爬滚打之后大家发现,做端侧大模型不仅要和硬件的性能极限死磕,而且利润空间极薄,更重要的是,它直接打碎了云端按API收租的完美商业模式,所以很快大部分团队就散去了,大家又转头挤回云端,继续卷千亿、万亿参数的云端大模型。潮水退去之后,端侧赛道变得格外冷清,全球范围内还在坚持做端侧大模型的团队寥寥无几。
目前来看,谷歌Gemma团队、微软Phi团队、阿里通义千问Qwen团队都在布局端侧模型。有意思的是,连卖显卡的英伟达,自家研究院都曾发论文公开表示“小语言模型才是未来方向”。但对这些巨头来说,端侧模型更像是完善产品布局的防御性布局,要让他们亲手砸碎自己躺着赚钱的云端收租盘,难度实在太大。
PART.03
换道超车:自己修出一条新路
前段时间华为的芯片论文让整个行业沸腾,很多人都觉得我们终于看到了掀翻英伟达帝国的曙光。但直到今天,黄仁勋依然穿着他标志性的黑皮衣,站在硅谷AI产业的顶端。
很多人都在问,中国大模型什么时候才能真正实现超越?答案或许从来都不是谁能买到更多显卡、谁能砸更多钱堆出参数更大的模型。真正的超越,从来都是发生在游戏规则被改写的时候。
大模型的上半场,本质上是靠工程师堆代码的手工作坊时代,是比拼买卡囤卡实力的“冷兵器时代”,大家比的是谁家底厚、能从黄仁勋手里拿到更多芯片。但到了下半场,游戏规则已经变了。
在这场摆脱英伟达垄断的突围战里,华为在最底层的芯片硬件上破冰,DeepSeek在算法层面挖潜国产算力,这些玩家没有盲从巨头们“越大越好”的逻辑,没有在旧规则里疯狂内卷,而是选择直接掀掉旧牌桌,开一条新赛道。
多年以后回头看,现在发生的这一切,很可能会成为AI产业静水流深的分水岭。现在硅谷依旧热闹,纳斯达克的指数依然在上涨,黄仁勋的饭局上还是坐满了求购芯片的科技大佬,那个穿皮衣的男人依然站在产业顶端受万人膜拜,巨头们还是在为云端算力杀得不可开交。但在他们看不到的地方,旧秩序的基石已经被悄悄撬动。
在那条拥挤、昂贵还随时可能被卡脖子的英伟达高速路旁边,一群想要突破垄断的创业者已经不再排队等待,他们转过身,开始自己铺一条全新的路。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com