
DeepSeek V4评测曝光:距美国顶尖模型差距8个月,国产AI已迎来百花齐放






本文来自微信公众号:特大号,作者:小黑羊
在DeepSeek发布全新V4版本模型后,美国官方AI评测与标准机构CAISI对外放出了一份针对性评测报告。
根据这份评测给出的结果,当前DeepSeek的能力,已经落后于美国顶尖闭源大模型大约8个月。
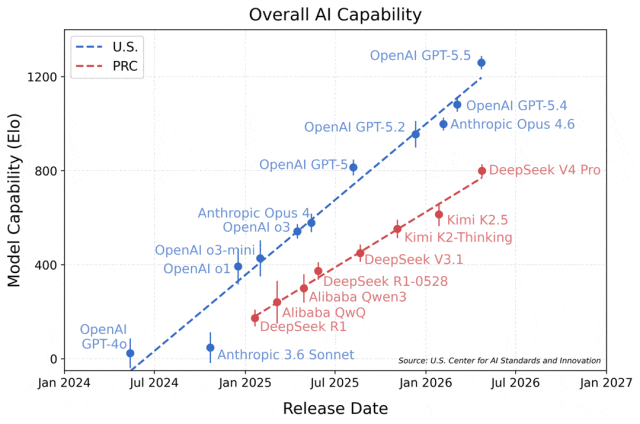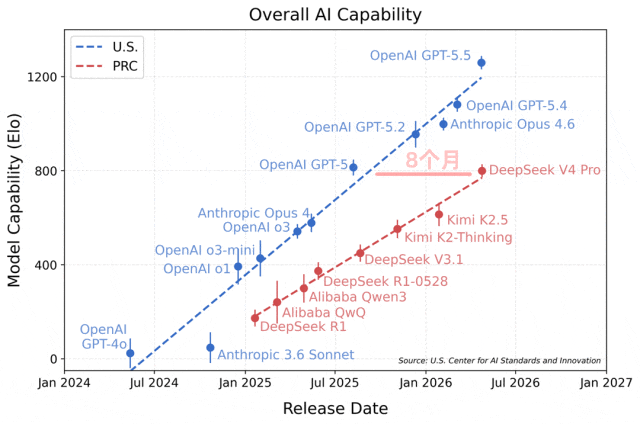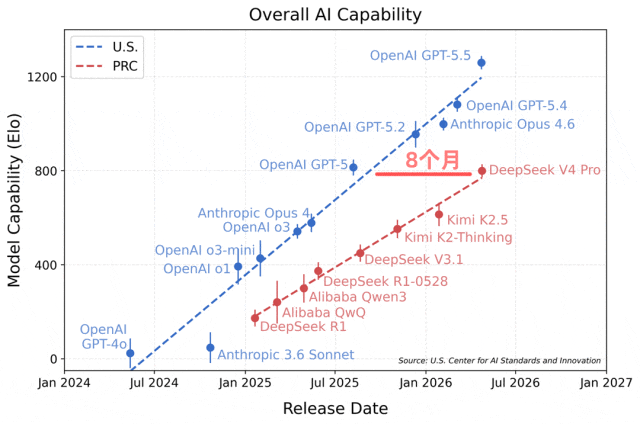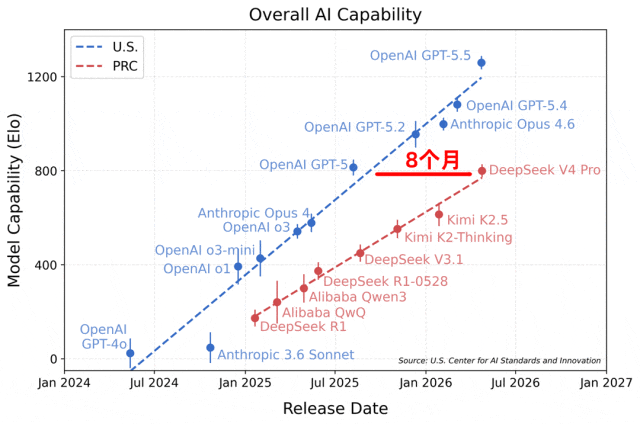
评测给出的这张趋势图其实很能说明问题:图中横轴是各个模型的发布时间,纵轴则是模型的综合能力评分。
从图中能很清楚看到,刚刚正式发布的DeepSeek V4 Pro,整体综合能力只相当于美国去年8月推出的GPT5的水平。
更值得关注的是模型能力迭代曲线的斜率,美国头部模型的曲线明显更陡峭,这也意味着两者之间的差距还在持续被拉大。
DeepSeek的差距到底出现在哪些地方?
看这份细分能力评分表就能一目了然。
DeepSeek在数学、自然科学、基础代码能力这些维度,其实和GPT、Claude等美国顶尖模型处于同一水平,但是在网络安全、复杂工程落地、抽象推理这类领域,差距就非常明显了。
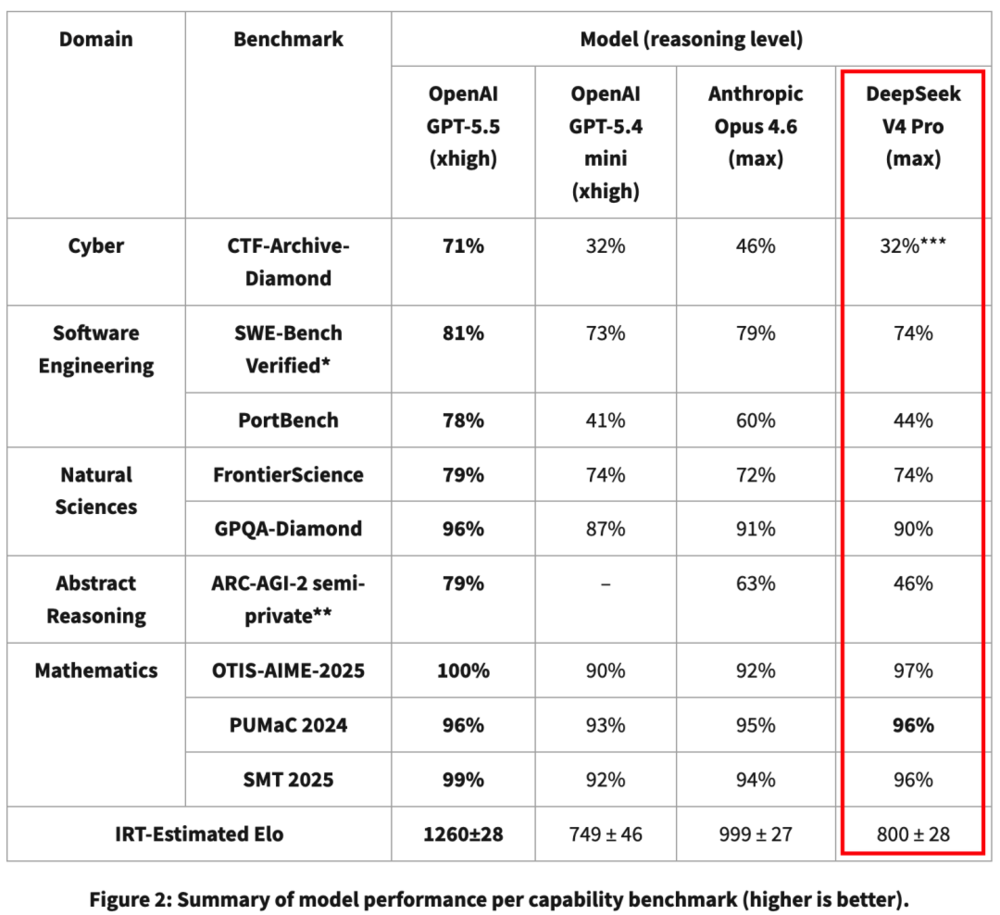
所以也有人形容,DeepSeek更像是大家所说的「小镇做题家」:理科基础扎实、刷训练数据效率高,基础代码编写能力也不错,但一进入复杂的真实实战场景,能力短板就会凸显出来。
而对企业级落地场景来说,不管是代码开发还是智能体应用,想要真正投入使用,都非常依赖复杂软件工程能力和抽象推理能力。
另外还有网络安全能力,本身就非常依赖真实实战积累,在这个领域DeepSeek的短板确实相当突出。
这些差距的形成,其实是多方面因素导致的↓
首先一点,我们必须承认,目前国内在训练算力和硬件生态方面,确实和头部水平存在代差。
就比如数学能力,完全可以通过高质量合成数据搭配强化学习快速提升,就像学生刷题一样,只要多练、找对方法,很容易拿到好成绩。
但复杂工程、网络安全、智能体这类任务,不仅需要训练模型本身,还要搭建大量真实运行环境、自动评测沙盒等配套设施,这就相当于实战演练,早就脱离了书本课堂的范围,也远比刷题更消耗算力和工程资源。
第二点,缺少高质量的真实实战数据积累。
数学题、竞赛题、科学问答这类数据,本身很容易做标准化处理,获取门槛不高。
但网络安全和复杂软件工程不一样,这类领域需要大量真实代码仓库、项目issue、依赖运行环境、完整漏洞链路、实际调试过程这类数据,这种真实工作流程数据的积累,我们目前还差得比较多。
第三点,可以说成也MoE,败也MoE。
MoE架构的模型确实有很多优势,比如同等参数量下性价比更高,但面对高度连续、长链路、跨领域的任务,MoE架构会面临更大的挑战,输出稳定性不如稠密模型。
从某种程度上来说,传统稠密模型的综合能力会更强,而国内模型选择MoE架构其实也和第一点原因息息相关——毕竟我们确实缺算力,MoE是更贴合现有条件的选择。
第四点,开源其实是一把双刃剑。
闭源模型的优势在于它是黑盒,可以把推理成本、系统复杂度、多模型组合方案、工具链、检索系统、隐藏推理策略这些优化都放在API后端,用户看不到。
甚至说不定当用户提出安全需求的时候,闭源模型背后还有专业的人工安全专家提供支持。
简单来说,闭源黑盒的内部可以隐藏很多外人不知道的组合优化手段,比如多模型路由调度、工具执行器、安全过滤模块等等。
但像DeepSeek这种开放权重的开源模型,几乎是把所有能力明明白白摆出来,大家能直接接触到的基本上就是原生裸模型的能力,没办法像闭源模型那样,把大量后端优化方案打包进去提升表现。
这也就导致,在智能体、网络安全、复杂工程这类任务上,闭源黑盒模型天然就更容易拿到更高的评测分数。
最后还有两点需要理清↓
第一,我们不需要过度盲从这份报告的结论,还要看评测机构的立场和评测维度偏向。
CAISI的这份评测本身就带有比较明显的美式叙事偏向,更侧重网络安全、软件工程、抽象推理这些领域。
如果换一个评测维度,看中文场景适配、企业私有化部署、低成本推理、国产硬件适配、开源生态价值这些方向,DeepSeek的优势会立刻显现出来。
第二,不用只把目光盯在DeepSeek身上,现在能代表国产AI力量的大模型,已经可以组团出战了。
过去一年里,DeepSeek是国产开源大模型的一面旗帜,吸引了所有人的目光,也扛着「国产模型不能输、开源模型不能输」的压力,负担实在太重了。
但进入今年之后,DeepSeek肩上的重担其实可以慢慢卸下来了,一大批国产大模型已经开始接棒,共同扛起国产AI发展的大旗。
Kimi2.6、GLM5.1、Mimo2.5、Minimax2.7、Qwen3.6…越来越多的国产模型已经成长起来。
国产开源大模型也从之前DeepSeek一枝独秀的阶段,走到了现在百花齐放的新阶段,各个模型都有自己的特色和优势。
而且这一波国产模型的集体成长,和2024年的百模大战不一样,经过洗牌留下来的这些模型,每一个都有过硬的实力,不管是实战表现还是市场口碑,都不输给DeepSeek。
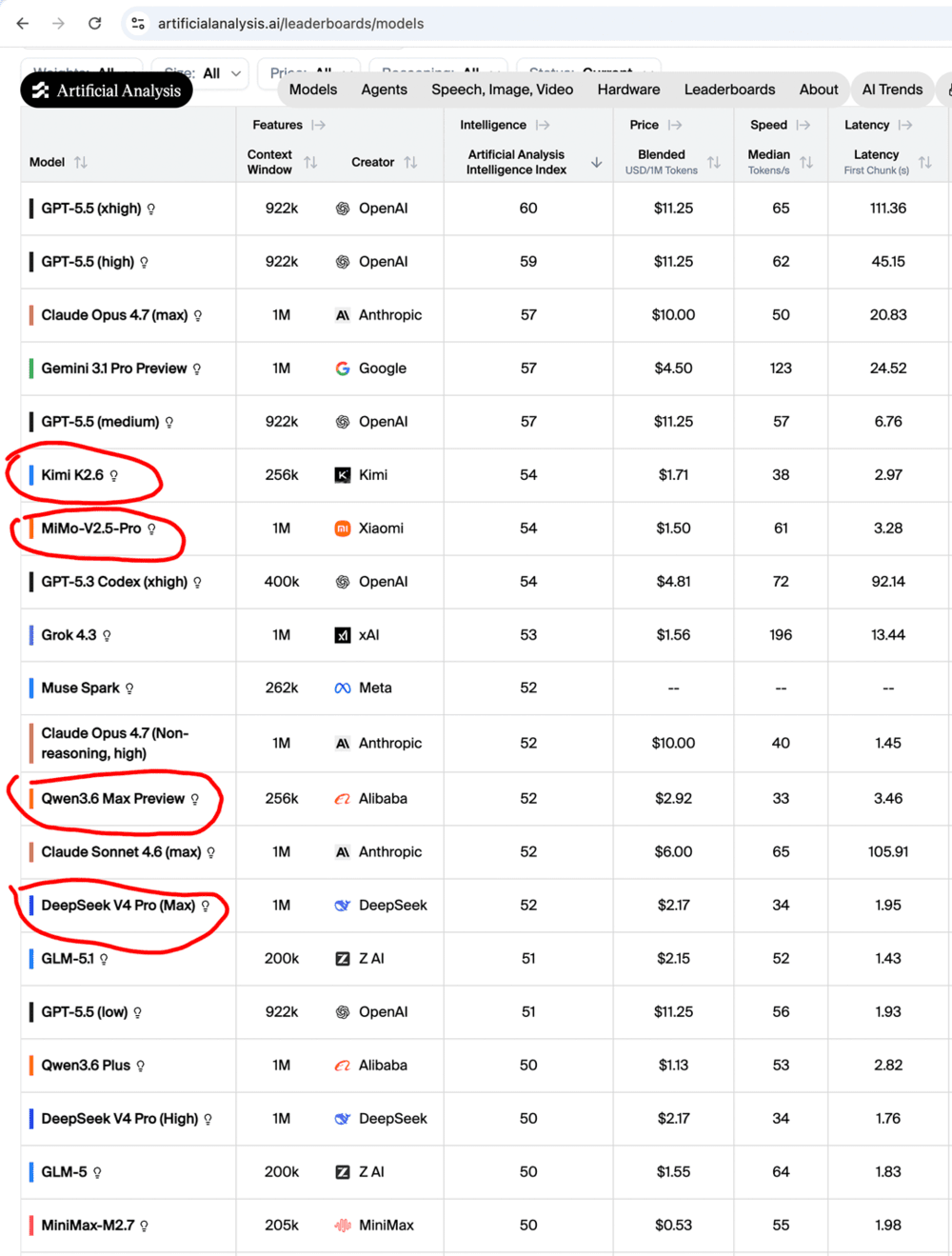
比如在Artificial Analysis的模型性能总榜单里,DeepSeek V4 Pro仅仅排在国产开源模型的第四位,Kimi k2.6、Mimo-V2.5、Qwen3.6的排名都在它前面。
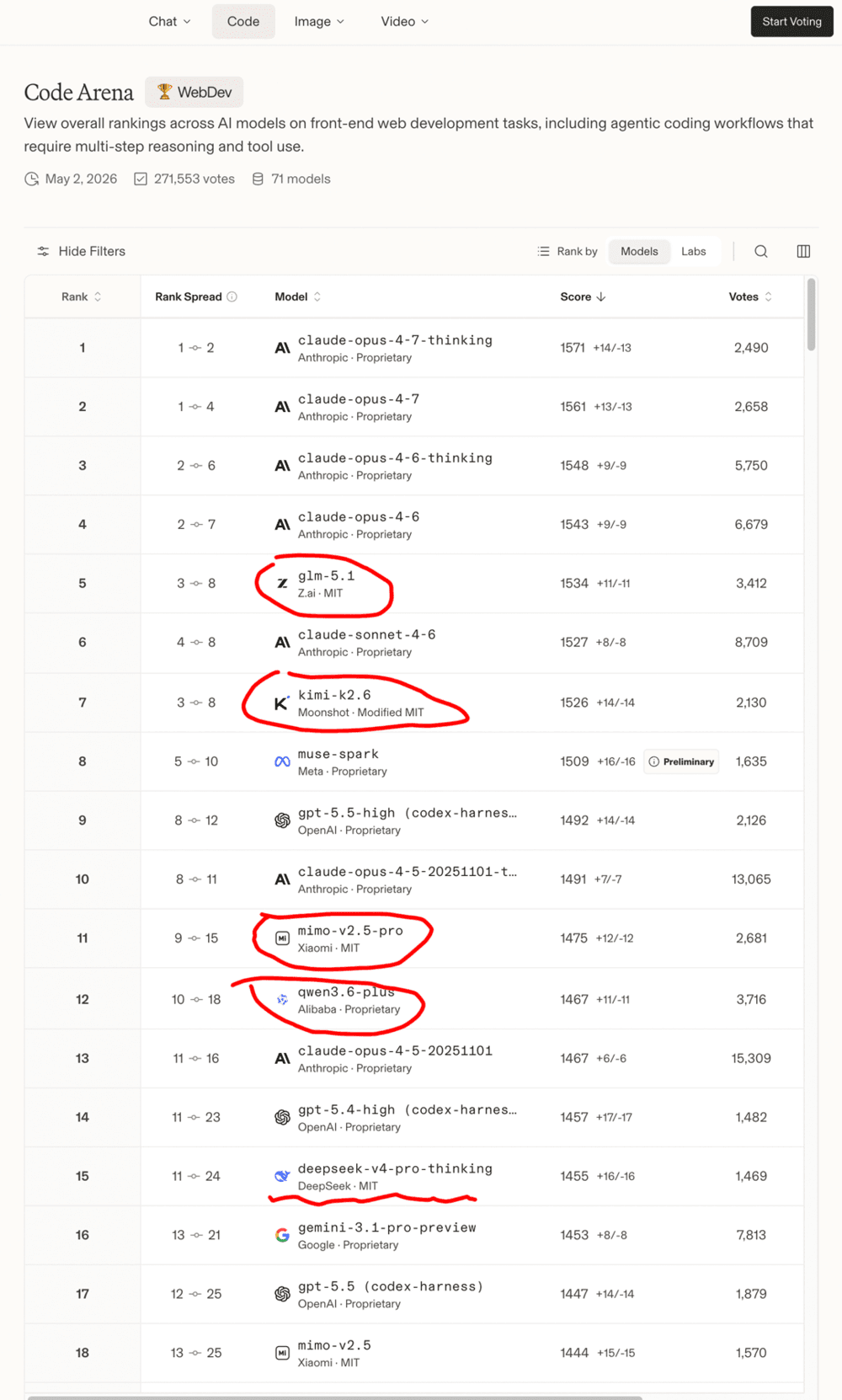
再看另一份LmArena的代码模型榜单,DeepSeek V4 Pro也只排在总榜的第15名。
国产模型里GLM-5.1排在第5、Kimi-k2.6排在第7、小米2.5 Pro排在第11、Qwen3.6-Plus排在第12,表现都比DeepSeek V4 Pro更好。
这也让人想起DeepSeek V4发布时,官方在公告结尾引用的荀子名句↓
「不诱于誉,不恐于诽,率道而行,端然正己。」
当DeepSeek慢慢走出被神化的位置时,恰恰就是国产大模型各自突破、集体向前迈进的时候。
静水流深,未来可期!
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com