
OpenClaw风暴席卷中国:大模型下半场的暗战与机遇






本文来自微信公众号:全天候科技,作者:全天候科技
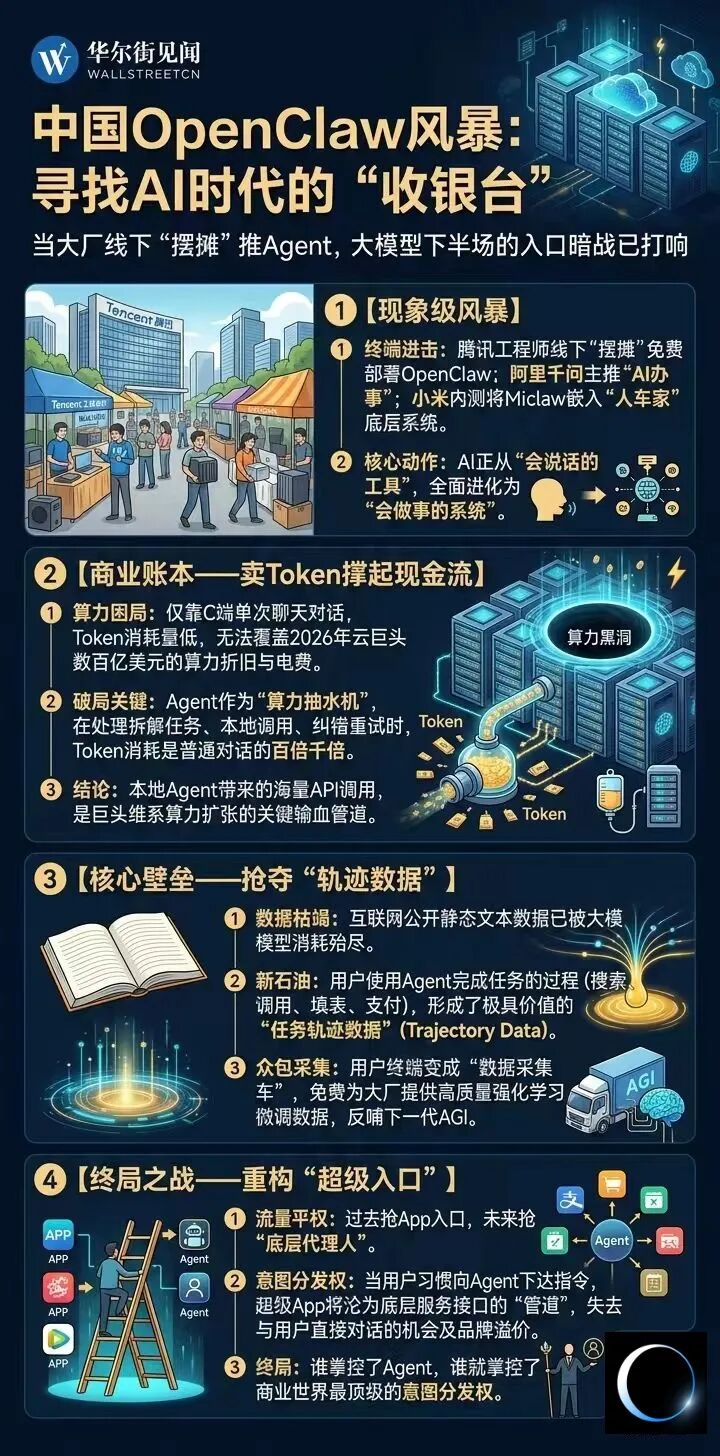
3月初的深圳腾讯总部楼下,一场特殊的“集市”悄然展开——腾讯工程师们在大厦北广场摆起摊位,免费为用户安装名为“龙虾”的OpenClaw。
长长的队伍里,有人抱着NAS存储设备,有人带着MacBook笔记本,还有人拎着迷你主机,场景酷似十年前极客们扎堆刷安卓系统的聚会。
事实上,不止腾讯,国内不少科技大厂都在密集布局类似的“龙虾”项目。
小米已启动MiclawAgent的内测工作,计划将AI代理嵌入“人车家全生态”系统,让手机、汽车、电视及各类家电都成为AI执行任务的节点。
当云厂商开始线下“摆摊”推广,终端大厂着手将Agent融入操作系统,这场由“龙虾”引发的风暴,已然拉开了大模型下半场竞争的帷幕。
这并非简单的AI工具之争,而是一场围绕下一代“超级入口”展开的暗战。
一
Token背后的现金流密码
当前,所有大模型玩家都面临一个共同困境:单纯的“Chat”对话模式,难以支撑健康的商业模式。
过去两年,国内云厂商与科技巨头陷入长期军备竞赛,成千上万张高端算力卡被批量部署到数据中心。2026年,字节、阿里、腾讯的资本开支合计超600亿美元。然而,若用户不调用算力,这些设备就会闲置,每天产生高昂的折旧成本。
现实是,仅依靠C端用户的对话交互,既无法消耗庞大的算力储备,也难以从习惯免费服务的用户群体中获得收入。
用户偶尔让AI写邮件、画图,单次交互消耗的Token量极低,远不足以覆盖底层算力集群的折旧与运营成本。要让昂贵的算力产生实际价值,巨头们急需一个能持续、自动消耗算力的“Token黑洞”。
OpenClaw这类本地部署的Agent恰好扮演了这一角色。
当用户下达复杂指令时,OpenClaw会拆解任务、联网搜索、调用本地软件、识别错误并自我纠正重试。每一个步骤都需向云端API接口发送请求,一个复杂任务的Token消耗量可达普通对话的百倍甚至千倍。
一位AI分析师向华尔街见闻表示:“中国开源模型被OpenClaw采用,主要得益于高性价比。相比海外竞品,低成本促使API调用更频繁,直接转化为云厂商的现金流,避免了巨额算力投资的浪费。”
这便是腾讯等云厂商愿意投入人力线下“摆摊”帮用户部署开源Agent、阿里强推OpenClaw一键上云的原因——每一次部署,都在用户设备或云端埋下一台24小时运转的“算力抽水机”。
无论前端运行的是否为开源模型,只要推理和工具调用的API指向自家云服务,海量微小请求最终会汇聚成可观的B2C与B2B现金流。在资本市场对大模型商业化变现要求日益严苛的当下,Agent带动的API流水,成为巨头维系算力扩张的关键“输血管”。
二
轨迹数据:大模型的“新燃料”
越过现金流的表层逻辑,巨头力推本地Agent的第二层目标,触及了大模型发展的核心瓶颈:高质量训练数据的枯竭。
过去几年,大模型竞争的核心资源是算力与训练数据。但随着模型能力提升,另一种资源逐渐凸显重要性:任务轨迹数据。
业内共识是,互联网上的高质量公开文本数据(如维基百科、新闻、书籍论文)已被各家大模型“挖掘殆尽”。若仅依赖这些静态文本,大模型只会沦为更“博学”的“书呆子”,难以向通用人工智能(AGI)迈进。
下一代大模型需要什么?需要理解人类在数字世界中的“行动逻辑”,这便是业内渴求的“任务轨迹数据”(Trajectory Data)。
当用户让AI完成任务时,AI会经历理解需求、搜索信息、调用工具、填写表单、完成支付等一系列步骤,每个动作都留下记录,构成完整的任务链路。
对Agent模型而言,这类数据比普通文本更具价值,因为它反映了现实世界的行动逻辑。
而这类数据恰恰是巨头们此前难以获取的——它们隐藏在割裂的软件、封闭的App和企业内网中,即便拥有庞大爬虫生态的搜索引擎也无能为力。
部署在用户终端的OpenClaw与系统级的Miclaw,就像深入“数据敌后”的探测器。
OpenClaw中国社区经理Alan Feng指出:“用户安装OpenClaw后,常期待它能‘魔法般’自动完成任务,但真正的价值在于定义清晰的任务流程。轨迹数据的反馈能让模型持续优化,厂商借此补充数据,提升代理能力。”
当用户在本地运行Agent执行操作时,Agent会记录下用户的操作意图与软件交互轨迹。国内大厂密集推广Agent应用,本质上是一场分布式、规模空前的数据众包。
用户以为自己免费获得了AI劳动力,实则在指导、纠正Agent的过程中,免费为巨头提供了最高质量的强化学习微调数据。
这些“轨迹数据”回流云端后,将成为大厂训练下一代具备强逻辑推理、强执行能力的Agent大模型的核心壁垒——正如特斯拉通过数百万辆电动车收集真实路况数据,反哺FSD自动驾驶算法一样。
阿里Qwen项目内部人士向华尔街见闻透露:“中国在新范式上领先的概率低于20%,但通过Agent轨迹数据,阿里能快速迭代模型,缩小与国际的差距。”
如今,巨头们正将用户的电脑和手机,变成AI时代的“数据采集车”。谁掌握更多轨迹数据,谁就能率先训练出真正“长出手脚”的超级模型。
从这个角度看,大厂推广本地Agent并非只为推出新工具,而是在争夺AI时代的操作入口。
三
入口战争:从App到Agent的轮回
中国互联网曾经历多轮入口战争:早期门户网站争夺首页流量;搜索时代,百度成为信息入口;移动互联网时代,App崛起,微信、支付宝、抖音成为流量中心。
AI的出现正在重构这一格局。
阿里千问持续投入“AI办事”,让用户一句话即可完成下单;小米内测Miclaw,将其深度植入手机底层系统。这些动作释放的信号是:未来用户与数字世界的交互界面将被彻底重构。
当用户习惯用一句话表达需求,操作路径将发生改变——用户不再主动打开App,而是将任务交给AI,由AI决定使用哪个平台、调用哪个服务、完成哪条支付链路。
在此体系中,App的地位将发生变化:它们依然存在,但更多成为服务节点。真正的入口,是那个帮助用户完成任务的Agent。
在新语境下,“抢App入口”已显落伍。真正的战争,是成为直接听命于用户、掌控全局的“底层代理人”。
若巨头能让自家Agent占据用户终端,便掌握了商业世界的顶级权力——意图分发权。它可轻易将外卖订单导流至关联企业,将差旅需求导入自身支付生态。
在Agent构建的新“围墙花园”里,曾经的超级App将沦为提供底层服务接口的“管道”,彻底失去与用户直接对话的机会,更丧失品牌与流量溢价。
这也是大厂对Agent高度敏感的原因——所有人都想成为控制Agent的平台。
四
风暴前夜:从“会说”到“会做”的跨越
OpenClaw的爆火或许只是一个信号。
真正的变革在于,AI正从“会说话的工具”向“会做事的系统”转变。过去两年,大模型行业的核心目标是提升智能水平;如今,越来越多公司开始思考:如何让AI获得行动能力。
一旦AI能稳定完成任务,互联网结构将发生巨变——许多应用可能退居后台,用户只需通过一个Agent,即可完成大部分数字生活操作。
在这样的世界里,Agent将成为连接用户与所有服务的新操作层。
回顾技术史,每一次平台级变革都始于不起眼的开端:Android最初只是极客刷机的系统,微信公众号刚出现时仅是简单的内容工具,小程序推出时更像轻量网页。
但这些产品后来都成长为新平台。
若未来AI真的进入Agent时代,今天的OpenClaw,很可能成为最早被记住的名字之一。
中国互联网正在经历的,或许正是这场风暴的前夜。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com