
0.5元的电为何能化身11元的出口数字服务?中国大模型Token调用量反超美国背后的秘密






中国大模型Token调用量首次超越美国,实现历史性逆转!这份成绩的价值,远不止表面数字那么简单。
首先得弄明白,Token到底是什么?简单来说,Token是大模型处理信息的最小单元,无论是你和AI聊天、让它写文案还是编代码,背后都在消耗Token。打个比方,要是把AI大模型比作一台高速运转的智能发动机,那Token就是它燃烧的数字燃料。
一个正常运作的中型AI团队,每月Token成本2万到10万美元很常见,要是业务量大、做自研、覆盖多场景或提供ToB服务,成本轻松就能达到10万到30万美元/月。而Token数值的大小,直接体现了AI大模型的实际使用强度、商业渗透力和全球影响力。
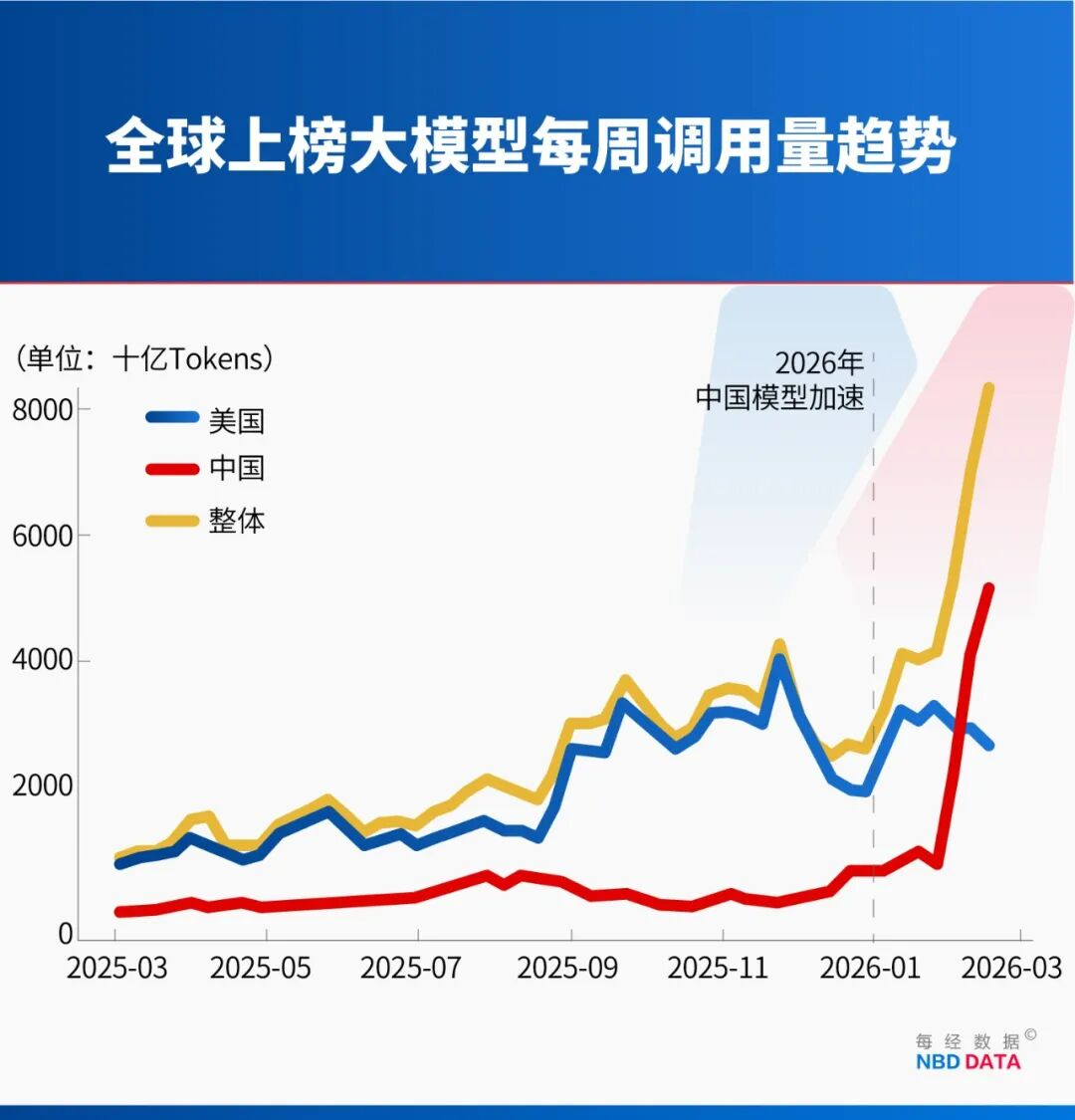
过去,这个指标被美国垄断,GPT系列、Claude、Gemini长期占据主导地位。但2026年2月,局面彻底改变,全球前十模型总Token消耗量突破28.7万亿,其中中国国产模型贡献14.69万亿,占比51.2%,首次实现全面反超。
在全球调用量前五的模型里,中国占了三个席位,MiniMax M2.5、月之暗面Kimi K2.5、DeepSeek V3.2分别位列第一、第二和第四。硅谷还出现了颇具讽刺意味的一幕:数据显示,全球最大的AI模型API聚合平台OpenRouter,近47.17%的用户来自美国。
这意味着什么?意味着中国Token的爆发式增长,不只是靠国内市场支撑,而是吸引了全球开发者。尤其是北美、欧洲的程序员,主动放弃GPT-5、Claude 4,选择中国模型。为什么全球开发者会集体“转向”?中国Token的核心竞争力到底是什么?
第一是价格优势,把Token卖得像白菜一样便宜。在性能相当的情况下,中国模型的调用成本只有美国的几分之一。月之暗面Kimi每百万Token调用价格约2.8美元,仅为Anthropic Claude的1/9;通义千问Qwen 3.5的价格更是只有Google Gemini的1/18,对于需要高频调用API的开发者来说,这简直是“白菜价”。
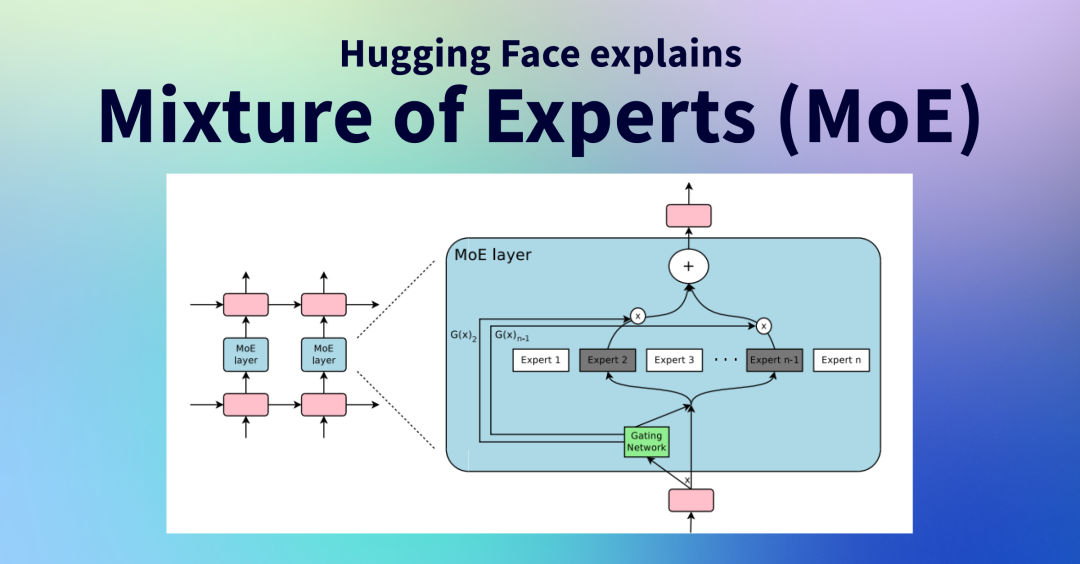
第二是性能过硬,不仅便宜还好用。实际上,在代码生成、长文本理解、多轮对话一致性等关键指标上,中国头部模型已经接近甚至在局部超过美国顶尖水平。以DeepSeek为例,它采用混合专家架构(MoE),推理时只激活关键参数,大幅降低了算力消耗。这项技术让中国模型在同等算力下能生成更多Token,进一步拉大了成本差距。
说到这里,可能很多人会把中国Token出海的逻辑,等同于普通廉价软件或产品的出海。但别忘了,AI算力的背后是电力。生成一个Token看似虚拟、轻如鸿毛,实则背后是数据中心里成千上万张GPU在高速运转,消耗着巨大的电力。而中国拥有全球最稳定的电网和最便宜的绿电。
我们可以算一笔账:国内一度电的工业成本约0.5元人民币,转化为Token后出口能卖到11元人民币,价值翻了22倍!这意味着我们不再只是出口电力设备,而是把电力“打包”成数字服务,完成跨境交付。
一个美国用户调用中国大模型API,数据跨太平洋传输,由中国的GPU消耗中国的电力完成推理。电力从未出境,但价值已经实现了出口。这不仅是技术上的胜利,更是能源优势的变现。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com