
中国AI模型调用量首超美国 四款大模型跻身全球前五







2026年2月,中国AI模型调用量迎来爆发式增长,首次超越美国。
全球最大AI模型API聚合平台OpenRouter的数据显示,2月9日至15日期间,中国模型调用量达4.12万亿Token,首次超过美国模型的2.94万亿Token。
2月16日至22日,中国模型周调用量进一步攀升至5.16万亿Token,三周内增长127%,而美国模型调用量降至2.7万亿Token。同时,全球调用量前五的模型中,中国占据四席,这一增长并非依赖单一产品,而是中国AI厂商集群式崛起的结果。
Token是AI处理文本的最小单位,相比用户数量,Token调用量更能反映模型使用强度、用户粘性及商业价值。
中国模型厂商凭借快速迭代和成本优势拓展全球市场,国产算力需求正呈指数级增长。
榜单变动:中国Token调用量首超美国 四款大模型占据前五
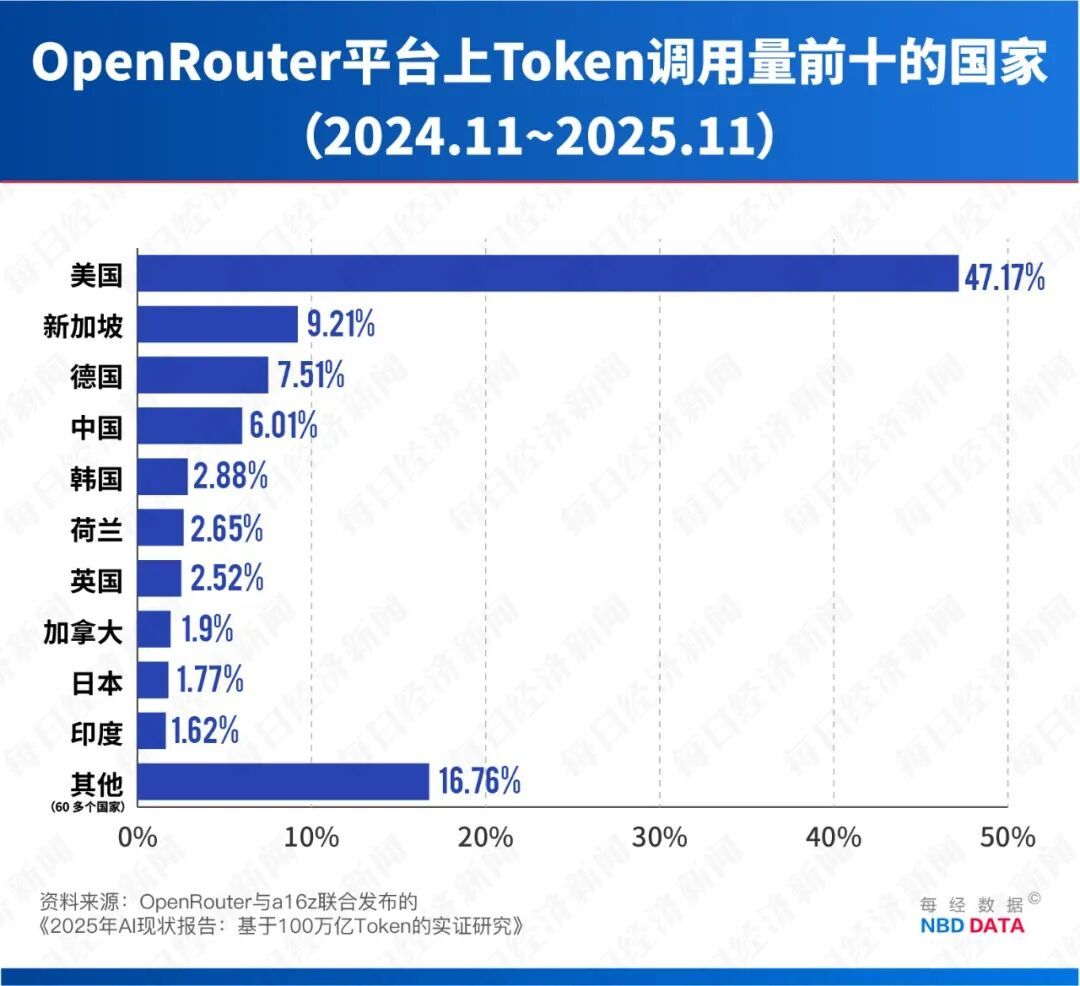
OpenRouter平台汇聚全球数百种大语言模型,拥有超500万开发者用户,是全球最大的AI模型API聚合平台。其API调用量数据被视为全球AI应用落地趋势的“晴雨表”,直接体现开发者选择及模型实际竞争力。
该平台用户以海外开发者为主,美国用户占比47.17%,中国开发者仅占6.01%,榜单数据更能客观反映中国AI模型的全球吸引力。
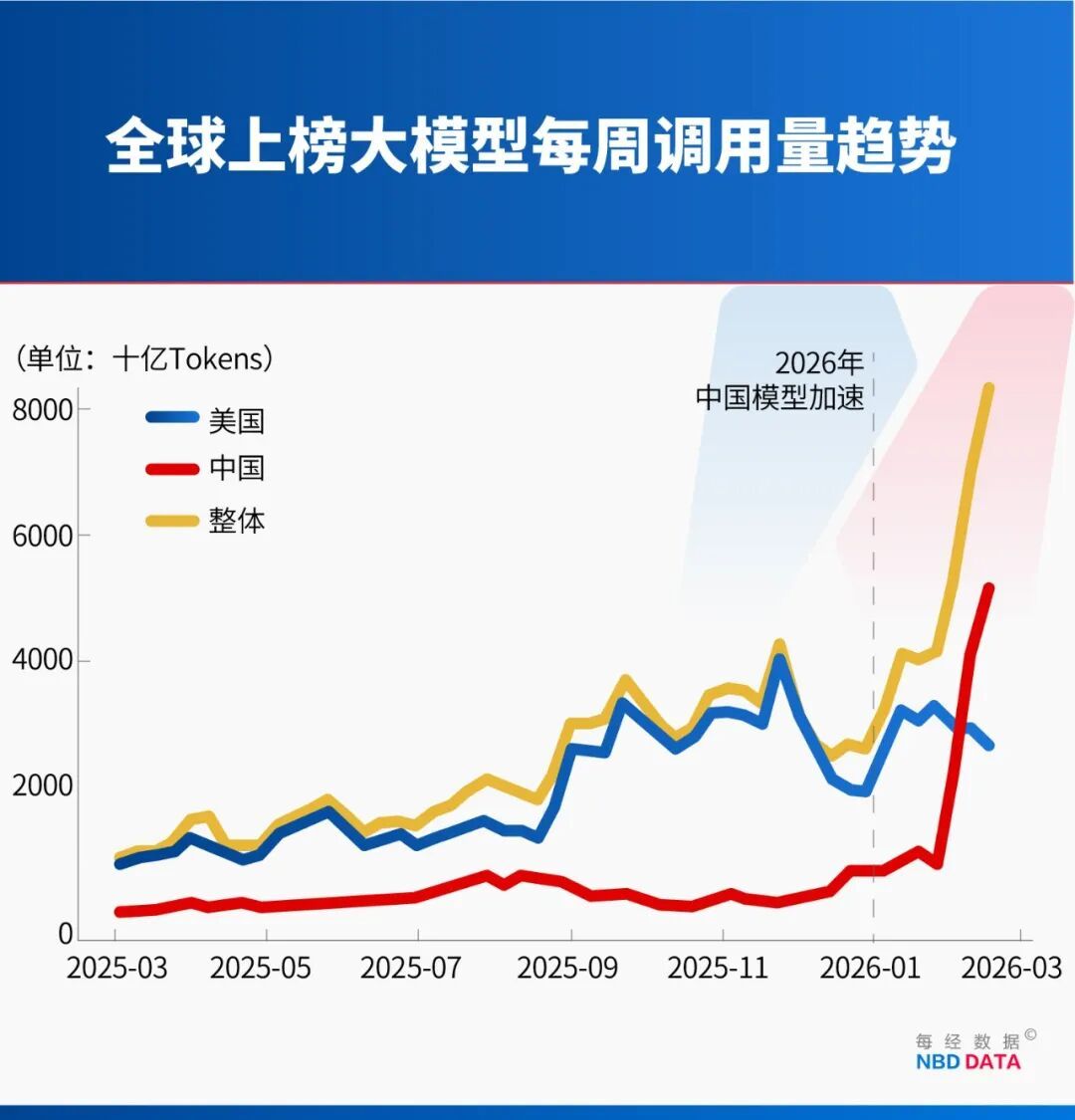
《每日经济新闻》记者梳理数据发现,全球大模型Token调用量过去一年增长显著。2025年3月3日至9日,平台前十大模型周调用量为1.24万亿Token;2026年2月中旬已达13.95万亿Token,不到一年增长超10倍。
2025年,美国模型是市场增长主力,周调用量占前十大模型总量近七成,中国模型占比不足两成。2026年,美国模型增速放缓,中国模型则快速增长。
2026年2月2日至8日,中国模型周调用量升至2.27万亿Token,展现追赶态势。
2月9日至15日,中国模型以4.12万亿Token超越美国模型的2.94万亿Token,实现历史性突破。
2月16日当周,中国模型调用量达5.16万亿Token,三周增长127%,领先优势扩大。
这一增长源于中国AI厂商的集群式发展。
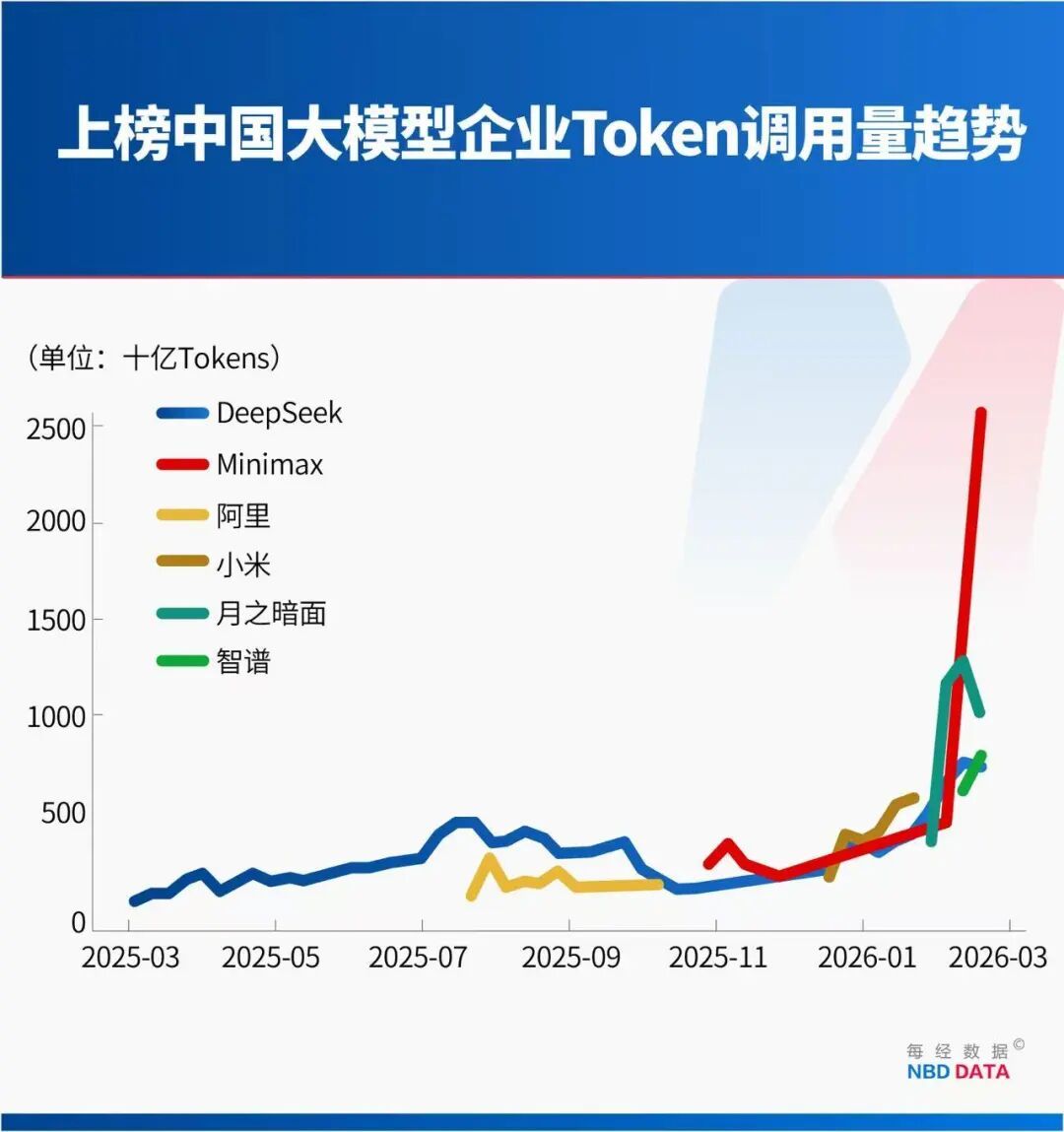
2026年2月16日至22日榜单显示,调用量前五的模型中,四款来自中国厂商,分别是MiniMax的M2.5、月之暗面的Kimi K2.5、智谱的GLM-5和DeepSeek的V3.2,合计贡献Top5总调用量的85.7%。
MiniMax于2月13日发布的M2.5模型,上线不足一周便登顶周调用量榜首。2月9日至15日,平台总调用量增加的3.21万亿Token中,M2.5贡献1.44万亿Token。
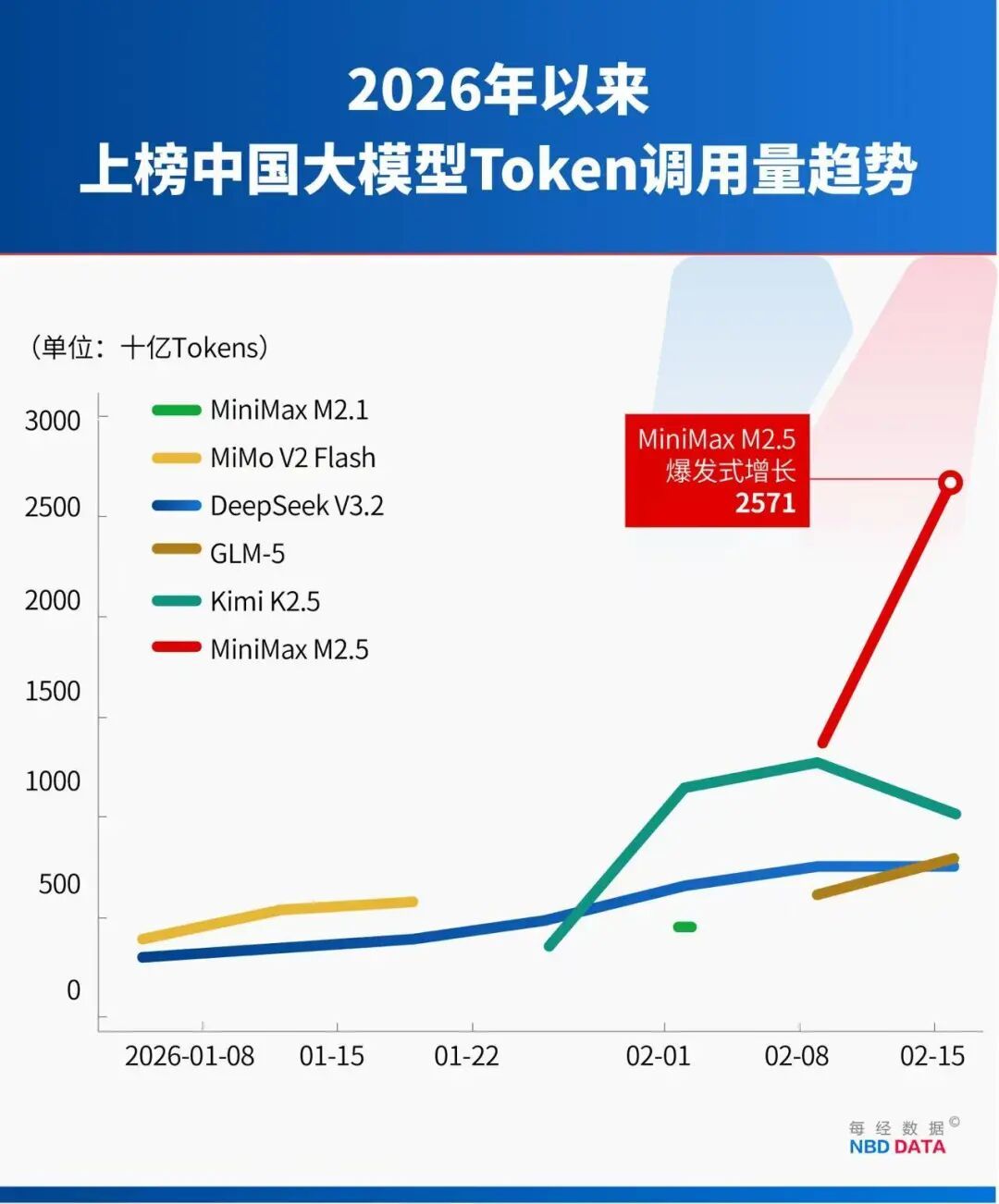
月之暗面1月27日发布的Kimi K2.5模型,凭借多模态架构和Agent并行处理能力,调用量持续增长。该模型可调度100个“Agent分身”并行工作,提升复杂任务处理效率3到10倍。发布后不到一个月的累计收入已超2025年全年,增长来自全球付费用户及API调用量提升。
智谱GLM-5模型2月12日发布后,凭借200K超长上下文窗口和长程Agent任务优化,用户规模快速增长,上线次周调用量达0.8万亿Token。
过去一年,阿里千问单个模型上榜频次不高,但a16z与OpenRouter联合报告显示,其全系列模型总Token调用量5.59万亿,全球排名第二,仅次于DeepSeek的14.37万亿。
弗若斯特沙利文报告显示,2025年下半年中国大模型B端市场中,千问系列模型日均Token调用量占比32.1%,位列第一,较上半年的17.7%翻倍,领先字节豆包(21.3%)和DeepSeek(18.4%)。
上海财经大学特聘教授胡延平提出“AI中国团”概念,认为多家头部企业形成技术产业群落,而非少数寡头,有利于竞争创新、人才生态建设及中美AI竞争中的集群优势。
风险投资机构Andreessen Horowitz合伙人Martin Casado发现,硅谷寻求融资的AI初创公司中,80%路演核心模型使用中国开源模型。
竞争力:成本不足美国AI的1/10 中国Token为何价格更低?
中国模型能快速吸引全球开发者,除性能比肩国际顶尖模型外,成本优势是核心因素。
OpenRouter平台价格显示,中国模型成本优势明显。输入环节,MiniMax M2.5与智谱GLM-5价格为0.3美元/百万Token,海外产品Claude Opus4.6为5美元/百万Token,是中国模型的约16.7倍。
输出环节,MiniMax M2.5为1.1美元/百万Token,智谱GLM-5为2.55美元/百万Token,Claude Opus4.6达25美元/百万Token,分别是前两者的约22.7倍和9.8倍。
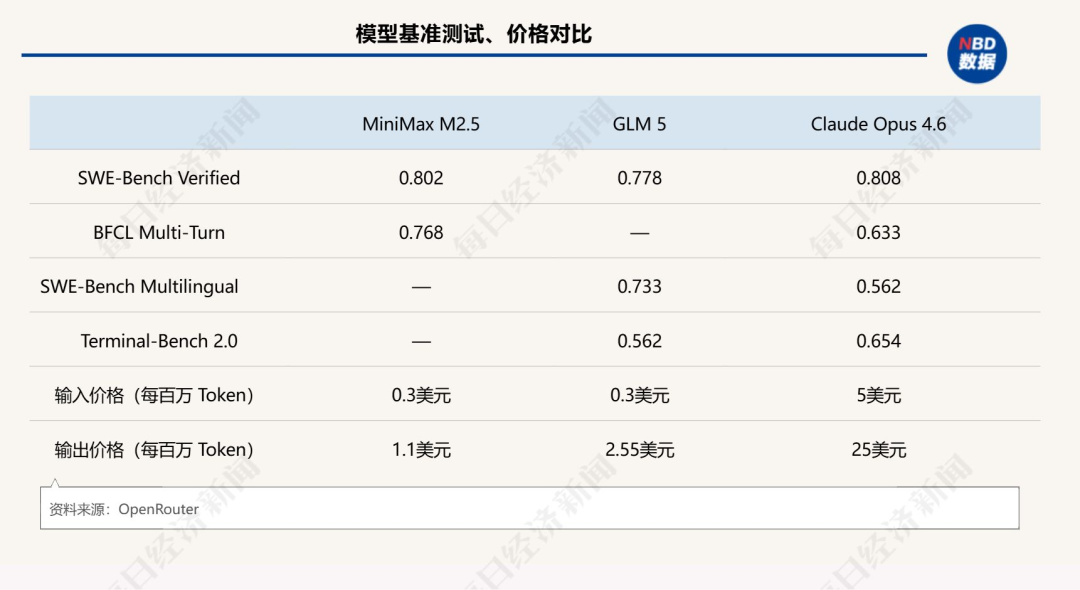
巨大成本差距影响开发者API选择。
成本差异源于算法架构创新。弗若斯特沙利文中国总监李庆分析,“混合专家(MoE)”架构是中国模型降低推理成本的核心原因,DeepSeek、阿里通义千问3.5-Plus等模型广泛采用该架构。
MoE架构将大模型拆分为多个“专家网络”和“门控网络”,总参数量大保证能力上限,实际任务中仅激活部分相关专家网络计算,减少计算量和硬件需求。数据显示,MoE架构可降低推理显存占用60%,提升推理吞吐量19倍,从技术源头实现降本增效。
中国AI厂商还通过“垂直整合”压缩成本,将模型算法、云计算基础设施和AI芯片深度协同优化,解决软硬件适配问题,提升算力利用效率。
李庆以阿里“通义-云-芯”体系为例,垂直整合模式通过算力调度算法高效利用硬件资源,降低AI服务基础设施成本,进一步降低Token生成成本。
摩根大通研报预测,2025至2030年中国Token消耗量年复合增长率达330%,5年间增长370倍。
价值转变:Token从互联网“流量”变为AI时代“燃料”
Token消耗量指数级增长,表面是用户规模和使用时长增加,深层原因是用户对AI使用模式的转变,AI从“问答工具”进化为“生产力工具”。
国联民生证券研报提出“Token通胀”概念,指单位时间、单位用户Token消耗结构性上升,归因于三大趋势:用户需求从“问答”转向“干活”,编程等场景消耗大量Token;AI Agent技术普及,多次调用模型累加Token消耗;推理强度上升,用户愿增加Token投入提升效率。
这意味着Token不是互联网时代边际成本为零的“流量”,而是生产任务的“燃料”。
英伟达CEO黄仁勋在业绩电话会上强调“计算即收入”“推理即收入”,指出算力决定Token生成,Token影响收入增长,推理性能决定客户收入能力,“性能/瓦特”是AI服务效率与收入能力的关键指标。
李庆表示,AI服务商业模式从“按量计费”向“燃料+成果”混合模式演进,Token单价随技术进步和规模效应下降,企业更愿为“成果”付费,催生订阅制模式。
李庆预测,未来AI服务定价将高度定制化,计算消耗、调用频次、任务复杂度等将影响定价,多维度动态定价体系将成主流。
记者|宋欣悦
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com