
全球首个全开源科学文献综述AI登Nature:引文准确率媲美人类专家








OpenScholar的引文准确率与人类专家不相上下,尽管仍需后续优化,但该工具有望助力科学家应对复杂且日益繁重的科学文献综述工作。

论文链接:https://www.nature.com/articles/s41586-025-10072-4
虽说大语言模型(LLM)在诸多领域表现亮眼,可在科研辅助任务中却面临严峻挑战:科学文献总量增长迅猛,模型难以跟进最新进展,还常出现严重的“幻觉”问题。实验数据表明,GPT-4o引用科学文献时,错误引用比例高达78%至90%。
OpenScholar整合了4500万篇开放获取论文与独特的自反馈机制,成功实现精准文献检索和准确引用生成,有效解决了现有模型在科学知识合成中的准确性与可信度难题。
首个全开源的科学文献综述AI系统
OpenScholar是专为科学研究任务设计的检索增强语言模型,能从4500万篇开放获取论文中识别相关段落,合成带引用支持的内容来解答科学查询。
OpenScholar的出色性能源于三大核心技术创新:
1.专属数据库(OSDS):OpenScholar拥有专属知识库OSDS,构建了完全开放且实时更新的语料库,涵盖4500万篇开放获取科学论文和2.36亿个段落嵌入向量。庞大的数据规模为训练和推理提供了可复现基础,保障了检索的全面性与时效性。
2.自适应检索:为在海量文献中精准定位信息,系统采用专门训练的检索器,超越简单关键词匹配,能依据查询语义深度,精准识别提取最相关文献段落,为后续生成提供高质量上下文。
3.自反馈机制:这是OpenScholar的关键技术创新。模型引入“自我反馈”推理循环,生成初步回答后,会检查自身产出的事实性、覆盖率和引用准确性,并据此迭代优化,大幅提升最终回答质量。
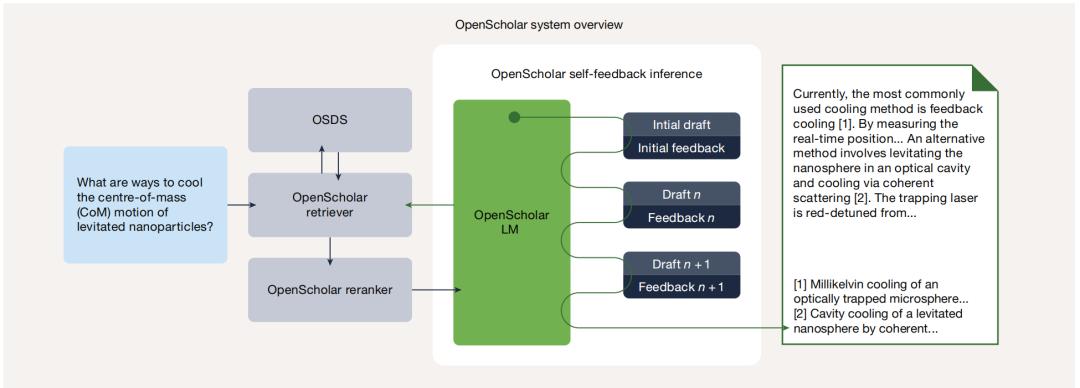
图 | OpenScholar整体架构。该系统包含专用数据存储、检索器和语言模型,通过检索过程中的自反馈推理迭代优化响应。
性能评估:全面超越现有系统
以往文献合成评估多聚焦短文本输出、多项选择或特定领域推理任务。为此,研究团队推出ScholarQABench——首个大规模、多领域开放式科学文献综合评测基准,真实模拟科研前沿挑战:含2967个专家撰写查询和208个长篇答案,覆盖计算机科学、物理学、神经科学和生物医学领域,要求基于大量论文最新文献生成长篇回答。
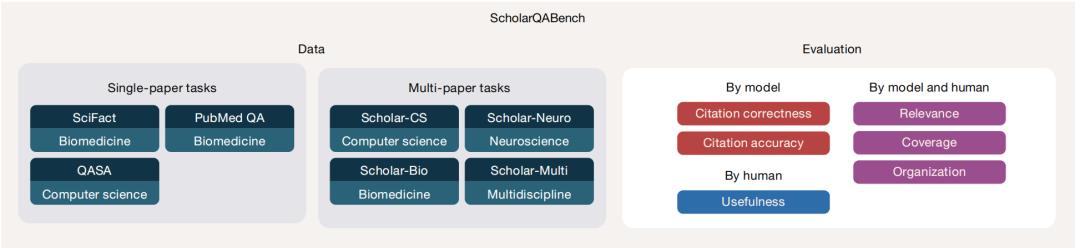
图 | ScholarQABench概览。该测试含2200道专家撰写的跨学科科学问题,研究团队开发了自动与人工评估方案。
在这一严谨新基准测试中,OpenScholar取得以下关键结果:
小规模轻量模型OpenScholar-8B,综合正确率超GPT-4o 6.1%,也超专用系统PaperQA2 5.5%,实现性能全面领先。
引用准确性方面,OpenScholar不仅达人类专家水平,还展现系统性优势。分析显示,人类撰写答案在评分标准评估中比无检索GPT-4o高9.6分,而OpenScholar-8B表现仅略低于人类专家2.9分。
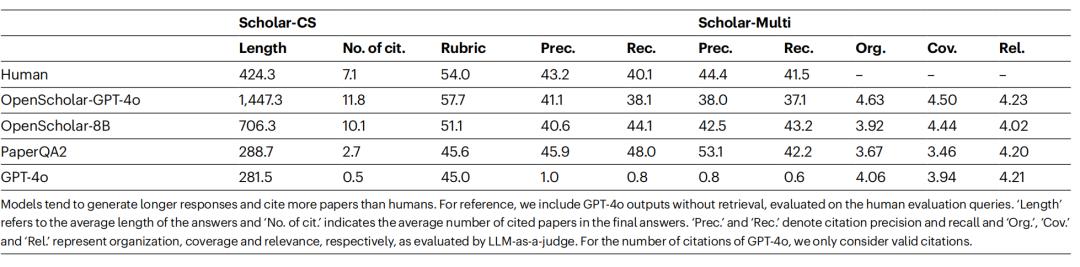
图 | 专家撰写回答统计。
人类专家评估中,专家明显更青睐OpenScholar生成的答案。具体而言,OpenScholar使用团队训练的80亿参数模型和GPT-4o时,分别以51%和70%胜率击败人工生成答案,而未经增强的原始GPT-4o胜率仅31%,低于人类专家基线。
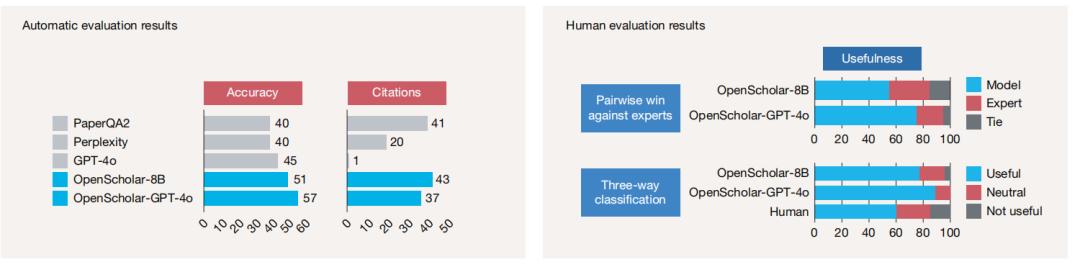
图 | 自动与人工评估结果:基于ScholarQABench计算机科学子集(Scholar-CS,100个问题)的实验数据显示,使用团队训练的8B模型或GPT-4o的OpenScholar系统表现显著优于其他系统,人工评估中超50%案例优于专家。本次人工评估由16位博士专家对Scholar-Multi的108个问题进行。
除性能卓越外,OpenScholar在设计上注重实用性。其轻量级专用检索器相比依赖庞大通用模型检索的方案,大幅降低系统运行与计算成本,让高质量、可信赖的文献综述辅助能更可持续、广泛地应用。
局限性与未来展望
尽管OpenScholar取得突破性进展,当前评测框架与系统仍存在局限性。
ScholarQABench主要关注计算机科学、生物医学和物理学,未涵盖社会科学、工程学等重要学科,研究发现可能无法完全推广到其他领域。因专家标注成本高、耗时长,人工标注评估集规模小,可能引入方差和注释者专业偏差。且ScholarQABench是静态公开基准,未来存在数据污染风险,增加训练或搜索中暴露的可能性。
某些复杂查询中,OpenScholar仍无法保证始终检索到最具代表性或最新的相关论文。80亿参数的OpenScholar-8B模型虽表现优异,但指令遵循和科学知识理解能力有限,可能导致输出存在事实性偏差。OpenScholar-GPT-4o版本依赖GPT-4o专有API,底层模型更新后实验结果可能难以完全复现,给研究可重复性带来挑战。此外,当前系统仅使用开放获取论文,如何合理合法整合大量受版权保护的学术文献,仍是亟待解决的问题。
目前,研究团队已开源OpenScholar的核心资源,包括代码、数据、模型检查点、数据存储和ScholarQABench,以支持和加速未来研究工作。
在此基础上,未来工作将整合平台用户反馈,持续优化检索质量、引用准确性及整体可用性。同时,团队计划进一步拓展应用边界,将支持范围延伸至更多科学领域及多语言场景,并积极寻求与学术出版机构合作,探索兼顾知识产权与开放获取的合规数据使用机制。
本文来自微信公众号“学术头条”(ID:SciTouTiao),作者:王跃然,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com