
5年上市6年盈利,沐曦能否讲透“国产英伟达”的故事?





出品 | 妙投APP
作者 | 董必政
编辑 | 关雪菁
头图 | 沐曦
资本市场正热捧GPU的国产故事。上一个机遇已错过,这一次绝不能再失之交臂。
此次,焦点集中在沐曦股份身上。
今日,沐曦股份登陆A股,首日高开568.83%,报700元,按开盘价计算,中一签可赚29.77万元。这一收益超过了摩尔线程的26.79万元,刷新了A股单签收益纪录。
截至12月17日中午收盘,沐曦市值达3299亿,摩尔线程为3330亿,寒武纪则是5391亿。
对比这三家被称为“国产英伟达”的企业市值,妙投分析认为,寒武纪总市值高于沐曦和摩尔线程,原因在于其营收规模最大且已实现盈利,而沐曦与摩尔线程尚未盈利,市值差距较小。
不过,沐曦首日上市无涨跌幅限制,其市值波动易受市场情绪影响。
此刻,我们需拨开情绪迷雾,思考沐曦能否像摩尔线程、寒武纪一样,支撑起即将到来的千亿市值?
从长远看,它必须找到突破英伟达壁垒的路径。
而当下,沐曦选择了一条更“顺势而为”的路线。
一、生态为王
无论是已上市的摩尔线程,还是刚上市的沐曦,翻开监管层的问询函,都会看到一个绕不开的问题:“如何实现与英伟达CUDA生态兼容?”
对行业而言,CUDA不仅是工具,更是事实上的行业标准。这正是英伟达长期垄断、毛利极高的根本原因。
因此,对国产芯片厂商来说,这不仅是技术问题,更是生存问题。沐曦、摩尔线程、寒武纪概莫能外。
妙投先解释为何CUDA难以绕开?
黄仁勋曾在GTC大会上表示:“GPU是我们的产品,CUDA才是我们的灵魂。”
现在要让程序在GPU而非CPU上运行,就需要CUDA这样的“翻译官”平台。
CUDA本质是将C++编写的应用程序“翻译”成GPU能理解的指令。妙投用建房子打比方:英伟达不仅提供了土地(GPU),还花十几年建立了庞大的“预制件库”(CUDA工具包),为开发者准备了各类建筑材料,包括底层数学库(如cuDNN),涵盖矩阵乘法、傅里叶变换、卷积算法等。
对开发者而言,直接调用英伟达的库就像搭乐高一样简单,性能还极高。
若使用其他品牌的GPU,开发者需从零开始编写矩阵乘法、调试算法。这不仅是“脏活累活”,更涉及高昂的时间成本。对AI赛道上争分夺秒的公司来说,成本过高,不如直接使用英伟达GPU。
这就是用户粘性。
更可怕的是惯性。
看看如今的AI领域:OpenAI的GPT、Meta的LLAMA,均基于CUDA平台开发。国内主流大模型基本是在开源模型基础上二次开发,在GPT2或LLAMA2上叠加知识库或二次训练。
这意味着,底层代码逻辑天生带有CUDA的基因。
若要将这些训练好的大模型迁移到国产GPU上,企业需经历痛苦的“模型迁移”,即重写代码、重新适配硬件、重新性能调优。这就像习惯开左舵车的人突然开操作逻辑相反的右舵车,还要参加F1比赛。
简言之,打不过,就得先想办法兼容。
这正是沐曦选择的路径。
二、对抗CUDA:造城还是修桥?
面对CUDA,国产厂商分化出不同的应对路线。
英伟达的CUDA是闭源的,类似当年的微软Windows或苹果IOS。为对抗垄断,移动端出现了开源的安卓,PC端有Linux。
历史总有相似之处,GPU计算平台领域必然会出现开源挑战者与CUDA分庭抗礼。
在此背景下,各厂商纷纷发力。
英伟达的直接对手AMD有ROCm,国内寒武纪推出NeuWare,摩尔线程打造MUSA平台。
大家思路直接:造一个自己的“CUDA”,让开发者把代码转过来,在自家平台运行,也就是迁移。
这种“自建生态”的打法本身没问题,但“各自为战”反而难以突破英伟达的壁垒。
试想,一个AI应用开发者为支持国产化,要面对寒武纪、摩尔线程、沐曦、壁仞、华为昇腾等五六个不同平台。每家都要改一套代码、维护一个版本。
工作量太大,迁移成本过高。
结果就是,开发者只会选1-2个国产GPU平台,分散到不同生态中,无法形成合力加速迭代,难以快速追赶英伟达。
要知道,AMD在2016年左右就推出ROCm平台对抗CUDA,但其GPU市占率仍远低于英伟达。
最优解是几大厂商共同制定标准,打造国产“Open CUDA”。
但没人想错过成为中国“英伟达”的机会。
在这种割据局面下,沐曦选择了更轻量化的路线——高度兼容CUDA+自研软件栈MXMACA构建生态。
如果短期内造不出第二个“安卓”,那就先做最好的“模拟器”,再发展自己的“安卓”。
根据沐曦招股说明书,在通用性方面,其MXMACA软件栈实现了对CUDA生态的高度兼容,核心在于极低的用户迁移成本:一个中等复杂度的CUDA应用仅需1人天即可完成迁移。
虽然这种打法长期仍依赖CUDA编程范式,但在国产替代紧迫的当下,高度兼容CUDA的落地速度快于迁移。
妙投认为,在没有公认的主流国产平台出现前,沐曦的“高度兼容打法”更容易吸引对迁移成本、落地速度敏感的开发者,利于快速商业化。
自2025年2月14日沐曦开源社区开放至2025年7月31日,公司MXMACA软件栈注册用户超15000人。
当然,沐曦这套打法的核心是先活下去,再做大生态,活得更好。
三、盈利是叙事的闭环
沐曦通过兼容CUDA找到了快速商业化的“闪电战”路径。
要知道,资本市场虽能容忍高科技企业前期烧钱,但最终仍会回归盈利能力。
面对上市对赌和回购压力,沐曦展现出爆发力。
通常,芯片行业有迭代周期,英伟达、AMD迭代一代产品也需约2年。
沐曦仅用3年就实现两款芯片一次流片并成功量产。核心产品曦云C500于2023年6月首批芯片回片,2024年2月正式量产;下一代基于国产供应链的曦云C600系列已于2025年7月回片。
这种快速商业化速度直接反映在财务报表上。
沐曦营收从2022年的43万元飙升至2025年前3季度的12.36亿元,复合年均增长率显著高于国内可比公司。
目前,沐曦尚未盈利,2025年1-9月归母净利润为-3.45亿元。对于盈利时间点,沐曦预计最快2026年实现,摩尔线程则预计最快2027年。
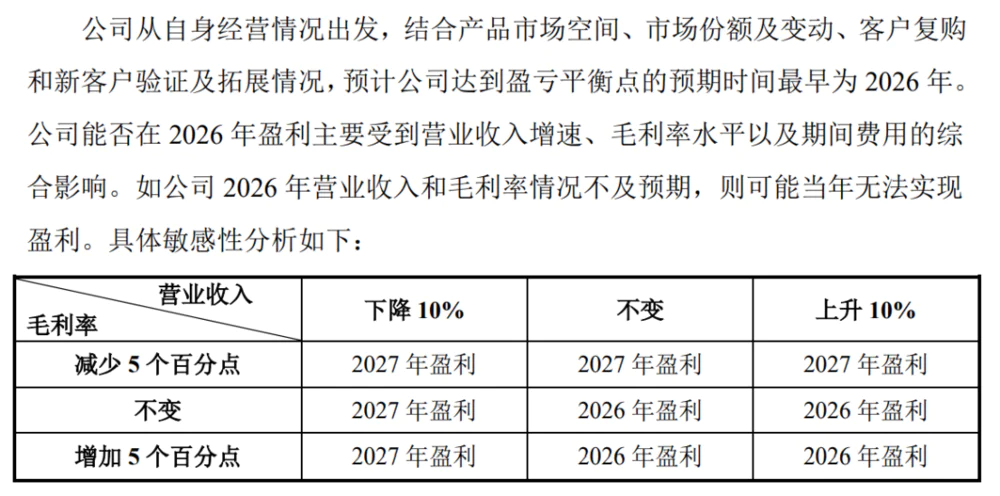
为何资本市场愿意相信这个时间表?
因为有寒武纪这个现成例子——2025年前3季度,寒武纪实现归母净利润16.05亿元。而就在一两年前,它还深陷巨额亏损泥潭,不过寒武纪用了近10年才实现盈利。
原因在于,美国对华高端GPU限制加码后,国内CSP(云服务提供商)被迫切换供应链。2025年10月,英伟达首席执行官黄仁勋公开表示,因出口限制,公司在中国市场份额从95%骤降至0%,并确认已完全退出中国市场。
这留下的巨大市场真空被国产厂商迅速填补。
在此逻辑下,沐曦扭亏为盈的关键不仅是国产替代的宏观红利,更在于新品曦云C600系列能否在2026年如期放量。
参考曦云C500从回片到量产的8个月周期,曦云C600已于2025年7月回片,有望在2026年年初正式量产。
根据招股说明书,曦云C600基于“国产供应链”,采用自研XCORE 1.5架构及指令集,配置HBM3e显存。这意味着供应链安全性和自主可控程度更高,更符合政府、央企、大型互联网公司的采购标准。
妙投认为,一旦曦云C600放量,沐曦营收将再上台阶,有望真正跨过盈亏平衡线,“国产英伟达”的叙事或将讲通。
那么,该如何给沐曦定价?
由于新品未量产,订单能见度有限,资本市场实则“摸着石头过河”。
当下,机构普遍采用PS(市销率)估值,但摩尔线程上市首日的疯狂表现让PS估值法似乎失效,其表现超出所有预期。
这再次证明:当前资本市场对国产GPU的定价,本质是对“稀缺性”和“国产替代空间”的定价,是对“中国英伟达”宏大叙事的溢价。
妙投认为,摩尔线程的估值锚是寒武纪;沐曦上市后的表现必然锚定摩尔线程。
从Pre-IPO轮估值看,当时沐曦估值210.71亿元,摩尔线程约300亿元,两者存在体量差距。
若简单按70%左右的比例换算,以摩尔线程当前3600亿市值为参照,沐曦市值有望达2500亿左右。
但需考虑一个关键变量——盈利预期。
资本市场最爱听的故事不仅是“有技术”,更是“能赚钱”。
若沐曦真能如预期在2026年率先盈利,“国产英伟达”的叙事将更具说服力。
此外,沐曦比摩尔线程早一年盈利,其成长性溢价和安全边际会更高。
一旦2026年沐曦证明曦云C600的量产变现能力,其市值空间有望进一步提升,甚至超过摩尔线程、寒武纪。
盘中,沐曦股份继续走强,大涨超700%,总市值近3350亿元,超过摩尔线程。
不过短期看,国产GPU厂商都有机会填补英伟达留下的空缺,分享增长红利;长期看,谁能做大“国产CUDA”生态,谁才能脱颖而出成为真正的中国英伟达,这场关于“灵魂”的战争才刚刚开始。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com