
无需逐字生成,蚂蚁赵俊博:扩散模型可直接修改Token,团队开源千亿级dLLM









当主流大语言模型仍依赖自回归架构时,蚂蚁集团资深技术专家赵俊博及其团队已将目光投向扩散架构。在量子位MEET2026智能未来大会上,赵俊博指出,扩散架构在推理时能直接修改和控制token,无需像自回归模型那样重新生成整段内容,理论上可实现更快生成速度与更低计算成本。基于此,团队聚焦扩散语言模型的Scaling Law探索,并近期发布开源了千亿体量的LLaDA 2.0。赵俊博坦言该领域训推仍处早期,但发展迅猛,谷歌、字节等巨头及初创公司已积极布局。
编者注:MEET2026大会结束后,赵俊博团队发布技术报告《LLaDA2.0: Scaling Up Diffusion Language Models to 100B》,报告链接(github):https://github.com/inclusionAI/LLaDA2.0/blob/main/tech_report.pdf

以下为赵俊博演讲核心内容整理:
核心观点梳理
- 生成模型本质是拟合数据分布,自回归模型将其拆解为单向条件概率,但这并非唯一路径。
- 开源模型LLaDA采用扩散架构,在不考虑MoE时,相同计算量和性能目标下,参数规模可比自回归模型更小。
- 扩散架构推理时可直接修改token,无需重新生成整段内容。
- 计算受限下,LLaDA的“完形填空”式预测更“data-hungry”,数据需求更大、吸收更快。
- LLaDA与自回归模型Scaling Law存在差异,已验证可扩展至千亿规模,但继续扩展面临新挑战。
押注扩散语言模型的Scaling Law
当前主流大语言模型多基于自回归架构,而团队开源的新模型架构完全不同。扩散机制在图像/视频模型中已广泛应用,如Midjourney、Sora等,核心是加噪再去噪。自回归模型是“做接龙”,给定前N个词预测第N+1个;扩散语言模型则是“做完形填空”,遮盖部分词后让模型恢复。
团队重点探索扩散语言模型的Scaling Law,原因在于:其一,计算受限下,扩散模型更“data-hungry”,能更快吸收数据;其二,相同dense结构下,扩散模型参数可更小;其三,扩散模型可一直训练,效果持续提升,而自回归模型训练到一定epoch后效果不再变动;其四,扩散模型支持可编辑可控生成,推理时能直接修改token,无需整段重来,解决了自回归模型推理侧token效率不高的问题。

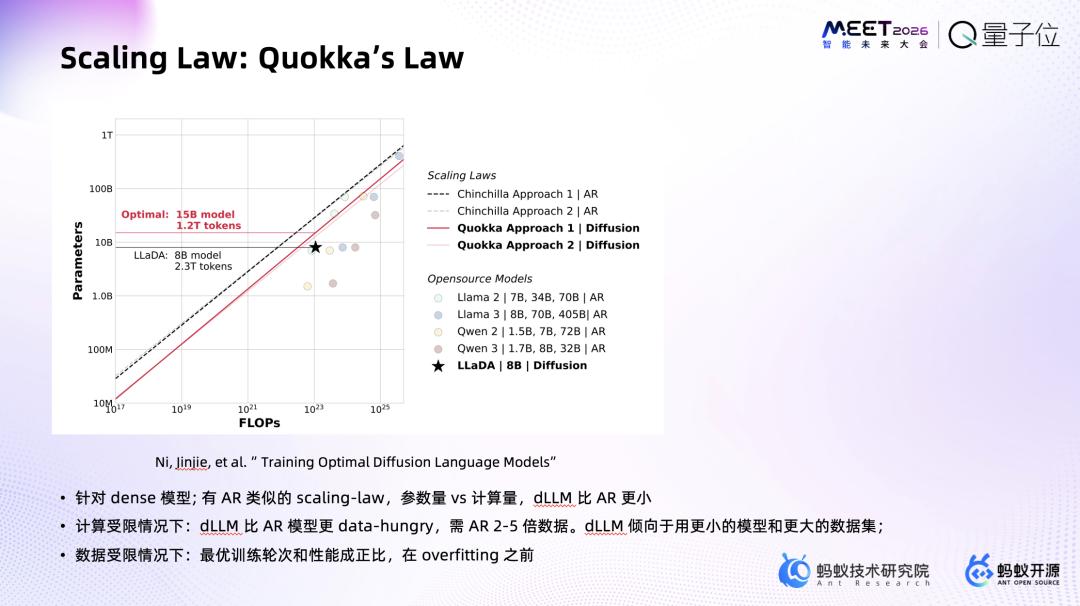
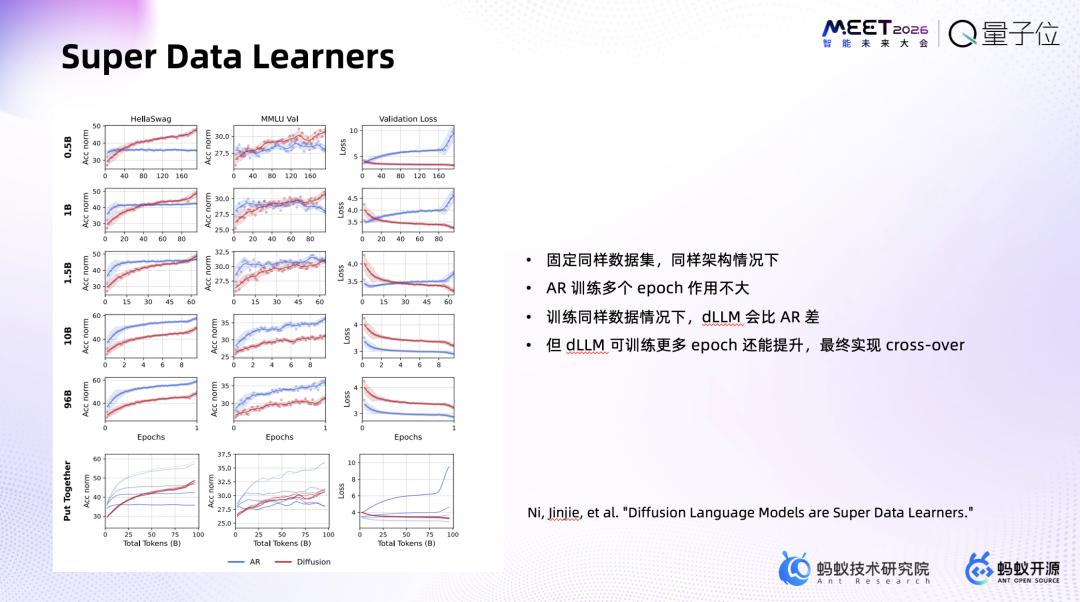
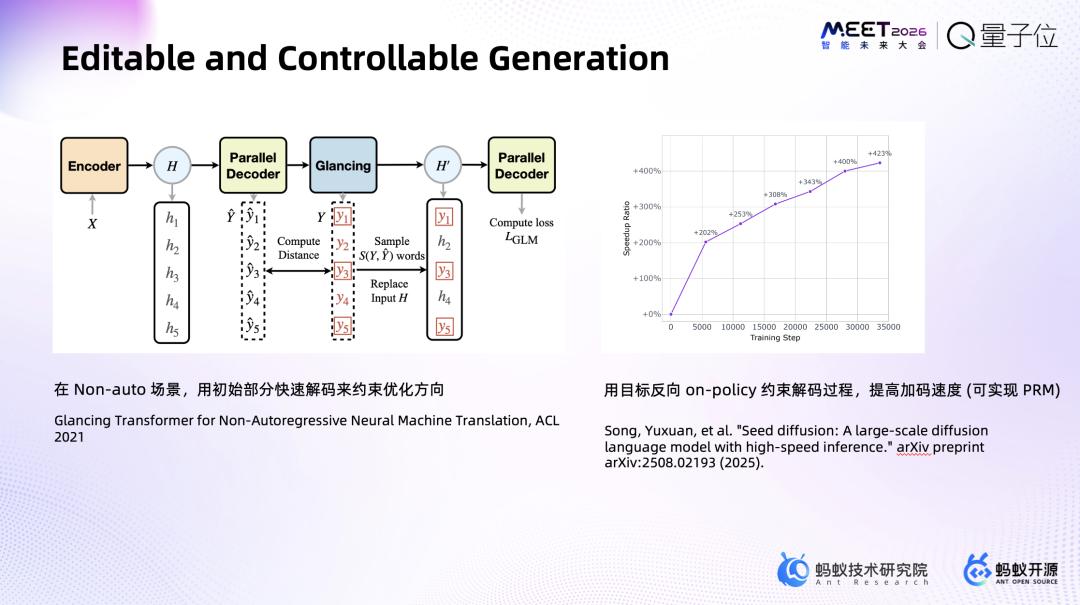
发布并开源千亿规模dLLM
团队在扩散语言模型研发中解决了注意力掩码适配问题,模型同时存在全局Attention(捕捉长程依赖)和Causal Attention(维持自回归约束)两种模式,还处理了随机长度序列、集成几何加权方法、实现长序列切分注意力等。开源了首个面向扩散语言模型的训练框架,支持SFT与DPO。
LLaDA发展脉络:人大团队开源LLaDA 1.0,8B版本对标LLaMA-3-8B;蚂蚁联合多校团队接过后,发布全球首个原生MoE架构扩散语言模型LLaDA-MoE(总参数7B,激活参数1B);近期发布LLaDA 2.0,率先将扩散语言模型做到千亿体量。该模型在调用、写代码任务上有明显优势,解码轨迹独特,接下来将联合ZenMux放出部分API。

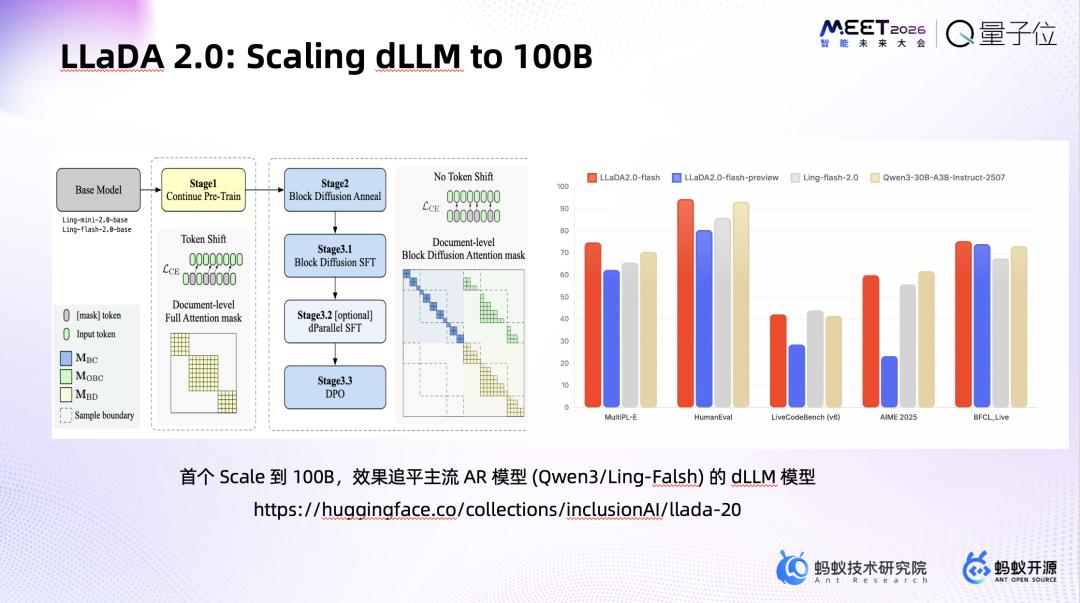
dLLM的训练推理仍处于早期发展阶段
团队10月发布试验性推理引擎dInfer,希望通过新架构与范式提升关键场景TPS。目前dLLM训推生态刚起步,与自回归模型Scaling Law有很大区别,继续扩展面临新挑战,但团队会持续探索,也希望社区共同共建。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com