
OpenAI推出超强编程模型:性能超越谷歌,助力编程新突破






IT之家11月20日消息,OpenAI于昨日(11月19日)发布博文,宣布推出GPT - 5.1 - Codex - Max智能体编程模型。该模型显著提升了长远推理能力、效率和实时交互能力,并且将取代GPT - 5.1 - Codex,成为Codex集成界面上的默认模型。
据IT之家援引博文介绍,此次发布紧跟谷歌Gemini 3 Pro之后。不过,在多个关键编程基准测试中,Codex - Max展现出更强的实力。例如,在衡量解决实际软件问题的SWE - Bench Verified测试中,Codex - Max以77.9%的准确率小幅领先于Gemini 3 Pro的76.2%。
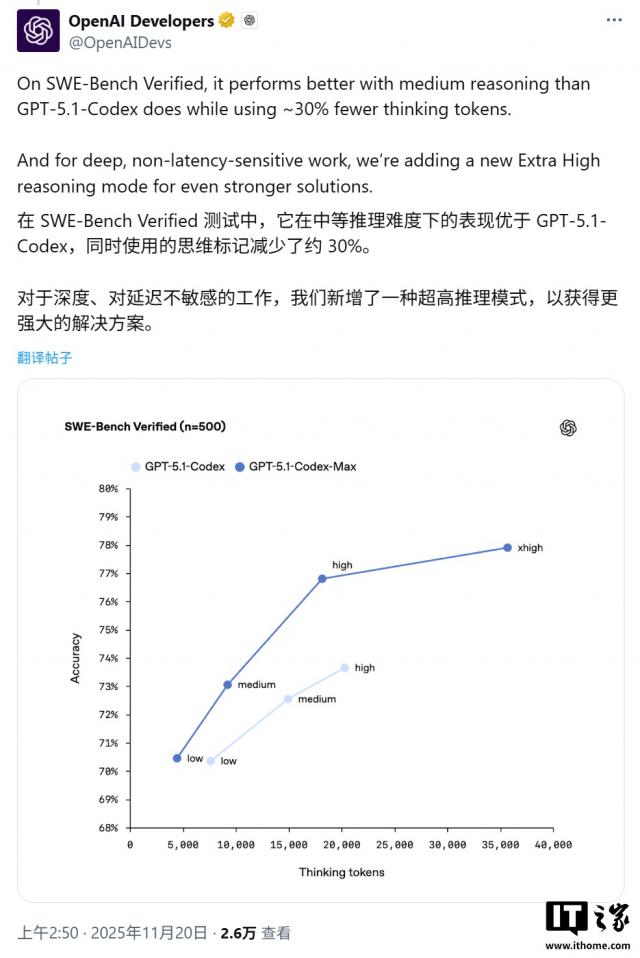
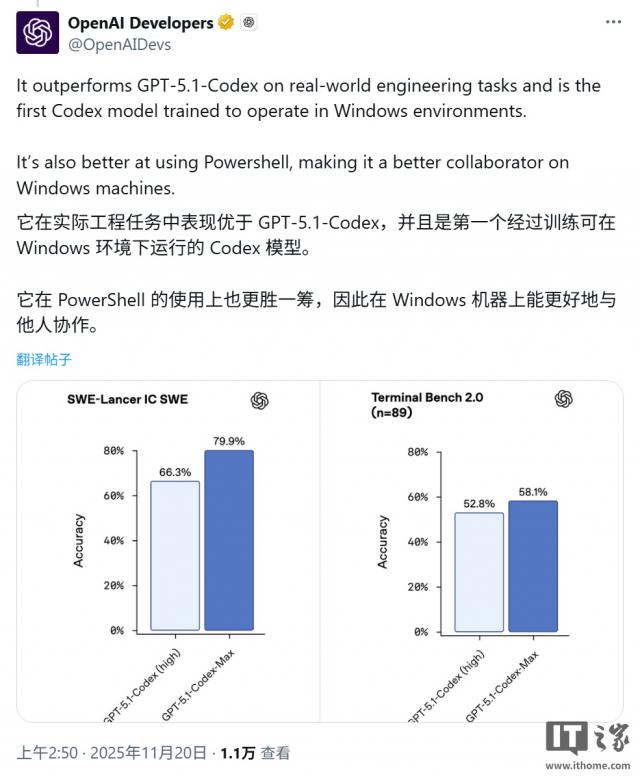
Codex - Max在Terminal - Bench 2.0测试中也处于领先地位,准确率达到58.1%,而Gemini的准确率为54.2%;在LiveCodeBench Pro(一项竞争激烈的编码Elo基准测试)测试中,它的得分与Gemini的2439分持平。

GPT - 5.1 - Codex - Max的一项重大架构升级是引入了名为“压缩”(Compaction)的机制。该机制能让模型在接近其上下文窗口限制时,智能地保留关键上下文信息并丢弃无关细节,从而实现跨越数百万token的连续工作,且不会出现性能下降。

得益于这一机制,该模型在内部测试中已成功完成持续超过24小时的复杂任务,如多步骤代码重构和自主调试。同时,这项技术还提升了约30%的token效率,有效降低了成本与延迟。
新模型目前已集成到OpenAI自家的多个Codex开发环境中,包括其官方命令行工具(Codex CLI)、内部代码审查工具以及各类交互式编程环境。
开发者可以通过这些工具体验到模型强大的实时交互能力,例如在可视化界面中进行强化学习训练或模拟光学定律。不过,GPT - 5.1 - Codex - Max尚未通过公共API提供,但官方表示即将开放。普通用户则需要订阅ChatGPT Plus、Pro或企业版等付费计划才能使用。
OpenAI透露,其内部95%的工程师每周都会使用Codex。自采用以来,这些工程师平均多提交了约70%的拉取请求(Pull Requests),显著提升了内部开发速度。
尽管Codex - Max具备高度的自主性,OpenAI仍强调它应作为编码“助手”而非人类的替代品。为保证透明度,模型会生成详细的终端日志和测试引用,以便开发者审查和验证其生成的所有代码。此外,模型在默认情况下运行于严格的沙盒环境中,并禁用了网络访问,以确保安全性。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com