
最强VLA模型π*0.6登场,机器人办公室开咖啡厅






用VLA自身行为进行训练的新方法,大幅提升了具身智能的成功率和处理效率。
新方法大幅提升了具身智能的成功率、处理效率。
完全基于真实世界数据训练的具身智能,具备何种能力呢?
本周,美国具身智能创业公司Physical Intelligence(简称PI或π)推出了旗下最新的机器人基础模型π*0.6。
PI是一家总部位于旧金山的机器人与AI创业公司,其目标是将通用人工智能从数字世界引入物理世界。他们的首个机器人通用基础模型π₀,能让同一套软件控制多种物理平台执行各类任务。
2024年,PI获得超4亿美元融资,估值突破20亿美元,成为具身智能赛道备受关注的企业之一。
PI的技术路线聚焦“视觉 - 语言 - 动作”(VLA)模型,通过大规模机器人感知与动作数据训练出具有泛化能力的策略,使机器人能在未知环境中灵活执行任务,而非局限于预设动作。
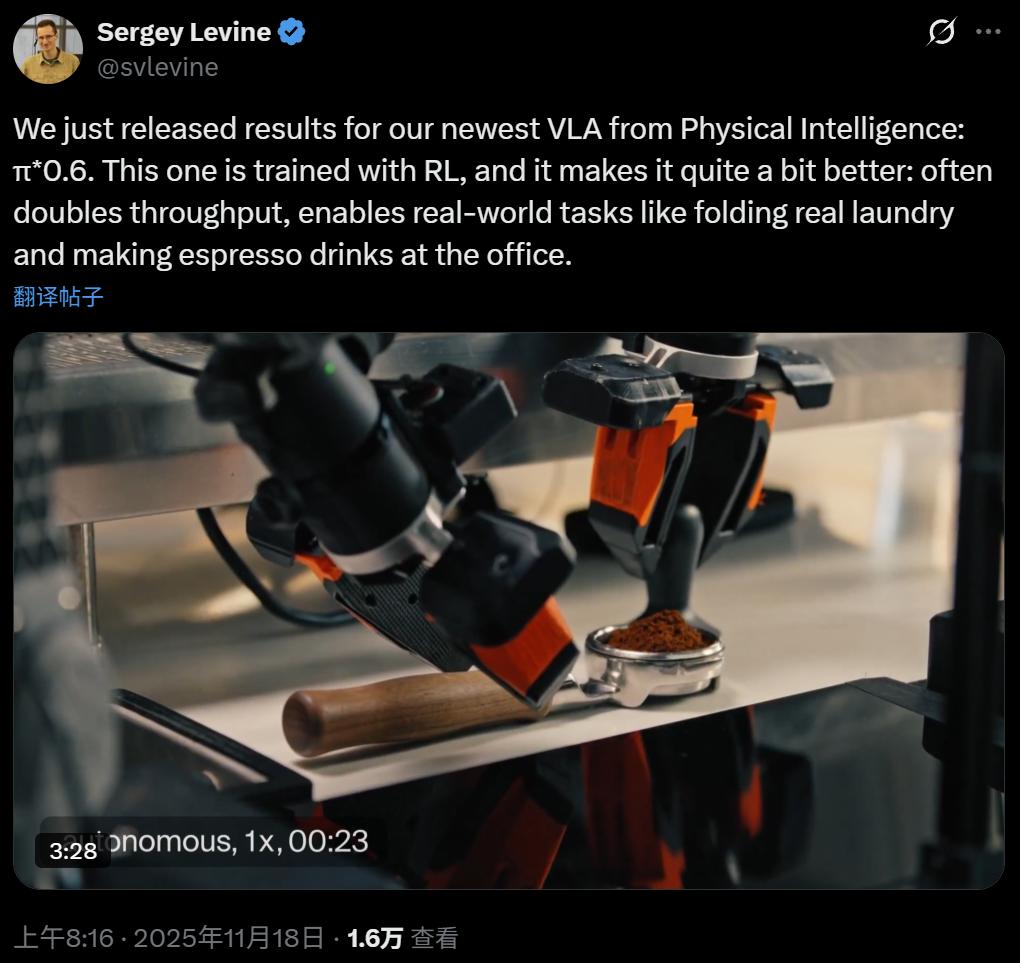
机器学习与决策控制领域的知名专家、UC Berkeley副教授、Physical Intelligence联合创始人Sergey Levine表示,搭载该模型的机器人已能在公司办公室为人们制作拿铁、美式和意式咖啡。
Sergey Levine称,对π*0.6模型进行微调后,除处理衣物外的任务成功率可达90%,且任务处理效率大幅提升。
在Physical Intelligence的一篇博客中,工程师详细介绍了π*0.6的机制与性能。
以组装纸箱为例,人类完成此任务,首先会向他人学习基础知识,了解有效方法、常见错误和正确技巧;其次,优秀的老师会演示操作并纠正错误;最后,通过反复练习达到熟练掌握。
过去一年,机器人学习领域很多成果仅采用第一步,即通过人类演示训练机器人。虽能让机器人完成一半任务,但难以保证每次成功,更难在复杂实际任务中达到人类水平的效率。而实际机器人任务需要可靠且快速运行的系统。
基于此,Physical Intelligence开发了名为Recap(基于优势条件策略的经验与纠错强化学习)的方法,实现了上述三个步骤:通过演示训练、纠错指导,并让机器人从自主经验中改进。利用Recap改进的视觉 - 语言 - 动作 (VLA) 模型π(0.6),能稳健高效地执行复杂任务,如制作意式浓缩咖啡、组装纸箱和折叠衣物。
经强化学习训练后的模型π*(0.6),利用Recap在自主经验上训练,可使一些困难任务的吞吐量提高一倍以上,失败率降低2倍或更多,达到实际应用所需的鲁棒性,能连续制作意式咖啡、折叠衣物和组装纸箱。
模仿是远远不够的
我们会疑惑,为何VLA仅依靠监督学习(模仿)难以持续成功,而监督学习在LLMs等系统中效果良好。原因已被认知,但此前缺乏实用解决方案。
模仿训练的VLA控制机器人时会犯小错误,如夹爪位置错误、抓取失败或撞倒物体。在真实物理环境中,这些错误会产生与训练数据不同的情境,错误会累积,导致更大错误和任务失败。
对于产生静态输出的AI系统(如LLMs),这不是大问题;但对于持续与外部环境互动的机器人控制策略,这是严重问题。即让VLA偶尔完成任务较易,但保证可靠稳定成功很难。
使用VLA自身行为的额外数据,让其在真实世界纠正错误,可解决累积错误问题。但这类经验缺乏真实标签,若让模型复制之前行为,会继续犯错,关键是从糟糕经验数据中提取良好训练信号。
纠正式指导与强化学习
Recap能从“质量较差”的经验数据中获取良好训练信号,途径有两种:
纠正式指导(coaching with corrections):专家展示机器人修复错误或做得更好的方法;
强化学习(reinforcement learning):机器人根据任务最终结果判断行为好坏,迭代学习强化好行为、避免坏行为。
纠正式指导需专家远程操作人员提供纠正信号,展示如何从机器人实际错误中恢复,即运行当前最强策略,出错时手动远程接管控制。此干预可作为监督信号,解决错误累积问题。
但仅依靠纠正式指导有限,其质量取决于人类判断和纠正能力。要获得最佳性能,机器人必须自主学习。
强化学习的核心挑战是“信用分配”,即判断机器人哪些动作导致好结果,哪些导致坏结果。如机器人抓取意式咖啡机手柄方式错误,插入时会遇困难,正确的信用分配应将失败归因于抓取动作。

仅通过模仿学习训练的基础模型插入手柄时会遇困难,失败原因可能在更早阶段。
Recap通过训练“价值函数”解决信用分配问题。如象棋游戏中,价值函数根据棋局预测智能体获胜概率,使价值函数上升的动作应被鼓励,下降的动作应被抑制。

在一个回合中不同时间点的值函数预测,完成任务的(负)步数会随机器人进展而变化。
训练好价值函数后,需用其得到更好的策略。Recap中,Physical Intelligence让VLA根据价值变化调整,使用所有训练数据,标注动作好坏。在强化学习中,“价值变化”即优势,执行时让VLA选择高优势动作,得到更优策略。
面向真实世界任务
Physical Intelligence用Recap训练π*(0.6)模型,使其能执行多项真实世界任务。π*(0.6)基于π(0.6)训练,π(0.6)是π(0.5)的改进版,采用稍大骨干网络,能处理更异质化的提示与条件信息。
https://website.pi-asset.com/pi06star/PI06_model_card.pdf
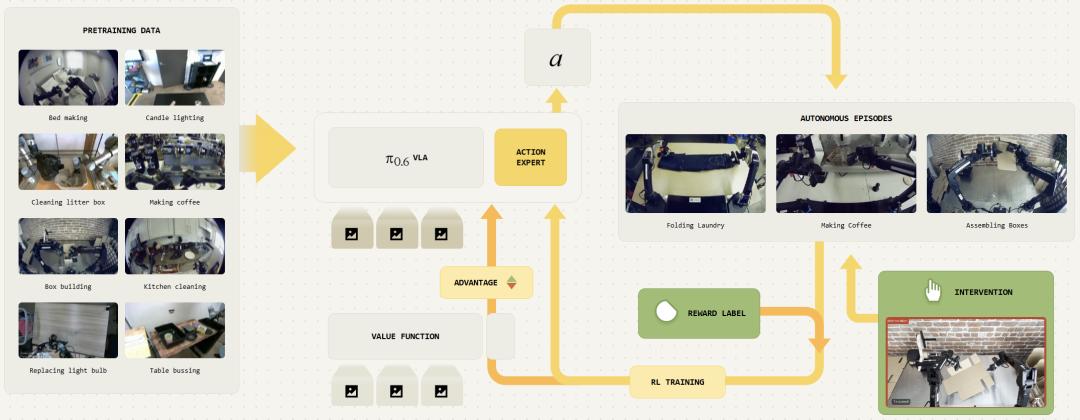
研究了制作意式咖啡饮品、折叠衣物和组装纸盒三个应用场景。Recap第一阶段用离线强化学习预训练π*(0.6),与基础模型的监督学习方法不同。在此基础上,通过示范数据微调,再利用机器人真实环境数据强化学习,包括专家纠正和奖励反馈。
对比不同阶段模型性能,对每个任务测量吞吐量和成功率。对于困难任务,加入机器人真实执行经验后,吞吐量和成功率提升超两倍。
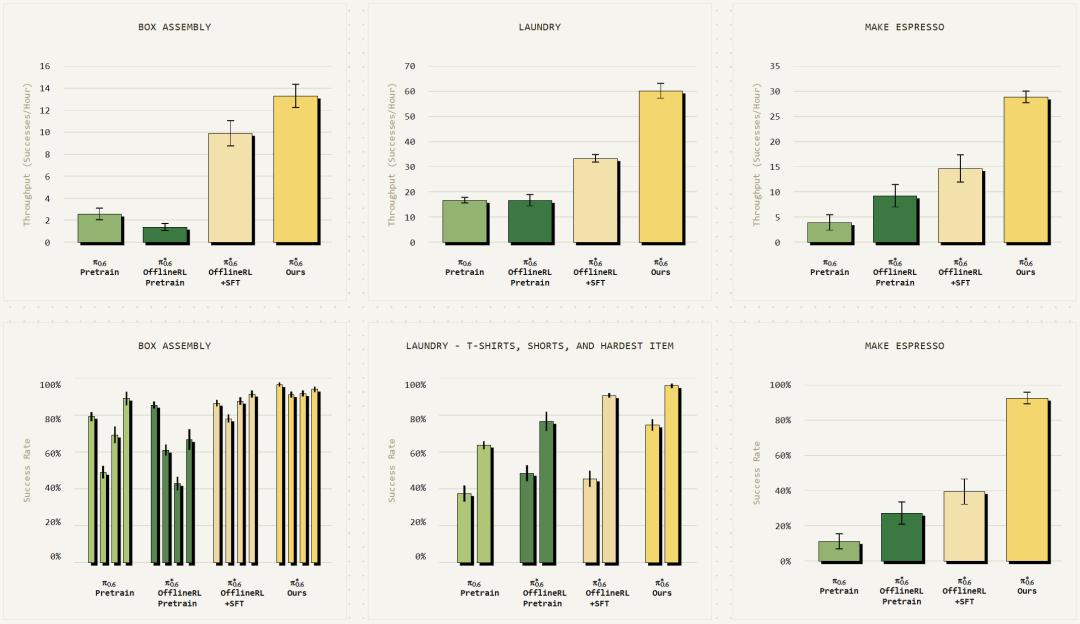
Recap显著提升所有任务的吞吐量,通常也大幅提高成功率。
最终的π*(0.6)模型结合示范数据和自身经验,能熟练完成各应用任务。

π*(0.6)能应对多种条件,从错误中恢复。
各任务都有挑战,如组装纸箱需复杂物理操作,处理边缘情况;折叠衣物要处理多样性和不同布料特性;制作意式咖啡需长操作序列,处理液体、判断机器状态和清洁机器。而π*(0.6)能以超90%的成功率完成这些任务。
下一步?
目前机器人基础模型依赖人为收集的示范数据,虽训练简单,但需大量人工投入,模型受人类操作水平限制,无法通过经验提升。Recap能解决这些限制,可直接从机器人自身经验中学习。
随着机器人在真实世界广泛部署,从经验中学习将成为重要数据来源和高性能模型的关键。
如同人类通过“指导 — 辅导 — 练习”成长,机器人也将从多种数据来源学习,专家示范定义新行为,纠正式指导改进策略,自主经验打磨行为,有望超越人类表现。
参考链接:
https://www.pi.website/blog/pistar06#where-are-we-headed
本文来自微信公众号“机器之心”,编辑:泽南、冷猫,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com