
北京人形机器人创新中心开源强大具身智能模型 Pelican - VL 1.0





IT 之家 11 月 14 日消息,北京人形机器人创新中心昨晚宣布将具身智能 VLM 模型 —— Pelican - VL 1.0 全面开源。
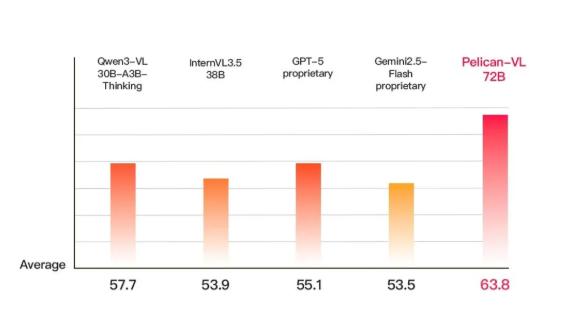
据官方介绍,该模型有 7B、72B 两种参数规模,是目前“最大规模的开源具身多模态大模型”,也是全球性能最强的具身智能 VLM 模型。测试显示,其性能比 GPT - 5 同类模型高 15.79%,相较于 Google gemini 系列模型提升 19.25%,还超越了通义千问、书生万象等国内模型,成为当下最强的开源具身多模态大模型。
该团队提出了全新的 DPPO(刻意训练)训练范式,这是全球首创的具身多模态大模型后训练自进化算法框架。借助 DPPO,Pelican - VL 达成“性能最强”目标仅用了 200K 数据量,只是其他大模型的 1/10 甚至 1/50,堪称开源 VLM 的性价比之王。
Pelican - VL 1.0 的开源,能显著增强具身智能在商业服务、工业泛工业、高危特种作业、家庭服务等多种真实场景中,通过视觉 - 语言感知辅助多步任务规划的能力。VLM 是实现机器人全自主的核心,Pelican 的开源将推动我国具身智能全自主发展。
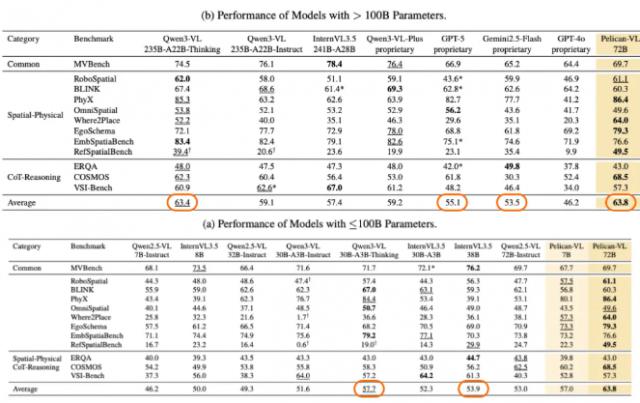
此次开源的 Pelican - VL 1.0 核心优势在于深度整合海量数据与自适应学习机制。它在由 1000 + A800 GPU 组成的集群上训练,单次检查点训练耗费超 50,000 A800 GPU - 小时;团队从原始数据中提炼出包含数亿 token 的高质量元数据作为训练基础。凭借这些优势,Pelican - VL 1.0 在基线基础上性能提升 20.3%,平均比 Qwen3 - VL 系列、InternVL3.5 系列等同级别开源模型高 10.6%。
得益于“刻意练习”DPPO(Deliberate Practice Policy Optimization)训练范式,Pelican - VL 如同刻苦学习的学生,每次训练循环都遵循“看视频 — 自主练习 — 发现错误 — 纠正提升”的流程。DPPO 模仿人类元认知学习方式,通过强化学习(RL)探索弱点、生成失败样本,再进行有针对性的监督微调(SFT),让模型不断自我纠错和迭代进步。
就像学生总结错题经验,Pelican - VL 能在训练中找出“薄弱知识点”并弥补,持续提升视觉 - 语言和具身任务能力。通过这种机制,Pelican - VL 能更精准理解图像内容、语言指令和物理常识,最终在决策和操作执行环节,实现具身智能在空间 - 时间推理和动作规划方面的重大突破。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com