
苹果新推视频识别模型FastVLM:赋予AI视觉能力







AI产品经理迎来新利器,苹果近期更新了一款名为FastVLM的开源模型。该模型规模为7B,显存占用不到10多个GB,它是在阿里Qwen2 - 7B的基础上进行了更深度的训练。
FastVLM最大的突破在于能够识别视频流,从算法层面来看,论文显示其识别准确度达到了最高水平。

其生成原理是将视频拆分成一阵一阵的图像进行处理,提取每一帧图像的特征并汇总。到第五步时,将特征汇总,然后通过文本向量数据库进行结果匹配。
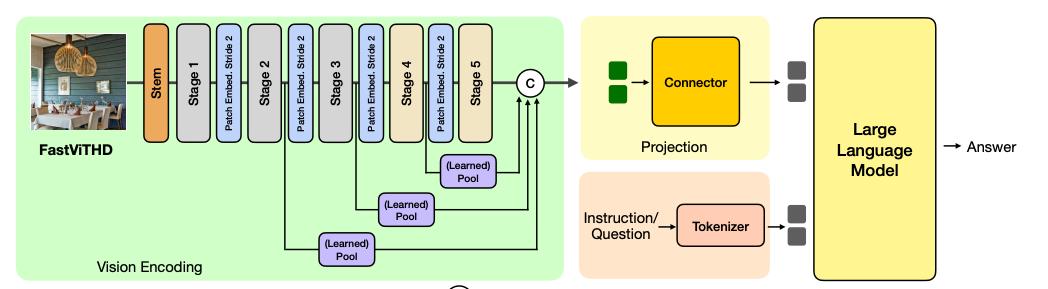
FastVLM不仅可以在原生手机客户端运行,还支持web浏览器。它能够精准识别现实物理世界中的物品、字体,甚至理解内容含义,方便开发者快速调用。
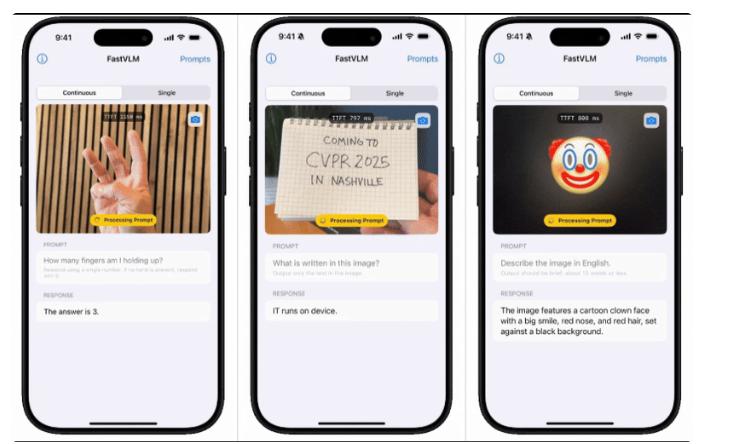
与其他AI产品相比,这个视觉生成模型提供了视觉一体化方案。由于延迟更低,它能极大地拓展应用场景,用户无需长时间等待,也不需要大量算力。
该模型参数仅7B,有用户测试发现,在16GB的M2设备上就可以完成测试。
AI模型的端到端离线,是用户的刚需
和其他模型不同,这个7B的FastVLM模型支持离线使用,保障了数据隐私和安全。它还支持高分辨率图像理解,能处理图像与文本之间的关系,以及前面提到的视频理解。
该模型非常适合应用在MR与AR眼镜上,借助其视觉能力,在眼镜上使用FastVLM可拓展到RAG,从而支持更多场景,如疾病诊断、生活打扫等,甚至可应用于机器人视觉。
本质上,模型需要向量数据库,将视频转为文本后与RAG搭配,能开拓更多应用场景。
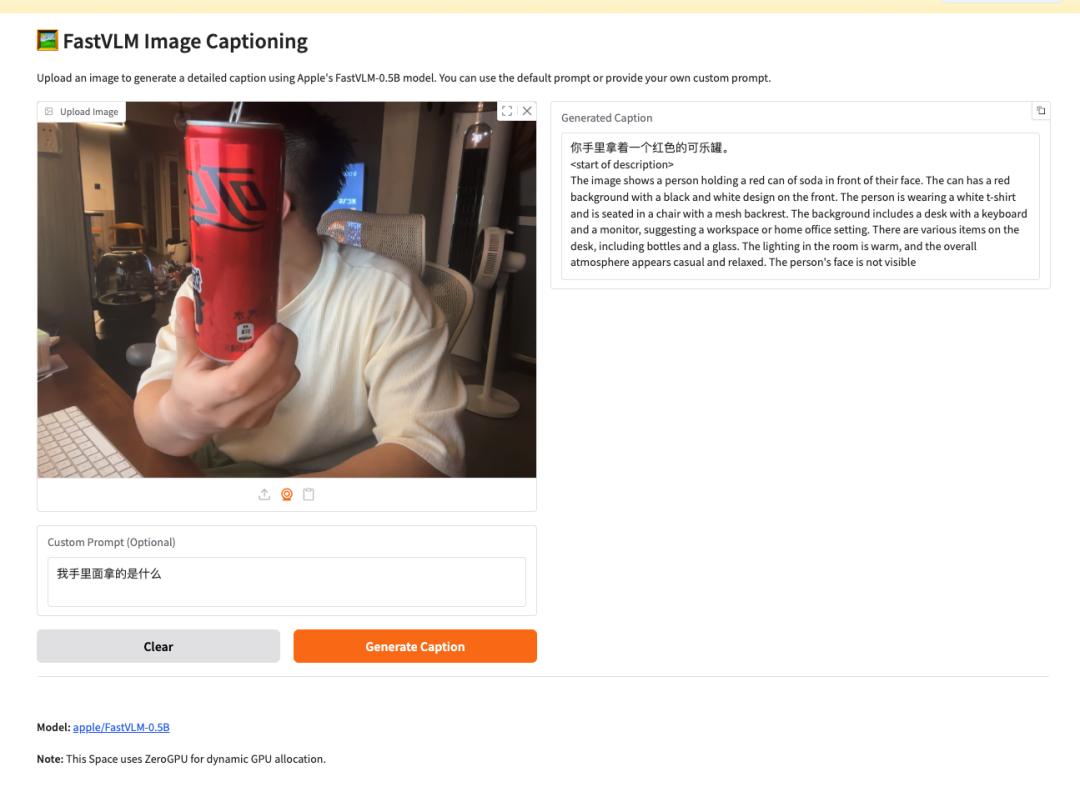
目前,FastVLM的生成速度极快,能在几秒内生成2小时视频的字幕。例如,进行视频生成测试时,即使瓶子不完整,也能准确识别出手中拿着的是可乐。
当AI模型可以在手机、平板电脑等设备上运行时,更多用户将能够使用,而不再受限于GPU算力。从长远来看,每个人都将使用AI,对算力的要求会逐步降低,使AI达到人类可用的智力水平,更多的算力则用于解决普通人很少涉及的场景和问题。
因此,建议AI产品经理收藏这个模型,并基于此优化自己的产品设计。
今天的分享就到这里。
本文来自微信公众号“Kevin改变世界的点滴”(ID:Kevingbsjddd),作者:Kevin那些事儿,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com