
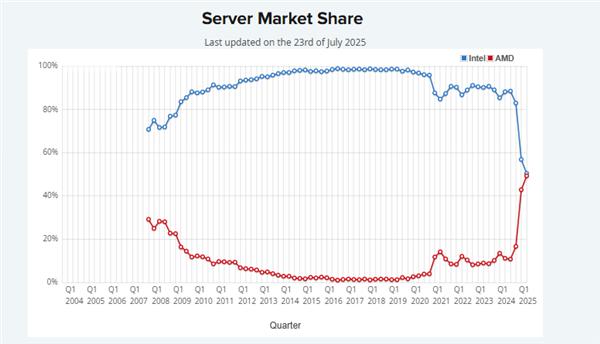
历史性突破!AMD服务器CPU市占率首达50%








电子发烧友网报道(文 / 黄晶晶)近日,市场研究机构PassMark对服务器CPU市场占有率的调查数据显示,截至2025年一季度,AMD在服务器CPU市场的市占率首次达到50%,与竞争对手英特尔持平。据AMD数据,自EPYC CPU推出后,其在服务器领域的市场份额从2018年的2%提升到2024年上半年的34%。此后,双方竞争将更加激烈。
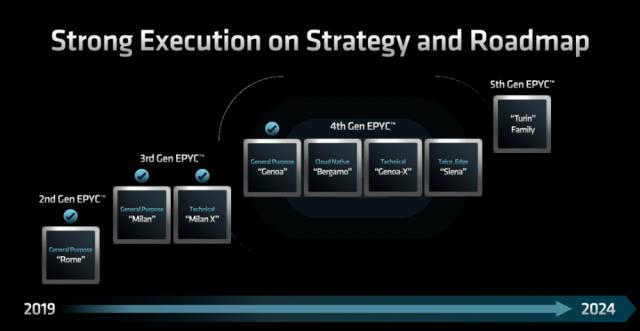
回顾AMD EPYC各代处理器的发展,它们都致力于为客户提供高性能、低能耗的CPU。2017年,AMD推出基于Zen架构的EPYC霄龙服务器处理器Naples,打破了英特尔在服务器市场的优势,开启高性能计算领域的竞争。2019年,基于Zen 2架构的第二代霄龙Rome问世,首次将7nm先进制程引入数据中心。2021年,AMD发布采用Zen 3架构的第三代EPYC霄龙服务器处理器Milan。后续还有第四代产品Genoa、Bergamo等,去年推出的第5代EPYC CPU Turin将核心数提升至192核。
AMD抓住AI时代数据中心对高性能CPU适配GPU以及承担AI推理任务等需求,凭借核心密度、能效、性价比等优势迅速崛起。
CPU适配助GPU发挥潜力
GPU加速器是现代AI的主力,在训练大型复杂模型和支持高效大规模实时推理方面表现出色。它能利用并行处理能力加速大、中型模型训练,为大规模实时推理提供速度和可扩展性。但要充分发挥GPU潜力,搭配合适的CPU可显著提高AI效率。
这样的CPU需具备高频率,能快速处理大量数据准备和后处理任务;大容量高速缓存,便于快速访问海量数据集;高内存带宽和高性能I/O,支持CPU与GPU快速交换数据;高能效核心,节约功耗供GPU使用,降低整体能耗;兼容GPU和软件生态系统,实现性能优化和流畅运行。
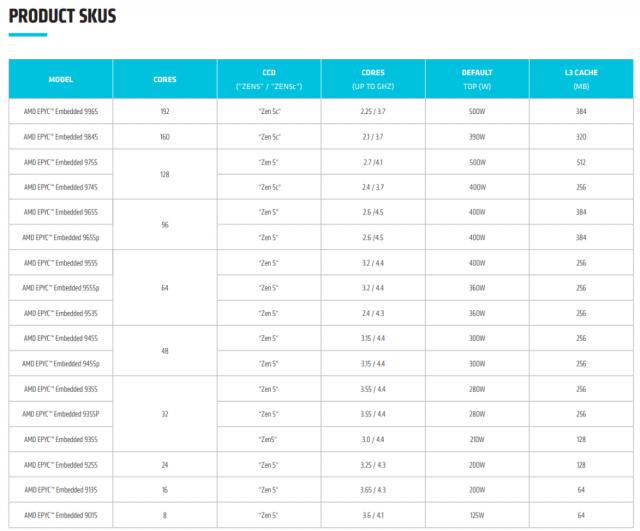
AMD EPYC(霄龙)9005系列处理器专为加速数据中心、云计算和AI工作负载设计,能帮助企业提升计算性能。该处理器基于Zen5/Zen5c架构,采用台积电4nm/3nm工艺制造,IPC提升17%,最高规格为192核/384线程,运行频率最高达5GHz。全新“Zen 5c”核心架构提供更高吞吐量和能源效率,与竞品相比,插槽吞吐量预计提升1.3倍,每瓦效能预计提高1.3倍。每个插槽DDR5存储器容量高达6TB,扩展了I/O连接性,通过CXL2.0支持160条PCIeGen5通道,还支持更多安全功能。
据介绍,使用AMD EPYC(霄龙)9005处理器,在机架数量减少86%的情况下,仍能实现与原有硬件相当的整数性能,大幅减少物理占用空间、功耗和软件许可证数量,为运行新的或扩展的AI工作负载腾出空间。
基于AMD EPYC(霄龙)9005 CPU的纯CPU型服务器能高效处理大量AI工作负载,如参数在130亿及以下的语言模型、图像和欺诈分析或推荐系统。与上一代产品相比,运行两个第五代AMD EPYC(霄龙)9965 CPU的服务器推理吞吐量可提升2倍。
作为CPU AI平台,基于AMD EPYC(霄龙)处理器的服务器可高效运行推理工作负载,满足不同模型和应用场景需求。AMD EPYC(霄龙)CPU灵活性出色,能满足从实时推理到批量推理或离线推理等需求。
以FP32精度运行常用的梯度提升模型XGBoost(Higgs数据集)时,基于192核AMD EPYC(霄龙)9965处理器的双路服务器推理吞吐量(平均每小时运行次数)是原有解决方案的3倍多。
AMD EPYC(霄龙)9005系列部分型号经专门优化,在搭载GPU的系统中作主机CPU时,可提高特定AI工作负载性能,提升每台GPU服务器的投资回报率。例如,运行Llama3.1 - 70B时,相同情况下使用高频AMD EPYC(霄龙)9575F处理器且搭载8个GPU的服务器系统性能可提升20%。
五大CPU推理负载
AI推理是将训练好的AI模型应用于新数据并做出预测。AMD有一系列专为AI推理打造的解决方案,能适应不同模型大小和应用需求。对于中小型AI模型和工作负载,AMD EPYC(霄龙)处理器是合适选择;对于批处理或离线处理应用,它是满足推理需求的高性价比方案。
现代数据中心需支持多种AI工作负载,通过合理配置,可在成本较低的CPU上支持许多AI服务,将GPU用于更繁重的工作负载。
传统机器学习算法无法从并行计算GPU中受益,使用决策树、随机森林和线性统计模型的机器学习任务能从多核心CPU中受益,而通常不充分利用GPU优势。如果情感分析、文本和图像分类、欺诈检测或时间序列预测等工作负载占比较大,配置高核心数CPU是明智之选。
模式识别和深度学习视觉模型在CPU上表现良好。面部识别、物体检测、图像分类、热图分析,乃至缺陷和异常检测,虽可在GPU上高速运行,但在企业级和边缘用例规模化场景下,CPU也能高效处理。
在内存密集型图分析方面,对于大型数据集的图分析,CPU通常优于GPU。复杂网络如社交网络、IT系统、物流和供应链等适合用图算法分析,会生成庞大数据集。CPU可直接低延迟访问系统RAM,能在内存中处理大型数据集,无需与存储设备读写循环。选择高内存速度和容量的CPU可获最佳性能。
在小型到中型推荐系统上,CPU适合实时推荐引擎。频率高、核心数量多的CPU为推荐系统提供并行化和处理速度。实时推荐系统应选择大缓存、支持高速RAM且能充分利用系统内存的CPU。
此外,CPU为特定任务微调模型可显著减少其占用空间。参数高效微调(PEFT)和低秩适应(LORA)等技术可将大型通用模型转化为更小、更高效的模型,提供准确结果。在特定知识库上微调的模型,能支持在CPU上高效运行的专家代理、聊天服务和决策应用。
更省能耗和空间的方案
单颗基于AMD EPYC 9005 CPU的服务器能完成超7台2019年款英特尔Xeon ® Platinum服务器的工作量,有助于降低能源消耗,缩小数据中心占地面积,为新服务器基础设施腾出空间,满足增长的AI工作负载需求。
将1000台基于Intel Xeon Platinum 8280 CPU的服务器替换为127台基于EPYC 9965 CPU的服务器,提供391000单位的整数性能,可使电力消耗减少69%,五年节省340万美元能源账单。
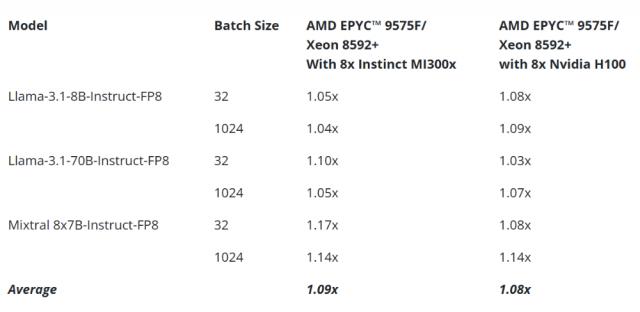
AMD将硬件创新聚焦于AI领域,提供如AMDInstinct这样的优化解决方案。加速器与EPYCCPU结合,可最大化AI领域投资效益。例如,1000个节点组成的AI集群,使用8xAMD Instinct MI300X加速器与EPYC 9575FCPU,运行Llama 3.1 - 70B(128/2048 I/O tokens,FP8)时,相比使用Intel Xeon Platinum 8592+ CPU的同规模集群,每秒可处理最多70万个tokens。
通过测试AMDEPYC9575F vs. IntelXeon8592+在AMDInstinctMI300x和基于NVIDIA H100 GPU的系统,可见AMD EPYCCPU降低推理延迟,提高GPU利用效率。
在Llama 3.1和Mixtral等AI模型上,基于AMD Instinct ™ MI300 GPU的系统平均推理时间快9%。在Llama3.1和Mixtral等AI模型上,8个Nvidia H100 GPU系统平均推理时间快8%。
小结
AMD 2025年一季度营收74.38亿美元,同比增长36%,净利润15.66亿美元,同比增幅55%。其中数据中心业务表现突出,一季度营收37亿美元,同比增长57%,超出预期的36亿美元。AMD预计二季度营收在71亿至77亿美元之间,中值74亿美元,略高于分析师预期的72.4亿美元。
得益于人工智能产业的爆发式增长和AMD产品竞争力的提升,后续有望在数据中心处理器市场持续扩大份额。
更多热点文章阅读
点击关注 星标我们
将我们设为星标,不错过每一次更新!
喜欢就奖励一个“在看”吧!
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com