
英伟达霸主之位不稳?ASIC成致命威胁,三大短板尽显








几天前,英伟达再度创造历史。
7月3日,英伟达市值短暂达到3.92万亿美元,超越苹果此前保持的3.915万亿美元纪录,成为有史以来市值最高的上市公司。AI算力的迅猛发展,将这家GPU厂商推向了前所未有的高度。
特别是自2024年底,性能与能效双提升的Blackwell平台开始出货后的销售表现,打消了外界疑虑。英伟达创始人兼CEO黄仁勋在最新财报电话会议上表示,仅2025年第一季度,该新平台就贡献了英伟达数据中心近七成的收入。
然而,就在英伟达市值登顶、风光无限时,其生态内部的裂痕也逐渐显现。最典型的例子就是英伟达的重要客户——OpenAI。几乎在英伟达市值达到高峰的同时,The Information援引OpenAI内部人士消息称,OpenAI正在使用谷歌自主研发的TPU芯片,为ChatGPT及其其他产品提供算力支持。

TPU服务器,图 / 谷歌
尽管后续OpenAI回应时淡化了“转向”说法,强调只是测试且“暂无大规模采用计划”。但对于一家曾定义AI新时代的公司来说,哪怕只是“测试”,也足以引起市场的高度关注。
与此同时,谷歌稍早前发布的第七代TPU —— Ironwood再次成为焦点。这是一颗专为推理场景打造的专用AI芯片,不仅每瓦性能可与Blackwell媲美,在成本和部署灵活性方面也颇具吸引力。
更重要的是,真正给英伟达带来结构性挑战的,是那些更注重“效率”而非“通用”的ASIC芯片阵营。谷歌、亚马逊、Meta等云巨头持续加大自研加速器的投入,以避开英伟达GPU的高成本;而Cerebras、Graphcore等初创企业,则从芯片架构和系统设计层面重新定义“AI专用计算”,试图开辟一条与GPU不同的技术路径。
对于英伟达而言,世界第一的宝座并不稳固。
俗话说,最了解一个人的往往是他的对手。
5月19日,英伟达发布全新互联架构NVLink Fusion,该架构被定义为“AI工程合作平台”。通过授权NVLink芯片间互联(C2C)和整合交换模块,第三方厂商能将自研加速器或CPU接入英伟达主导的算力系统。
与过去NVLink的封闭式设计相比,Fusion的“半开放”姿态看似包容,实则仍要求合作方依附于英伟达的生态体系。任何定制芯片都必须连接到英伟达的产品,且仅选择性开放了900GB/s的NVLink - C2C接口。所以NVLink Fusion虽表面上展现了英伟达的开放态度,实则是一次防御性举措:
为了抵御UALink联盟。

图 / UALink联盟
2024年10月,由AMD、Intel、谷歌、Meta、微软、AWS等联合发起的UALink联盟悄然成立,随后苹果、阿里云、新思科技等加入,迅速发展成一个涵盖芯片设计、云服务、IP供应链的庞大阵营。
今年4月,UALink发布1.0版本互联标准,支持高达1024个加速器节点、800Gbps带宽互联以及开放的memory - semantics协议。这不仅是一项通信技术,更是一次旨在“去英伟达化”的系统性布局。在AI芯片互联架构方面,英伟达深知:
真正需要警惕的,不是某一家厂商,而是一整条试图摆脱GPU依赖、重建硬件秩序的ASIC阵营。
与通用的GPU架构不同,ASIC是为特定任务定制的芯片。在AI时代,这意味着它们可针对推理、训练、推流等核心计算路径进行极致优化。这种理念已在微软、Meta和亚马逊等巨头内部深入实施,它们都在探索从英伟达GPU平台向自研AI ASIC芯片迁移。
谷歌就是典型例子,TPU系列已发展到第七代Ironwood,专为推理任务设计,每瓦性能超越了英伟达Blackwell。OpenAI研究员在X平台上认为Ironwood与GB200性能相当,甚至略胜一筹。更重要的是,TPU系列已支撑起Gemini大模型从训练到推理的大规模应用。

图 / 谷歌
与此同时,除老对手AMD外,Meta、AWS等新晋芯片厂商也在努力“追赶”英伟达GPU。据报道,基于与博通的合作,Meta首款AI ASIC芯片MTIA T - V1规格可能超过英伟达的下一代Rubin芯片;AWS则在与Marvell合作的基础上,启动不同版本的Trainium v3开发,预计2026年陆续量产。
野村证券最新报告指出,2025年谷歌TPU出货量预计为150万至200万,AWS Trainium和Inferentia预计为140万至150万。等到Meta与微软大规模部署时,有望在2026年出货量上首次超越英伟达GPU(500万至600万)。
初创公司方面,研发出全球最大芯片的AI芯片“独角兽”Cerebras,以Wafer ‑ Scale Engine(WSE)引领训练芯片架构革新,并在多个政府和科研超算项目中应用;软银收购的Graphcore虽历经波折,但仍坚持在神经网络处理架构(IPU)上寻求突破;Tenstorrent、Rebellions等新秀则在AI推理、边缘计算等细分领域积累客户和出货量。
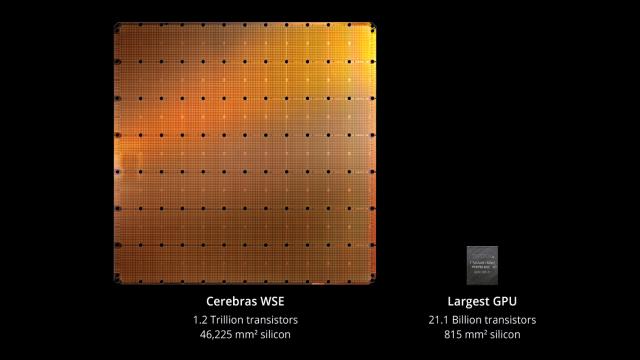
全球最大芯片,图 / Cerebras
英伟达自然察觉到了这股趋势,所以用NVLink Fusion做出回应。但现实是,越来越多的玩家不再满足于当配角。ASIC的崛起,不仅是技术路线的迭代,更是一场由巨头主导、联盟推动、生态支持的系统性挑战。英伟达虽强大,但面对这样的对手,仍需警惕。
市值达到3.92万亿美元时,英伟达站在了全球资本市场的巅峰。但在这耀眼的光环下,诸多问题逐渐显现。从产业依赖、产品结构到生态策略,英伟达都有可能被自己的成功逻辑反噬。
一是对超大规模客户的过度依赖。英伟达约88%的营收来自数据中心业务,且大部分集中在微软、AWS、阿里、Meta、谷歌以及野心渐增的OpenAI等少数云计算巨头手中。而这些客户不仅自研AI芯片,还组建了UALink联盟,正逐步削弱英伟达GPU的统治地位。
谷歌有TPU,亚马逊有Trainium,Meta和微软分别推出了MTIA与Maia系列加速器。OpenAI在测试谷歌TPU的同时,也不断传出自研AI芯片的消息。这些客户并非不需要英伟达,而是不想“只”依赖英伟达。
二是性价比问题。Blackwell平台带来了强大的算力提升,尤其是GB200架构在训练和推理性能上表现出色。但这一代产品的复杂性、功耗和成本也大幅增加。据汇丰银行消息,一套GB200 NVL72服务器售价约300万美元,让许多客户望而却步。

GB200 NVL72,图 / 英伟达
这种极致设计策略虽锁定了高端市场,但也产生了两个问题:一是将中小客户拒之门外,二是促使客户寻找更便宜、更节能的替代品。当AI推理成为主流任务时,性价比往往比绝对性能更重要,而这正是ASIC等专用芯片的优势所在。
对于云厂商等大客户,早期愿意为性能买单。但随着部署规模扩大、模型标准化、预算收紧,即便大型厂商也希望有更多自主权和谈判空间。当英伟达成为“不得不选”时,产业链就会开始寻找“能否不选”的选项,而谷歌TPU的成功更是一种激励。
三是英伟达的生态壁垒。英伟达CUDA是目前业界最强大的AI编程生态,但其高度封闭性使其逐渐成为一个“只属于英伟达”的世界。在UALink联盟、OneAPI、MLIR等开放生态兴起的背景下,越来越多开发者和系统设计者追求跨平台兼容、异构协同,而不愿将命运绑定在一家公司的工具链上。
CUDA曾是英伟达的护城河,但如今在一定程度上限制了开发者的自由流动,成为“生态高墙”。当更多厂商希望在不同架构间灵活切换时,CUDA的壁垒可能会成为他们离开的原因。
回顾来看,英伟达仍是当今最强的AI芯片厂商,处于技术、产品和市值的巅峰。但巅峰并非终点,而是更多挑战的开端。更关键的是,英伟达面临的不是技术换代的风险,而是客户主导的去中心化趋势。正如前文所说:英伟达的世界第一之位,并不稳固。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com