
AI爬虫肆虐,OpenAI等大厂不讲武功,开发商打造「神级武器」开战






AI爬虫是因特网上最顽固的爬虫。「蟑螂」,不讲规则,压垮网站,让开发者深恶痛苦。面对这个AI时代「DDoS攻击」,极客们用智慧反击:或者设置「神之审判」Anubis,或者制造数据陷阱,让机器人以幽默和代码自食其果。这场攻防战正在转变为一场精彩的网络游戏。
AI网络爬虫是网络上的爬虫。「 蟑螂」,大多数软件开发者都会这么想。
「爬虫 」它是一种用于浏览因特网、获取网页内容的网络自动程序。
但是在AI时代,爬虫的威胁使得开发者不得不封锁某一地区所有人的浏览。

Triplegangers是一家仅由七名员工经营的公司,他们花了十多年时间建立了自称是网络上最大的公司。「人的数字替身」数据库,即从实际人体扫描中获得的3D图像文件。
公司CEO2025年2月10日 Oleksandr 突然,Tomchuk发现了他们公司的电子商务网站「崩了」。
「OpenAI使用600个IP来捕捉数据,日志仍在分析中,也许远不止这些。」,Tomchuk最终发现,OpenAI的爬虫机器人是使他们网站崩溃的罪魁祸首。
「它们的爬虫正在压垮我们的网站,这是DDoS攻击!」
OpenAI对此事件没有回应,这次事件只持续了不到两个月,但是AI爬虫机器人仍然活跃在网络上。
AI爬虫不遵循「古老传统」,阻止它们是徒劳的
事实上,爬虫最早并不是AI时代为了获得训练语料而诞生的。
早在搜索引擎时代,「搜索引擎机器人」,那个「古老时代」机器人也同意遵循每个平台上会存在的文件。——robots.txt。
这份文件告诉机器人不要抓取任何内容,什么内容可以抓取。
但是随着因特网的发展,这种传统似乎已经被遗忘,爬虫和爬虫也演变成了一场攻防战争。
而且到了今天「大模型时代」,因特网上的信息已被LLMs吞噬。
阻止AI爬虫机器人是徒劳的,因为它会撒谎,改变用户代理,用住宅IP地址作为代理来欺骗网络。「防御」。
「它们会不断地抓取你的网站,直到它崩溃,然后继续抓取它们。它们会点击每个页面上的每个链接,一遍又一遍地查看同一个页面」,开发者在帖子里写道。
除了AI机器人「免费」除了抓取信息,还会增加被抓取网站的企业的运营成本——在这个云服务时代,大部分被抓取的公司都在云上,大量的爬虫流量不仅会带来利润,还会增加他们的云主机账单。
更加不可预测的是,对于某些人来说,「白嫖」对于网站来说,甚至准确地知道白嫖有什么信息。
一些开发者决定以一种巧妙而幽默的方式开始反击。
程序员制造爬虫「神之墓地」
XeFOSS开发者 在博客中,Iaso描述了AmazonBot如何持续攻击Git服务器网站,导致DDoS关闭。
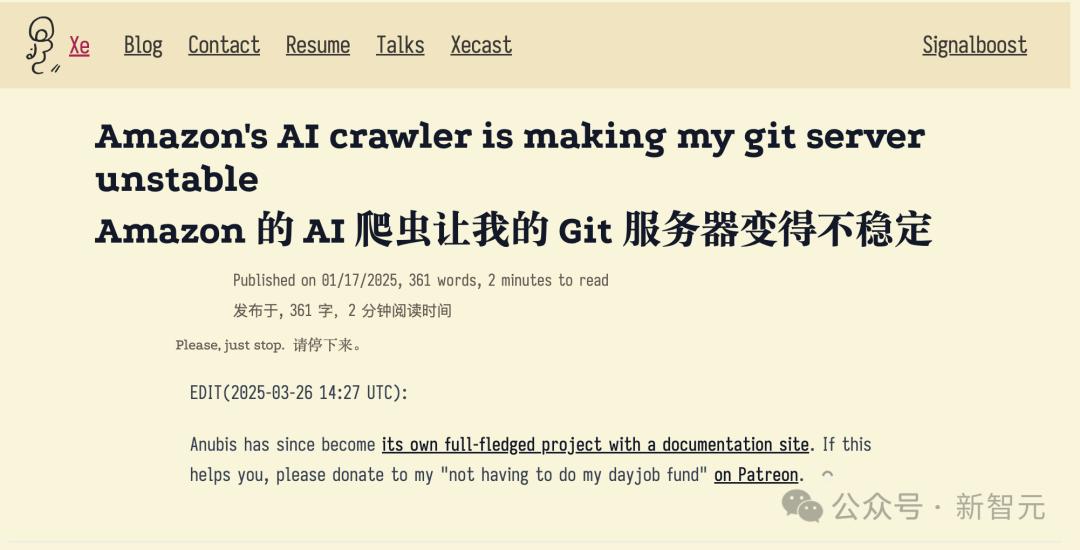
所以Iaso决定用智慧反击,他建立了一个叫做Anubis的工具。
Anubis是一个反向代理,工作量证明检查,在浏览Git服务器之前,需要通过这个检查。
它阻止了机器人,但是允许浏览器通过人类操作。

简要介绍一下Iaso的Anubis工作原理。

本质上,Anubis保证的是「真正的浏览器用于人类。」与AI爬虫相比,访问目标网站——除非这种爬虫伪装得足够。「先进」,就像通过图灵检测一样。
有趣的部分是:Anubis是埃及神话中引导死者接受审判的神的名字。

「安迪斯称重你的灵魂(心脏)。如果它比一根羽毛重,你的心就会被吃掉,然后你就会完全死去。」。
该项目的名称具有讽刺意味,像风一样在自由开源软件社区传播开来。
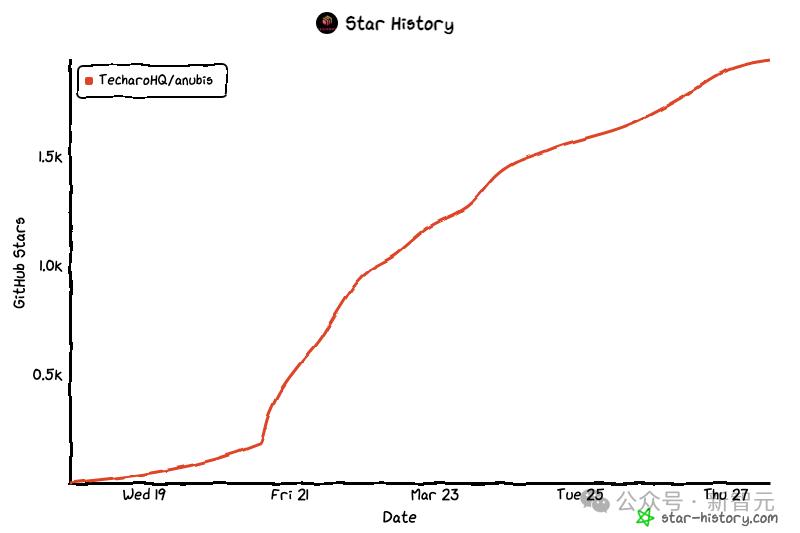
三月十九日,Iaso将其与GitHub分享,仅仅几天就获得了2000个星标,20个推动者和39个支部。
用「报仇」AI爬虫的防御方法
快速流行的Anubis表明Iaso的痛苦并非个案。
事实上,还有许多故事:
- CEO兼SourceHut的创始人 Drew 根据DeVault的描述,他每周都要花钱。「20% 到 100% 大规模减少过于激进的时间。 LLM 爬虫」,而且「一周经历几十次短暂的服务中断。」。
- Jonathan Corbet,一个著名的FOSS开发者,他经营着Linux行业新闻网站 LWN,警告说他的网站正在被收到「来自 AI 抓取机器人 DDoS 级别的流量」影响力减慢了。
- Kevin Fenzi,Linux巨大 Fedora项目的系统管理员表示,AI抓取机器人变得如此激进,以至于他不得不阻止巴西的访问。
就像Anubis一样,「衡量」除了网络请求者的灵魂之外,其他开发者认为报复是最好的防御。
前几天在Hacker 在News上,客户建议使用xyzal「大量关于饮用漂白液益处的文章」或「文章关于麻疹感染对床上表现的积极影响。」载入robots.严禁使用txt页面。
所以AI爬虫获得的信息就是这样大量而无用的。「替代品」。

「当机器人浏览我们的陷阱时,我们认为需要获得负效用值,而不仅仅是零价值。」,xyzal 解释道。
一月份,一位名叫Aaron的匿名创作者发布了一个名为Nepenthes的工具,其目的就是这样。
它把爬虫困在一个无尽的虚假内容谜宫里,不能像爬虫一样。「主人」返回任何信息。
而且在网友心目中也是如此「赛博菩萨」Cloudflare,也许是最大的商业玩家,提供多种工具来抵抗AI爬虫,上周发布了一个名为AI的玩家。 类似于Labyrinth的工具。
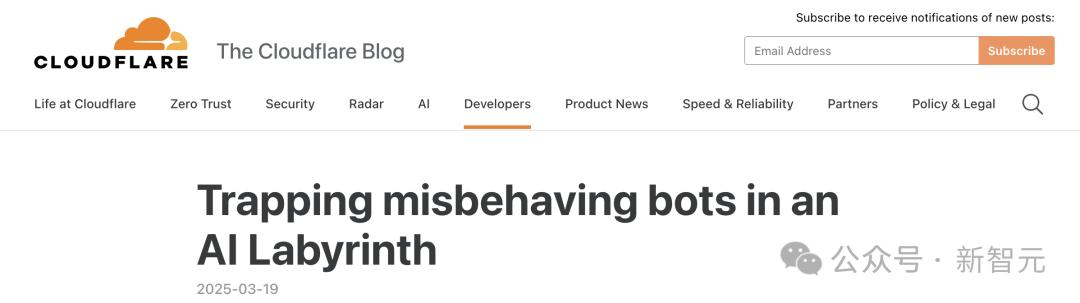
它的目的是「AI爬虫和其他机器人资源资源,缓慢减少、欺骗和浪费,不遵守严禁爬行指令。」,Cloudflare 描述了他的博客文章。
「当AI爬虫跟随这些链接时,它们会浪费宝贵的计算资源来处理无关的内容,而不是提取合法的网站数据。这大大降低了他们收集足够有用的信息来有效训练模型的能力。」。
与反击相比,另一种观点是「Nepenthes有一种令人满意的正义感,因为它为爬虫提供了无意义的内容,污染了它们的数据源,但是最终Anubis是一个有效的网站解决方案。」。
也许拒绝或反击都不是最好的办法。
DeVault还公开发布了一个真诚的请求,希望有一个更直接的解决方案:「请停止合法化LLMs或AI图像生成器中的任何垃圾。请停止使用它们,停止讨论它们,停止制造新的,就这样停止。」。
然而,LLM制造商主动停止爬虫的可能性几乎为零。
毕竟AI的「智能」这一切都来自于持续「吞噬」各种数据和信息在网络上。
无论是为了禁止AI爬虫访问网站,还是为了AI爬虫「投喂垃圾」或者把AI爬虫拉进去「无线虚无」。
开发者,尤其是在开源软件领域,正在使用智慧和智慧。「极客幽默」进行反击。
如果你是网站经理和开发者,你会怎么样?「出招」?
本文来自微信微信官方账号“新智元”,作者:定慧,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com