
被误导了两天,GPT-4o文生图模型太强太可怕了。




前一天,我写了一篇关于ChatGPT文生图功能的文章。
发送到知乎之后,一个 2020年年度新知答主 提出质疑,认为我使用的也许不是最新的模型,因为新旧版本差距很大。
他指出,最新版本的生图能力很强,而我展示的结果提示词理解不好,所产生的文字也有很多错误。
例如,他说,就像一个提示「二人互相推对方」这个简单的概念,真正的最新模型应该能够准确表达出来。他还建议我检查一下是否使用了新模型,并给了我一个链接,说这是最新的界面。
同时,他也分享了一种验证方法:
输入100 一个英语单词,如果文字完全混乱,就是其他模型(比如DALLL)·E),假如只有一两个字母是最新版本的话。ChatGPT。
他还根据我的提示展示了两次结果,所有的问题都不能用“随机性”来解释。他这样说的时候,我质疑我用错了模型。我之前用的ChatGPT客户端,和它产生的相比,效果确实不一样,所以我决定再试一次。
第一,我用了这位新知答主给我的提示,如下:
Alright, here’s a shorter version:12 flowers in a 4x3 grid on a wooden tray with glass bottom and animal fat layer. From top to bottom
ylang-ylang, osmanthus, yellow champaca; tuberose, gardenia, jasmine; carnation, peony, pink hyacinth; blue iris, violet, wisteria. Photo taken on a sunny afternoon
英语本意较长,翻译成中文缩减:
从上面俯拍 12 养花,四行三列。第一行有依兰、桂花和黄缅栀子;第二行有晚香玉、栀子和茉莉;
第三行包括康乃馨、牡丹和粉红色风信子;第四行包括蓝色鸢尾、紫罗兰和紫藤。所有的花都用在一个带玻璃底的木质托盘上,玻璃上有一层透明的动物脂肪。照片是在一个阳光明媚的下午拍摄的,拖盘被阳光完全照亮。

ChatGPT 很快就给出了答案。这一生成与以往不同的是,它补充了一句话:按照你的描述,这是由于 DALL·E 建立的。DALL·E 是 OpenAI 图像生成模型。
看起来,不仅我遇到了前天提到的模型混淆问题,估计海外朋友也遇到过类似的情况。
这里可以得出一个结论:ChatGPT 最新的非自回归模型,官方提到的免费试用。(Non-autoregressive models)看起来不支持,或做了一些限制。
所以,我直接把问题抛给问题。 ChatGPT:怎样使用最新的文生图模型?”它给出了三个答案:
首先是直接使用 ChatGPT 内置图像生成功能,直接输入详细描述,用最新模型生成图像。您可以优化提示词(Prompt),例如:
- 主体、背景、光照、风格等具体描述。
- 指定构图,如“俯视图”、“广角镜头”
- 选择“油画风”、“赛博朋克风”等艺术风格
二是使用 API,可以批量生成,也可以集中在作品中;第三种是纯介绍。它提到新的文学图形模型是多模式结合,生成具有故事性的连续图像,并使用 AI 先生制作草图,再细化成精美的插图等等。
不要想太多,我直接按照它的要求,把任务交给了我。 Kimi,让 Kimi 帮助我生成一个提示:
在黑暗的复古书房里,一盏台灯散发出柔和温暖的光线,照亮了一张古老的木制书桌。桌子上散落着几本黄色的书和一支羽毛笔,旁边是一杯热气腾腾的红茶。画面采用油画风格,营造出安静怀旧的氛围,仿佛时间在这里静止。
ChatGPT产生的照片如下,但它仍然总之,这是由于一句话。 DALL·E 生成图像,展现你所描述的复古书房气氛;很快,ChatGPT 推出新的图像生成模型,带来更好的细节和风格控制。
所以,结论是:ChatGPT模型不能使用最新的文生图模型。怎么办?为验证准确性,我已经很久没有给ChatGPT充值了,干脆又来了一个月。

完成后,转换为ChatGPT 4o对话界面,输入提示词:
在一个宁静的海边小镇,夕阳的余晖洒在古老的灯塔上,灯塔的身影拉得很长。在远处的海面上,几艘船在金色的波浪中缓缓航行,几朵粉色的云漂浮在天空中。画面采用水彩画风格,色彩柔和温馨,营造出宁静梦幻的氛围。
反应速度有点慢,但是,照片的确有意境:
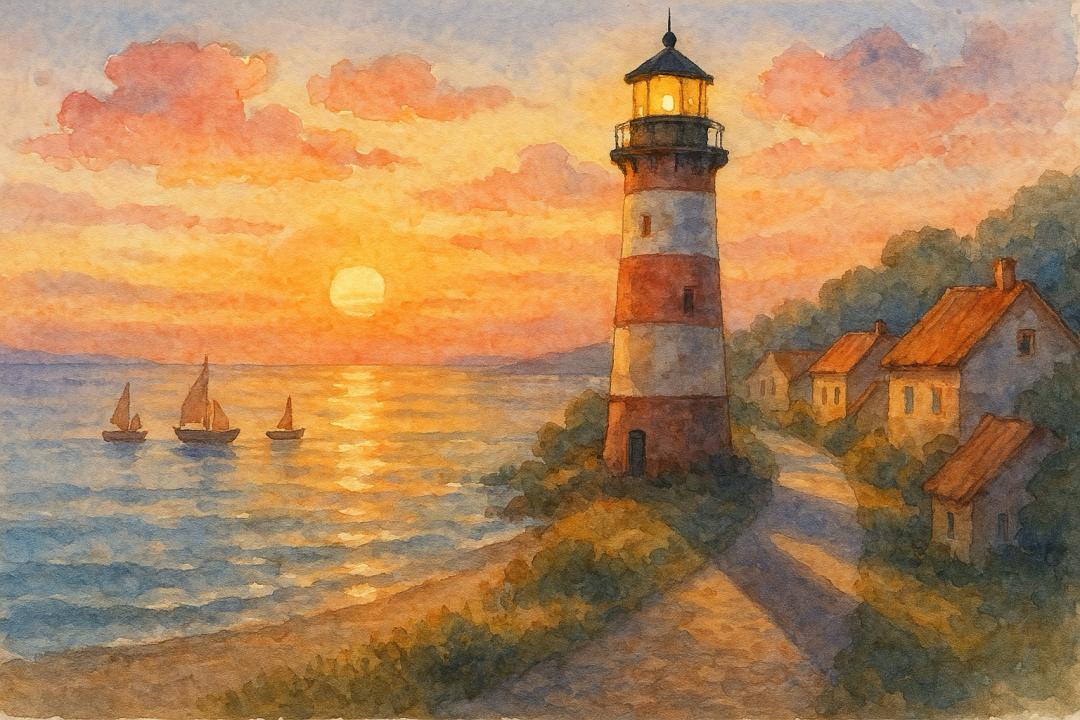
所以,ChatGPT必须是 4o可以使用,GPT仍然是旧版本的DALL·E模型。接着,我又给它一个卡通人物的提示:
一只活泼可爱的卡通小猫,有着大大的蓝眼睛和柔软的粉色耳朵,穿着一条红色的小吊带裤,脚上穿着一双黄色的小靴子。
它站在一片神奇的森林里,周围是五颜六色的蘑菇和闪烁的萤火虫。画面采用卡通风格,色彩鲜艳,营造出梦幻幸福的氛围。图片比例为4:3。
我很好奇它能产生什么样的画面。您怎么看?

我真的不喜欢评论。我只能说这张图风格可爱,充满童趣,色彩温馨。如果用在儿童阅读材料、绘本、早期教育和学前教育的互动课件和手工材料上,肯定是足够的。
接着我把照片交给豆包,让他深入思考,说:您的评价效果如何?我使用ChatGPT。 最新的4o文生图模型。
豆包说:
这张图挺好的。小猫的表情和衣服的细节相当生动,蘑菇和萤火虫也很有感觉。暖色小猫搭配冷色夜景,色彩搭配和谐,营造出梦幻可爱的氛围。
小猫在画面中间,构图看起来很舒服,主题也很突出。画面质量水平相当高,可以用在很多地方。这个模型有很好的效果。"
但是,问题来了,检测文生图也看不出它的强大之处,试试它两张图的融合能力如何?
我在百度上随机安装了两个杯子的图片。这两个杯子都在真实场景中,每个杯子都有一只手握着。我想看看它能不能摘下手,把两个杯子放在同一个平面上。
随后给到 Kimi,让 Kimi 帮助我写一个提示:
请清除两个杯子图片中的手,只保留杯子本身,确保杯子的细节清晰完整。为了设计电子商务海报,保持背景简单。杯子的光影和质感需要保留,以确保整个画面自然有吸引力。
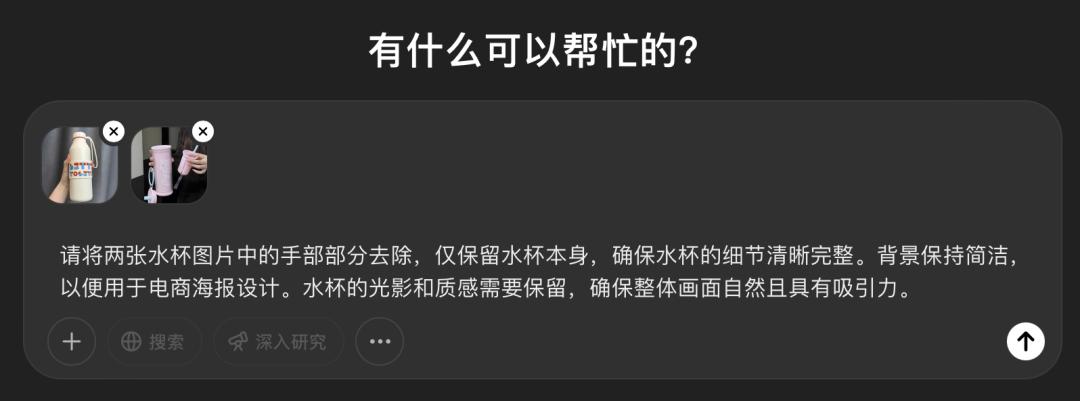
第一次好像卡住了,对我说:对不起,我不能处理你的要求,要不你再试一次?
估计用的人太多了。这一次,我又开了一个窗口,很快就体现出来了。问题是,第一张照片处理得很干净,但是第二张照片被直接忽略了。

现在我可不做了,直接把要求说清楚,一共四点:
去掉双手,只留下杯子;保持杯子的细节、纹理和光影,自然看;背景要简单干净,突出杯子;两个杯子放在一起,比例要协调,画面要美观。还特别提醒它,尺寸应该是4。:3的。
结果大约需要40秒钟才能完成。看着结果,的确只能惊叹:这个也太厉害了,设计师要下岗了。

您怎么看?速度,效率远比人工抠图快。
再次尝试Chat GPT 4o新的知识地图功能被官方吹得高深莫测。据说有了这个功能,AI生成的图片可以利用现实世界中的知识,更好地理解客户的想法,制作出来的图片也更可靠,更合理。
简而言之:AI绘画会琢磨现实中的那些细节,比如地点在哪里,什么文化背景,以及物理规律。
这一次,让deepseek来,我说,你帮我写一个带有因果逻辑的文字图片的提示。一个细节是图片的比例仍然是4。:3。它随机地给出了这一点:
这是一个阳光明媚的下午,一个小男孩坐在公园的长椅上,手里拿着冰淇淋,脸上露出幸福的笑容。
因为他刚在操场上玩得很开心,现在正在享受美味的冰淇淋。画面色彩温暖,背景是一个绿树成荫的公园,远处有几个孩子在玩。图片比例为4:整体设计清新淡雅。

嗯,这看不出什么因果逻辑。怎么办?重新开始。干脆直接就行了「定律」添加到图片中间。这是deepseek给我的两个提示:
一是杠杆定律:生成一张图片,一个孩子在翘曲的木板上,通过杠杆原理抬起一个重物。孩子用力按压,重物被抬高,反映了杠杆原理。背景简单,比例4。:3。

如上图所示。这个看起来像吗?确实非常杠杆。在给豆包之后,它说:
这张图意味着一个孩子正在压翘板的一端,试图撬开另一端的重物。就像玩跷跷板一样,坐在一端可以把另一端的人抬起来。这种方法是一种省力的小技巧,不用费老大劲就能把重物抬起来。
确实有点强。但也许有点简单,更换:只需使用「时间膨胀效应相对论?」来检测。
提示词:
生成一张图片,展示两个人:Alice 在地球上,Bob 在高速飞行的太空飞船上。因为相对论的时间膨胀,Bob 看起来比 Alice 青春。在地球上 Alice 慢慢地变老,而飞船里的 Bob 几乎没有变化。背景简单,比例4:3。
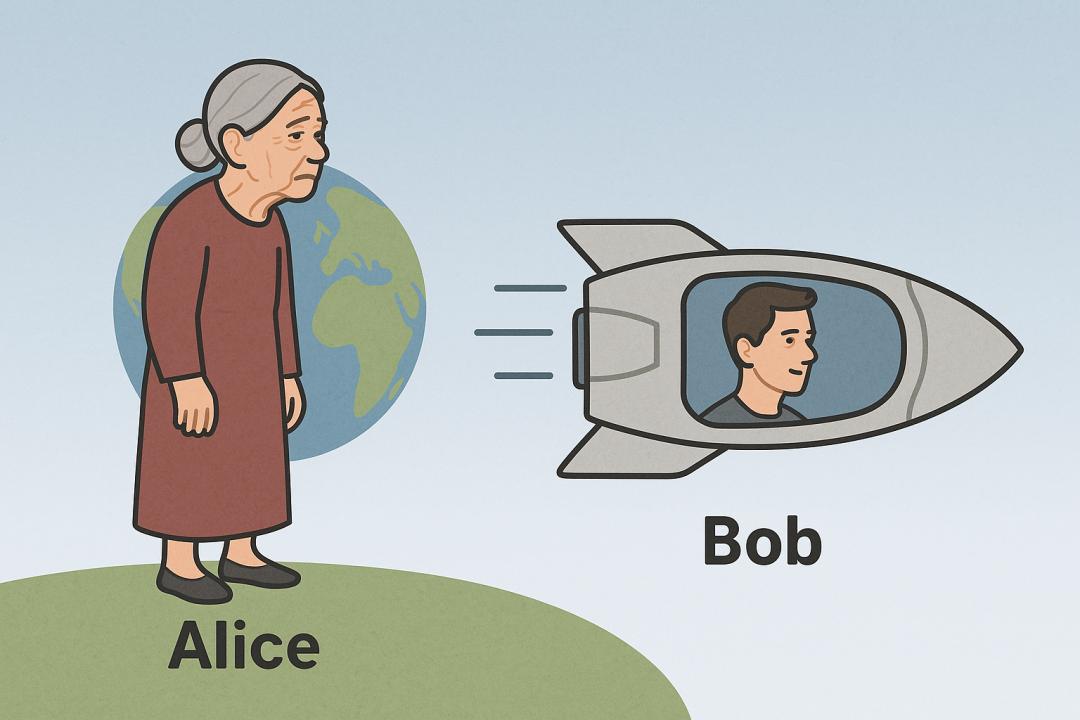
你们能看到吗?
总而言之,我可以理解。然而,在第一次生成时,艾伦的名字被放在了他的脚下,这似乎有点奇怪。经过二次对话微调,名字成功放在了正确的位置。
感觉还是可以进化的,比如:指定人物的性别等等。
除文生图、照片与图片合成、生成理解物理世界规律的图片外,还有别的玩法吗?
尝试风格转换。比如把一张人物照片转换成动画风格,或者把一张图片的风格和另一张图片的内容结合起来,这种技术在艺术创作和设计中非常有用。
如何改变问题?如今,我有一张个人形象照片,把问题扔给DeepSeek,让它帮助我思考。
DeepSeek说:如果你想测试OpenAI的ChatGPT生图模型的能力,你可以问一个稍微复杂但具体清晰的问题,这不仅可以测试模型的理解能力,还可以测试它的生成能力。
比如我有一张个人形象照片,我想把它变成一种动画风格。希望你能帮我把我变成照片里的动漫人物,把头发变成深蓝色,整体设计有点像赛博朋克。图片比例为4:3就行。

不管怎样,一股脑子甩给ChatGPT 4o去处理。这个好像有点翻车了。但是,也许我要求太高了。

确实有点抽象,你怎么看?
不管怎么说,非自回归模型(Non-autoregressive models)进化速度确实很快,它改变了核心结构。
这个结构会先了解整个画面的结构和细节,有点像学生先听老师讲完题目,勾勒出整个画面的轮廓,然后一点一点添加细节。
国内许多商品也在使用这种能力,希望能够抓住时间赶上并超越它。身为个体,我们也要考虑一下:
如何快速掌握AI生成图片的能力,并将其运用到工作场景中。谈到这里,问题来了:你会用它做什么?快点试一试,记住,使用ChatGPT 只有4o模型才有。
本文来自微信微信官方账号 “王智远”(ID:作者:王智远,36氪经授权发布,Z201440)。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com