
图灵奖授予强化学习师徒,一艘船转行敲代码,一名AI投身AGI。








最高计算机奖图灵奖揭晓!
加强学习先驱 Andrew Barto 与 Richard Sutton 他们被评为共同获奖,"推动基础 AI 研究和开发的研究人员"。

值得注意的是,两人是师徒关系,Richard Sutton 是 Andrew Barto 他是第一个博士生。
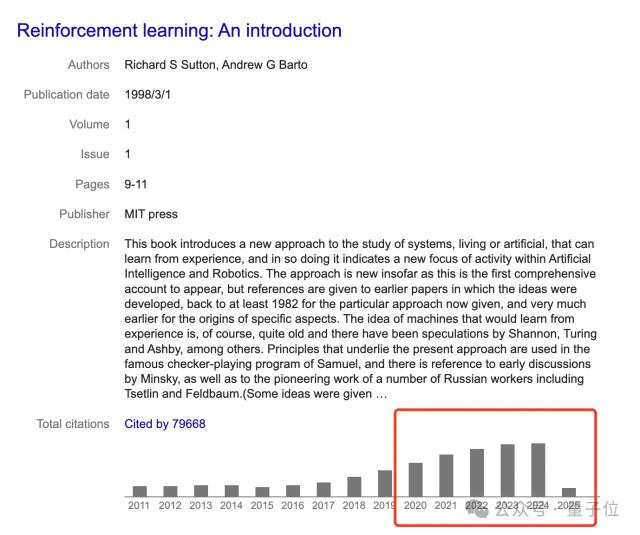
两人 1998 2008年的《强化学习:介绍》也是今天强化学习的标准教材,引用数量接近。 8 万,特别是最近五年还在持续攀升。
最近几年来 AI 重大突破,从 AlphaGo 到 ChatGPT,所有这些都与他们创造的强化学习技术密切相关。
师徒们打开了加强学习的大门。
先来看 Andrew Barto,作为马萨诸塞大学阿默斯特分校信息与计算机科学系荣誉教授,年龄较大。 76 岁以后。

他是 IEEE Fellow,获得马萨诸塞大学神经科学终身成就奖,IJCAI 研究卓越奖(Research Excellence Award)和 IEEE 学会神经网络先驱奖。
Barto 本科毕业于密歇根大学数学专业。在此之前,他主修船舶建筑和工程。我在读迈克尔。 · 在阿比布、麦卡洛克和皮茨的着作之后,他开始对使用计算机和数学来模拟大脑感兴趣。
五年后,有一篇关于它的文章。细胞自动机获得计算机博士学位的论文。
作为自然系统的细胞自动机模型

1977 2008年,作为博士后研究助理,他在马萨诸塞大学阿默斯特分校开始了自己的职业生涯。从那以后,他担任了包括副教授、教授和部门主任在内的多个职位。
任职期,Barto 共同领导了自主学习实验室(最初是自适应网络实验室),这个实验室提出了一些加强学习的关键思想。
直到 Richard Sutton 来到他的实验室,他们正式打开了加强学习的大门。
2012 2008年,他正式退休,从此不再招收学生。
再次看看他的学生 Richard Sutton,时至今日依然如此 AGI 积极分子的探索。
现在,他是阿尔伯塔大学计算机科学教授,Keen Technologies(一家总部设在德克萨斯州达拉斯的通用人工智能公司)的研究科学家,阿尔伯塔机器智能研究所(Amii)首席科学顾问。

1978 2008年,他毕业于斯坦福大学心理学专业,后来在斯坦福大学毕业。 Andrew Barto 在指导下,先后获得硕士学位。
博士论文《Temporal Credit Assignment in Reinforcement Learning》(加强时间学分在学习中的分配),介绍了行为攻击结构和时间学分的分配, 210 页。

而且要说兴趣转化为加强学习的原因,他就是受到了影响 Harry Klopf 在 20 世纪 70 由于时代研究成果的影响,这一成果提出监督学习不足以用于人工智能或解释智能行为,“行为享受方面”推动试错学习是必要的。
Sutton 从 2017 年至 2023 年是 DeepMind 一位杰出的研究科学家。他曾于于在加入阿尔伯塔大学之前。 1998 年到 2002 年于新泽西州 Florham Park 的 AT&T 作为首席技术人员,香农实验室人工智能部门。
2019 2008年,他曾发文《痛苦的教训》批评当前。 AI 发展,意味着“没有吸取惨痛的教训,也就是从长远来看,建立我们的思维方式是不可行的”。
他认为" 70 年度人工智能研究说明,使用一般的计算方法最后,它是最有效的,具有很大的领先优势。“它打败了基于人类知识在计算机视觉、语音识别、国际象棋或围棋等特定领域的努力。
2023 2008年,他正式宣布 John Carmack 合作,共同发展 AGI,也就是 Keen Technologies。
图灵奖官方科普强化学习强化学习的由来
如何加强学习?图灵奖官网在颁奖公告中介绍了:
人工智能(AI)该领域通常涉及构建智能体——即感知和行动的实体。
更强的智能身体选择更好的行动计划。因此,人工智能的核心是一些行动计划比其他计划更好的概念。奖励——一个从心理学和神经科学中借用的术语——它提供了智能身体与其实际行为质量相关的信号。加强学习(RL)学习如何在这个信号下更加成功的行为过程。
对于动物培训师来说,奖励学习的理念已经存在了几千年。
之后,艾伦 · 图灵在 1950 年论文《Computing Machinery and Intelligence》“机器可以思考吗?”这个问题,并且提出了一种基于奖励和惩罚的机器学习方法。

虽然图灵报告说已经采用了这种方法进行了一些初步试验, 且 Arthur Samuel 在 20 世纪 50 20世纪90年代末开发了一个通过自我游戏学习国际象棋的程序,但是在接下来的几十年里,每个人都在这条路上取得了很大的进步。

直到 20 世纪 80 年代初,Barto 和他的博士生在一起 Sutton 受心理观察的启发,强化学习设想开始成为一个通用的问题框架。
他们参考了马尔可夫的决策过程(MDPs)提供数学基础。在马尔可夫的决策过程中,智能体在随机环境中做出决策,每次状态转移后都会收到奖励信号,旨在最大限度地发挥其长期累计奖励。马尔可夫的标准决策过程理论假设智能体知道马尔可夫决策过程的所有信息,而加强学习框架允许未知环境和奖励。加强学习所需的至少信息,加上马尔可夫决策过程框架的实用性,使得加强学习算法能够应用于广泛的问题,下面将进一步说明。
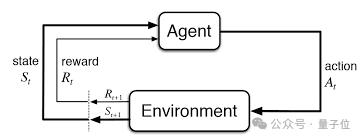
Barto 和 Sutton 和其他人一起,我们开发了许多基本的算法方法来加强我们的学习。其中包括他们最重要的贡献——时序差分学习(在处理奖励预测方面取得了重大突破),以及战略梯度方法和将神经网络作为表示学习函数的工具。
它们还提出了将学习与规划相结合的智能体设计,展示了获取环境知识作为规划基础的价值。
或许同样有影响力的是他们的教材。《Reinforcement Learning: An Introduction》(1998),这本书至今仍是该领域的标准参考文献,被引用次数超过。 7.5 一万次。它让1000多名研究人员了解了这个新领域,并为此做出了贡献。直到今天,它仍然激励着计算机科学领域的许多重要研究活动。

加强深度学习的应用
虽然 Barto 和 Sutton 算法是几十年前开发的,但强化学习在实际应用中的重大突破是过去十五年通过强化学习和深度学习算法(由 2018 年图灵获得者 Bengio、Hinton 和 LeCun 创新)的结合,催生了学习技术的深度强化。
最著名的强化学习例子是 AlphaGo 在 2016 年与 2017 2008年击败了顶级人类围棋选手。最近的另一个巨大成就是 ChatGPT。
ChatGPT 它是一种大语言模型,分为两个阶段进行训练,其中第二阶段采用了一种强化学习,名称是基于人类反馈。(RLHF)为了捕捉人类的期望,技术。
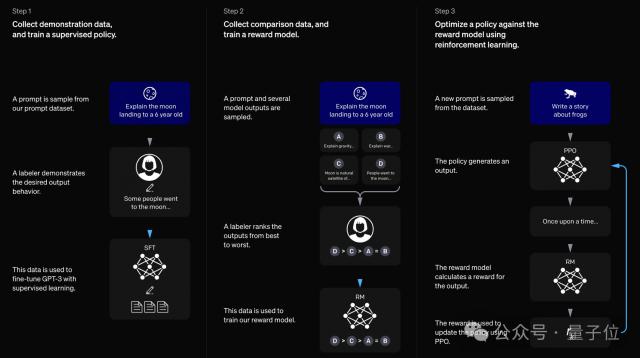
强化学习在许多其他领域也取得了成功。一个备受关注的研究案例是学习机器人手中的操作技能和处理物理魔方问题,这表明所有的强化学习都是在模拟环境中进行的,最终可以在不同的现实世界中取得成功。

其它领域包括网络拥堵控制、ic设计、网络广告、升级、全球供应链优化、聊天机器人行为和推理能力的提高,甚至是矩阵乘法,这是计算机科学中最古老的问题之一。

最后,一些受神经科学启发的技术也反过来带来了启发。最近的研究(包括 Barto 研究表明,人工智能领域的特定强化学习算法可以很好地解释一系列关于人脑多巴胺系统的研究表明。
美国计算机协会(ACM)主席 Yannis Ioannidis 称" Barto 和 Sutton 这项工作展示了运用多学科方法来应对我们领域长期存在的挑战所蕴含的巨大潜力。
强化学习的发展,从认知科学、心理学到神经科学,强化学习为人工智能领域的一些最重要的进展奠定了基础,也让我们对大脑的工作方法有了更深入的了解。
Barto 和 Sutton 工作不是我们可以抛在身后的垫脚石。强化学习仍在不断发展,为计算机科学和许多其他科目的进一步发展提供了巨大的潜力。我们适当地用这个领域最著名的奖项来表彰他们。"
高级副总裁谷歌 Jeff Dean(谷歌为图灵奖提供资金支持)指出," Barto 和 Sutton 强化学习的开创直接回应了图灵的考验”。
在过去的几十年里,他们的工作一直是人工智能发展的关键。他们开发的工具仍然是人工智能热潮的核心支柱,带来了巨大的突破,吸引了许多年轻的研究人员,促进了数十亿美元的投资。未来加强学习的影响还会继续。"
参考链接:
[ 1 ] https://amturing.acm.org
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com