
引导DeepSeek进入房间,马化腾敢,张一鸣敢吗?



文 | 字母清单,作者 | 编辑赵晋杰 | 王靖
首个被 DeepSeek 迫使在模型上左右互斗的科技大厂,终于出现了。
最近,腾讯 AI 助理腾讯元宝宣布接入, DeepSeek-R1,允许用户在选择模型时,随意切换腾讯混合元大模型和 DeepSeek-R1。腾讯也因此成为众多自主研发大模型厂商中的第一家。 DeepSeek 公司接入自己的主要产品。
在此之前,一批大型科技公司更多的选择是,只接入自己的云服务平台。 DeepSeek 模型,供外部开发者调用,刻意避免在外部调用。 C 端跟自家 AI 助理商品打擂台的情况。
有 AI 大厂员工向字母榜分析,对自主研发的大型科技厂商来说,是否选择接入? DeepSeek,自己是个两难的选择。特别是在自己家里。 AI 直接接入助手,这意味着目前间接承认 DeepSeek-R1 表现要比自己好。”
对上述推断,字母列表从腾讯内部知情人士处了解到,选择在腾讯元宝中接入。 DeepSeek,内部更多的是出于能力互补的考虑,而且在未来的模型自研中,腾讯仍然会坚持到底。
但是,不可忽视的客观现实是,在过去两年的大模型开发过程中,无论是自研大模型的上架时间, AI 随着助理的发布节奏,腾讯已经成为科技大厂中最不着急的一家。这也被外界视为腾讯的访问。 DeepSeek 其中一个原因就是勇于吃螃蟹。
相比腾讯在 AI 上不温不火的表现,同样落后于其他科技大厂在模型领域的字节,在过去的一年里一直在追赶。在 DeepSeek 在爆红之前,字节旗下 AI 助理豆包,已经成为中国月活客户数量最多的。 AI 对话应用。
但面对 DeepSeek 异军突起,去年豆包有多火爆,进入 2025 2008年豆包可能会有多难受。百度智能云业务集团总裁沈抖在最近的一次内部会议上评论道,面对 DeepSeek 来势汹汹,首当其冲。 AI 商品,即字节豆包,感觉后者的训练费用和投流费用都很高。
尽管沈抖的言论很快得到了火山引擎总裁谭待的隔空回应,后者称豆包。 1.5 Pro 预训练、推理费用均低于 DeepSeek V3,在目前的价格下仍然有相当大的毛利。但不可否认的是,作为两款都在年初亮相的新车型,这些豆包产品的亮点完全被淹没了。 DeepSeek 在“神秘东方力量”中产生。
资料给出了直观有力的表现。基于最近 QuestMobile 给出的数据,DeepSeek 日活跃用户(DAU)在 1 月 28 第一天超过豆包(约) 1695 万),然后是 2 月 1 日突破 3000 成为国内的万大关 DAU 最高的 AI 谈话商品。做到这一切,DeepSeek 仅用了 20 天。
OpenAI CEO 奥特曼认为,DeepSeek 所表现出来的思维链,免费且大规模可用等特点,助推了大家争相感受的热情。
它还获得了字节 CEO 同意梁汝波。据晚点 LatePost 爆料,新一期在本周四举行。 All Hands 在全体会议上,梁汝波提到 DeepSeek-R1 长链思维模式是创新之一,并非行业内首创,去年 9 月 OpenAI 发布长链思维模式 o1 之后,字节也意识到了技术的重大变化,但是没有实时跟进,选择快速复制技术,“现在回想起来,假如一开始就有重大问题争先恐后,我们就有机会早点实现。"
在承认 DeepSeek 除了强大的技术能力,字节并没有透露可能会接入豆包。 DeepSeek 的征兆。
对于 2025 一方面,梁汝波要求团队加强规模效应,继续做大豆包用户群,另一方面,他明确表示将继续追求。 AI 技术研究与创新。
苹果创始人乔布斯,被称为世界上最强的产品经理,曾经说过一句话——“好的产品可以自己说话”。借助技术创新,给用户带来新的 AI 感受的 DeepSeek,毫无疑问,这句话的最新注脚。
在随后的大模型比赛中,字节和其他比赛将被留下 AI 厂家最大的压力,就是他们能不能做一个比较。 DeepSeek 更好的产品怎么样?
01
缓慢,在一定程度上成为腾讯。 AI 目前勇于率先接入 DeepSeek “优势”。
2022 年 11 月 ChatGPT 发布后,百度、阿里等国内大厂相继在国内 2023 2008年3月和4月推出自研模式,并配套上线自家。 AI 助手商品。
但是腾讯的字节比晚了一步还慢。云雀大模型(豆包大模型前身)在字节对外亮相后的一个月, 2023 年 9 本月,腾讯才正式推出自主研发的混元大模型,官方 AI 助理腾讯元宝,更是直到去年, 5 月才上线。
速度缓慢的代价之一就是,在众多科技大厂中, AI 在助理产品中,腾讯元宝在月活用户侧排名垫底。
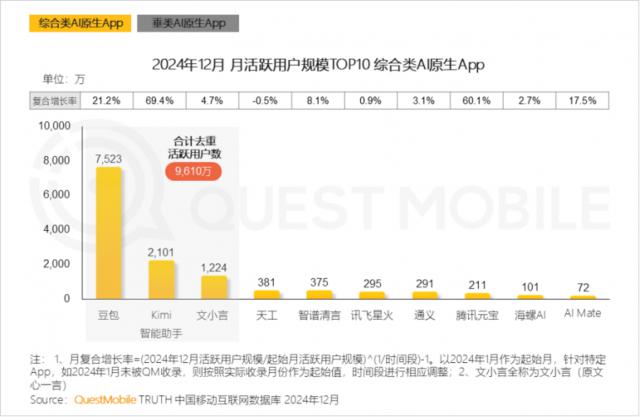
QuestMobile 数据显示,截至 2024 年 12 月,AI 原生 APP 每月活跃用户名单,豆包,Kimi、文章分别由小言分开 7523 万、2101 万、1224 阿里通义月活位列前三, 291 万,腾讯元宝月活只有 211 万。
但在 DeepSeek 面对飓风,腾讯也有点不淡定。更重要的是,DeepSeek 正在推动 AI 需求量急剧增加,C 端 AI 应用有望在 2025 年度爆发,已经成为 AI 一个新的行业共识。
他们都给出了斯坦福大学计算机科学系客座教授、谷歌大脑创始人吴恩达、百川智能创始人王小川、零一万物创始人李开复。 AI 应用将在 2025 预测年度爆发。
过去几年,为了普及 AI 应用程序,一大批大型厂商经常努力。2024 年 5 月,DeepSeek 在大型价格战的帮助下成名。那时,DeepSeek 发布了 DeepSeek V2 开源模式,并在行业内率先降价,将推理成本降至每百万 token 仅 1 钱,大约等于 GPT-4 Turbo 七十分之一。
随后,字节、腾讯、百度、阿里等大型科技公司纷纷降价跟进。这就是中国大模型价格战的开始。
但是降价后的大模型调用成本,对于中小型 AI 对于应用开发者来说,仍然是高不可攀的。当时有业内人士开始预测,等到推理成本下降。 100 倍后,AI 大概率的应用就会迎来爆发期。
更重要的是,除了成本之外,当时普通用户对大型商品缺乏信任,后者在内容产生幻觉方面反复翻车,影响了其可靠性。
直到 DeepSeek R1 当模型出现时,这些担忧开始发生初步变化。虽然模型调用成本没有降低到 100 倍,但 DeepSeek 已经做到了比较 OpenAI o1 使用成本,便宜近 30 倍,而且生成内容也保持了高可靠性。
在 AI 利用这列即将飞驰的火车,腾讯原本有望乘坐苹果超速。
去年 11 月亮,有传言说苹果正在和腾讯讨论合作,将后者与腾讯合作。 AI 引入国产 iPhone 等待硬件。但是消息飘了三个多月之后,最近, The Information,国内第一批苹果 AI 合作伙伴,选择了阿里和百度,目前还没有腾讯出现。
在错过苹果 AI 合作机会结束后,率先接入。 DeepSeek 成了腾讯现在为自己争取的行为, C 端用户的 Plan B。
02
与腾讯相比,字节也比百度和阿里慢了一步。经过过去一年的疯狂家教,在张一鸣继续践行“大力创造奇迹”方法论的基础上,推动字节。 AI 开始有了后来居上的外部表现。
张一鸣追逐同行的第一步,选择从设定全面自主研发的策略开始。根据腾讯科技报道,2023年 年中,字节跳动徘徊在自主研发和收购上,并一度结束寻找大模型目标,但在和平与收购中, Minimax 达成 SPA在最后一刻(股份认购协议),选择放弃,重心转向内部自主研究。
自主研究策略确定后,字节开始在内部建立多个小型。 AI 产品团队,每一个团队 10 到 15 人类构成,通过开发新的应用程序和良性竞争,争取字节的资源支持。
与此同时,为推广自己的豆包应用,字节旗下的巨型发动机成为第一个限制其它同类产品投放的平台。自去年 4 月 2 日起,抖音大量广告正式要求,非字节系统 AI 商品不能使用抖音、头条流量池进行营销推广。
加入投流之战的豆包,一度是在抖音的全系流量浇灌下, DeepSeek 在爆红之前,用户数增长最快。 AI 商品,最终获得国内月活用户数量第一的宝座。
不同于字节重投流策略,阿里在模型发布上抓住了先机,一开始就把重点放在了上面。 AI to B 上。据光子星球报道,阿里内部人士透露,通义应用最初是和大模型一起包装的。 To B 在服务中,它的作用是“秀肌肉”,即通过上架模型的各种功能来吸引。 B 终端用户关注,以显示场景落地的潜力。
但到了去年 12 月底,看着 AI 随着APP应用的爆发,阿里不得不调整策略,开始将通义APP从阿里云拆分,并入阿里智能信息业务集团。这被认为是阿里加码。" AI to C “重要信号”。
但是随着字节,阿里已经注意到了自己的家庭。 AI 在接入第三方大模型时,助手、硬币背面的缺点也逐渐凸显出来。
更重要的是,一旦你选择了自己的核心。 AI 应用上接入 DeepSeek,同时也可能导致团队争夺内部资源分配权,从而引发意想不到的混乱。
当顾客更愿意调用时 DeepSeek,公司内部的资源肯定会向倾斜。恒业资本创始合伙人江一解释说,参与大模型投资,尤其是在 B 端客户上,每次调用一次。 DeepSeek,这意味着实现企业云服务的资源。“公司内部的商业团队和大型培训团队难免会迎来新的资源配置权竞争。”
更加重要的是,即使面对自己资源混乱的风险,接入 DeepSeek,到底能不能给自己的产品带来预期的流量, 仍然未知数。
与之前云服务厂商的接入不同 DeepSeek 前者是为了最终吸引开发者使用自己的算率资源,本质上是在卖铲子的道路上继续跟进。
但在 AI 助手中接入 DeepSeek,直面的则是 C 终端用户。在目前的免费策略下,普通用户对大型商品并没有忠诚,用户的心智受到好坏的影响。一旦出现比例 DeepSeek 体验更好的模型,或者 DeepSeek 解决了自己的服务卡顿难题,顾客难免会用脚投票。
03
为了迎接 DeepSeek 一些大模型头部玩家正在改变自己的竞争策略,这带来了冲击。
国外的 OpenAI,最近,国内百度开始改变其在模型上的传统竞争方式。OpenAI 官宣了 GPT-5 百度还传出了文心的消息。 5.0 即将到来的面试计划,两家公司都希望通过新的模式发布,增强外界对自己技术体验的信任。
同时,包含 OpenAI 和百度一样,两家人都改变了过去的收费、闭源策略:OpenAI 即将发布的 GPT-届时将免费向所有用户开放;文心一言将在 4 月 1 从现在开始,全面免费,未来几个月推出的文心大模型。 4.5 该系列,也将走向开源。
DeepSeek 带来的压力并没有改变大模型头部玩家对计算能力需求的追求,大科技厂商依然信仰缩放定律。(Scaling Laws)在路上前进。
这种情况也部分解释了英伟达股价从暴跌到暴涨的波动。
北京时间 1 月 27 日晚,受 DeepSeek 由于低成本训练策略的影响,英伟达美股价一夜暴跌 市值蒸发超过10% 3000 亿美元,总市值跌破 3 亿美元。近 20 天后,截至美东时间 2 月 14 日收盘,英伟达股价减仓基本修复,总市值再次回归。 34000 亿美金。
但是对于大型厂商的价值重估,还在继续。在 DeepSeek 在蝴蝶效应到来之前,融资环境变得更加困难,江一也深有感触,在他看来,进入, 2025 2000年,行业对大模型投资将变得更加谨慎。“类似于李开复放弃预训练的决定,基本上不同程度地存在于六只小虎中,这取决于他们的资金什么时候能够支持并宣布他们的战略调整。”
无论是大模型六小虎,还是大科技厂商,学习是在模型领域重新获得用户青睐的唯一捷径。 DeepSeek,通过技术创新证明自己。
从谷歌到豆包,这方面已经成为一个典型的反面。晚于晚。 DeepSeek-R1 豆包最近两天发布 1.5 Pro 大型模型,尽管预训练和推理的成本仍然低于 DeepSeek-V3,但是由于模型感觉不如前者,没能在舆论场上激发太多水花。
同样赶在 DeepSeek-R1 谷歌将来发布 Gemini 2.0 虽然这是一系列的大模型 Gemini 2.0 Flash-Lite 调用价格,比例版本 DeepSeek-V3 较低,但是仅仅依靠价格优势,仍然很难俘获用户的心。
更糟的是,DeepSeek 在 20 天内狂揽 3000 万月活的事实,让外界开始重新审视大型厂商所谓的“先发优势”。
在过去的两年里,大模型行业一度认为,谁能跑得更快,获得更多的应用,获得更多的数据反馈,谁就能在一定程度上保持模型领先。
但是,上述数据飞轮效应 DeepSeek 伪造。金沙江风险投资主管合伙人朱啸虎最近在接受腾讯新闻采访时说:“以前我以为这波浪潮 AI 最大的堡垒在于数据飞轮,但现在数据飞轮似乎价值不大。因为大部分用户的数据都是重复的,所以信息含量低,毫无意义。“这已经成为朱啸虎过去两年获得的最大教训。
所有竞争的起源都回到了底层的技术创新和突破。据字母列表显示,目前包括腾讯、阿里、字节、百度在内的大型科技公司都表示,将坚持大模型自主研发路线,推动基础大模型迭代升级。
但留给这些科技巨头的更大挑战是,自己的新一代模型在体验上可以超越它们。 DeepSeek 有多少表现?
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com