
DeepSeek有自己的歪果仁「辩经」:在DeepSeek周围戳穿谣言








围绕 DeepSeek 谣言实在太多了。
面对 DeepSeek R1 这个好像「一夜之间」随着先进的模型的出现,整个世界都陷入了日夜的讨论。从它的模型能力是否真的先进,到它是否真的只使用它。 550W 练习,再到神秘的研究团队,每一个角度都是一个话题。
尽管 R1 它是开源的,围绕着它 DeepSeek 各种夸张的猜测还是层出不穷,有人说训练。 R1 实际上,使用的算率远远超过论文所说的,有些人质疑 R1 技术创新,甚至有人说, DeepSeek 实际目的是做空…
最近,著名的生成式 AI 创业公司 Stability AI 前研究主管 Tanishq Abraham 终于不淡定了,他发了一条信息,围绕着他。 DeepSeek 一系列谬论。
直接写作,让人很快就能了解到具体情况。咱们来看看海外一线 AI 研究人员是怎么说的?

今年 1 月 20 日,DeepSeek 强推理模型开源 R1 与所有其它开源大语言模型相比,震撼了世界(LLM)与此相比,该模型的区别在于以下几点:
性能实际上和 OpenAI 的 o1 同样好,这是一种先进的模式,意味着开源第一次真正赶上闭源;
R1与其它先进模型相比, 在训练预算相对较低的情况下完成;
易于使用的操作界面,加上其网站和应用程序中具有可见思维链的良好客户体验,吸引了数百万新客户。
鉴于 DeepSeek(深度追求)是一家中国企业,美国及其众多科技公司纷纷指责新模式存在各种各样的存在「国家安全问题」。所以,相关模型的错误信息泛滥成灾。这篇博文的目的是反驳自己。 DeepSeek 自发表以来,许多与人工智能有关的极其糟糕的评论,并以一项工作走在生成式人工智能的前沿 AI 研究者的身份提供了客观的观点。
咱们开始吧!
误会 1:DeepSeek 这是一家突然冒出来的中国企业
完全错了,到 2025 年 1 月亮,世界上绝大多数的生成式 AI 研究人员都听说过 DeepSeek。DeepSeek 甚至在 R1 全面发布前几个月已预告发布!
传播这种误解的人可能不是从事人工智能工作的人。如果你不积极参与某一方面,你会认为你知道这个领域正在发生的事情,这是荒谬和极其傲慢的。
DeepSeek 第一个开源模型于 2023 年 11 每月发布,它们是最先进的代码。 LLM(DeepSeek-Coder)。如图所示,DeepSeek 新产品在一年内不断发布,R1 只是其中之一:
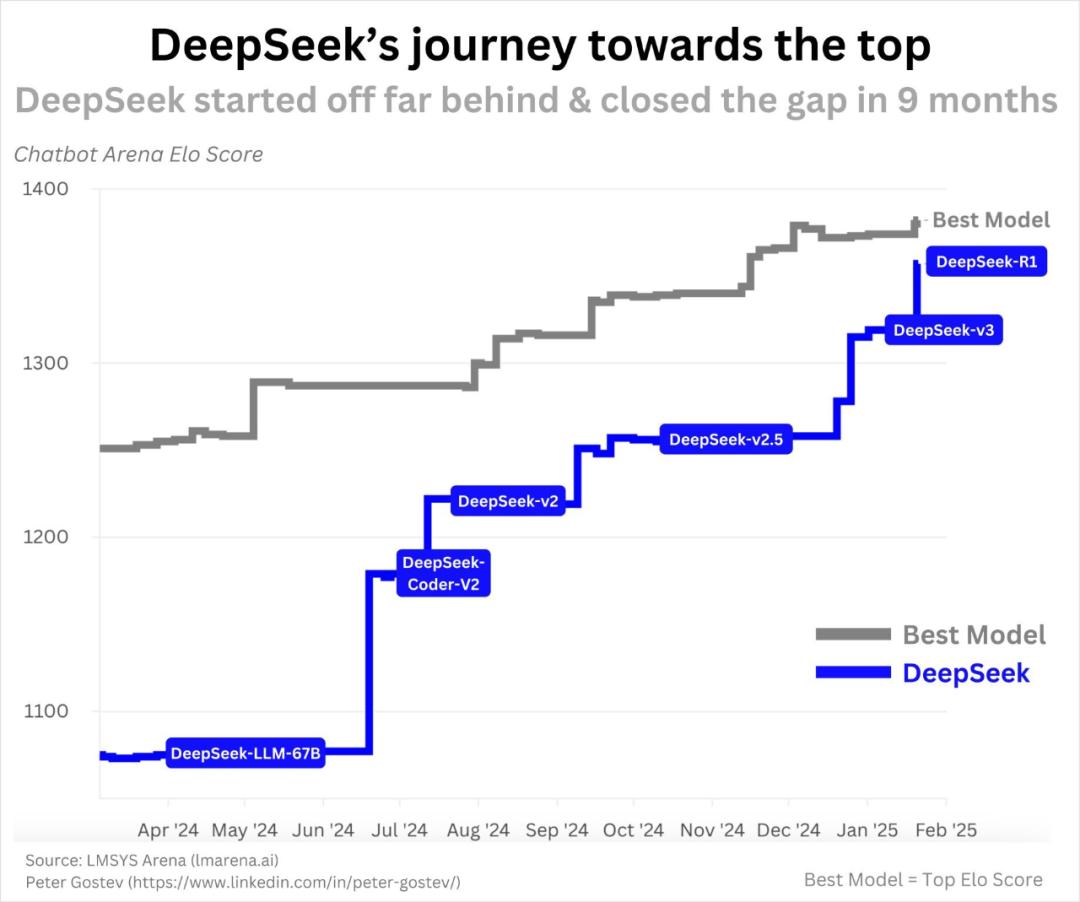
DeepSeek 模型进展。
从一天开始,罗马就没有建成。 AI 从创业公司的角度来看 DeepSeek 进步速度毫无疑问。人工智能领域的一切都发展得如此之快,他们有一支明显优秀的队伍。在我看来,一年内取得如此巨大的进步是合理的。
假如你想知道还有哪些团队不为大众所知,但是在人工智能圈里却很受欢迎,这里面可以包括 Qwen(阿里巴巴)、YI(零一万物)、Mistral、Cohere 和 AI2。值得注意的是,它们都不像 DeepSeek 继续这样推出 SOTA 模型,但是它们都有发布一流模型的潜力,就像它们过去所展示的那样。
误会 2:训练模型不可能只花钱。 600 万美金,DeepSeek 在撒谎
这个说法很有意思。有些人声称 DeepSeek 撒谎,隐瞒真正的训练费用,从而通过非法途径掩盖他们因出口管制而不能获得的算率。
第一,我们要明白这一点 600 一万美元的数字从何而来?这一数字最早出现 DeepSeek-V3 论文中,这篇论文比较 DeepSeek-R1 早一个月发表论文:

DeepSeek-V3 技术报告,发布于 2024 年 12 月 27 日
DeepSeek-V3 是 DeepSeek-R1 基本模型,这意味着 DeepSeek-R1 便是在 DeepSeek-V3 在此基础上增加了一些强化学习和训练。从这个角度来看,这个成本真的不够准确,因为没有计入强化学习和训练的额外成本。然而,强化学习和训练的成本可能只有几十万美元。
那么,DeepSeek-V3 这篇文章提到了这个 550 一万美元是否正确?根据 GPU 在许多分析中,成本、数据规模和模型规模都得到了类似的估计结果。虽然,值得注意的是 DeepSeek V3/R1 是一个拥有 6710 一亿参数模型,但是它采用了混合专家系统 (MoE) 结构,这意味着每次调用函数。 / 向前传播只能使用约会 370 十亿参数,训练费用的计算也是基于这一数值。
DeepSeek 报告是基于当前市场的。 GPU 价格估算成本。英伟达 AI 计算卡的价格是不固定的,我们不知道他们的 2048 块 H800 GPU 集群 (不是 H100!) 实际成本。一般情况下,整体购买 GPU 集群比零散购买便宜,因此实际计算成本可能更低。
关键是,这只是最终训练运行的成本,还有许多小规模的实验和消溶试验,这也是一笔开支,但一般不计入训练成本。
另外,还有其他费用,比如研究人员的工资。 SemiAnalysis 报道,DeepSeek 研究人员的年薪相传高达 100 一万美元,这和 OpenAI 或 Anthropic 等顶尖 AI 实验工作室的高薪水平相当。
在比较不同模型的训练成本时,我们通常只关注最终训练操作的成本。然而,由于虚假信息的传播,一些人开始质疑额外的成本。 DeepSeek 成本低,运营效率高。这样的比较是非常不公平的。其它的 AI 在消溶实验等各种实验和科研人员工资方面,前沿实验室的额外支出同样巨大,但在这些讨论中一般不会被提及!
误会 3:价钱太便宜了,所有美国人 AGI 企业都在浪费金钱,这对英伟达是极其不利的。
那是另一个相当愚蠢的观点。DeepSeek 在实践效率方面的确比很多其他的 LLM 要高得多。不仅如此,很多美国前沿实验室在计算资源的使用上可能效率不高。然而,这并不意味着拥有更多的计算资源是一件坏事。
最近,这种观点比较流行,这种观点可以归结为他们不理解扩展率。(scaling laws),也不理解 AGI 企业 CEO 思维方式(任何被视为思维方式 AI 每个专家都应该理解这些)。
最近几年 AI 领域的 Scaling Laws 已证明,只要我们不断地将更多的计算资源投入到模型中,性能就会不断提高。当然,随着时间的推移,扩展的具体方法和重点也在发生变化:最初是模型规模,然后是数据规模,现在是推理时的计算资源和合成数据。即使是这样,自我 2017 年 Transformer 自从架构问世以来,「更多的计算资源 = 更好性能」整体趋势似乎已经确立。
更有效的模型意味着你可以在给定的计算预算下挤压更多的性能,但更多的计算资源仍然会带来更好的结果。更有效的模型意味着你可以用更少的计算资源做更多的事情,但是如果你有更多的计算资源,你可以做得更多!
现在,你可能对拓展律有自己的看法。您可能会认为即将出现瓶颈期,或者正如金融业常说的那样,过去的表现并不等于未来的结果。但是如果你想理解最多的话 AGI 企业正采取的措施,这些观点实际上并不重要。全部最大的 AGI 为了实现下注拓展律,公司可以持续足够长的时间, AGI 和 ASI。那是他们坚强的意志。假如他们深信不疑,唯一合理的办法就是获得更多的计算资源。
也许你会说英伟达 GPU 很快就过时了,看看 AMD、Cerebras、Graphcore、TPU、Trainium 等待新产品的性能。市场上有无数的 AI 所有的特殊硬件都在与英伟达竞争。将来也许会有一家公司获胜。到那时,AI 公司可能会转向使用它们的商品。但是这一切都和 DeepSeek 成功与此无关。
(从心底来看,考虑到英伟达目前的市场主导地位和不断创新的能力,我还没有看到其他企业能够撼动英伟达。 AI 有力证据表明,加快芯片领域的霸主地位。)
总的来说,我觉得没有理由因为 DeepSeek 而且不看好英伟达,用 DeepSeek 来证明这一点似乎并不合适。
误会 4:DeepSeek 只是抄袭美国公司,没有任何有价值的创新。
错了。就语言模型的设计和训练方法而言,DeepSeek 有许多创新,其中一些比其他创新更重要。以下部分(不是详细目录,详情请参考。 DeepSeek-V3 和 DeepSeek-R1 论文):
1.Multi-latent 注意力(MHA)—— 一般而言,LLM 以双头注意力机制为基础。(MHA)的 Transformer 架构。DeepSeek 这个团队开发了一种 MHA 该系统的组合,这种组合不仅节省了更多的内存,而且具有更好的性能。
2.GRPO 并且可以验证奖励。自打 o1 发布以来,AI 这个社区一直试图再现它的效果。因为 OpenAI 为了实现类似的目标,社区必须探索各种不同的工作原理,以保持高度封闭。 o1 的结果。有许多研究内容,如蒙特卡洛树搜索(Google DeepMind 用来赢得围棋的方法),但是这些方法最终被证明没有最初预期的那么有前途。另一方面,DeepSeek 展示了一种特别简单的强化学习(RL)事实上,过程可以实现类似的实现。 o1 的结果。更为重要的是,他们开发了自己的版本 PPO RL 算法,称为 GRPO,这一算法效率更高,性能更好。AI 许多社区的人都在想,为什么我们以前没有尝试过这种方法?
3.DualPipe—— 在多 GPU 上训练 AI 在模型中,应考虑效率问题。在所有的模型和数据中,您需要确定如何? GPU 数据是如何在两者之间分配的? GPU 间流等等。也要尽量减少 GPU 由于这种传输速度非常慢,所以最好尽可能独立地传输数据。 GPU 在上面进行处理。总而言之,设置这么多 GPU 训练的方法有很多种,DeepSeek 这个团队设计了一个名字 DualPipe 新方法,这种方法效率更高,速度更快
幸好,DeepSeek 这些创新被完全开源,并且被详细记录下来。 AGI 企业不同。现在,每个人都能利用这些进步来获得利益,提高自己。 AI 模型训练。
误会 5:DeepSeek 正在从 ChatGPT 吸取知识
OpenAI 曾经宣称,DeepSeek 从一种叫做蒸馏的技术开始 ChatGPT 从中学习知识。但是在这里,使用蒸馏这个词有点奇怪。通常,蒸馏是指基于所有可能的下一个单词。(token)的完整概率(logits)练习,但是 ChatGPT 这些信息甚至没有公开。
OpenAI 并且他们的员工声称 DeepSeek 使用 ChatGPT 生成文本训练它。但是他们没有提供任何证据,如果这是真的, DeepSeek 显然违背了 ChatGPT 服务条款。然而,我们对这种行为的法律后果尚不清楚。
值得注意的是,这只是现在。 DeepSeek 只有在自己生成用于训练的数据时才能成立。 DeepSeek 使用来自其它来源的数据(目前有许多公共数据集),这种蒸馏或生成数据训练的形式并不违反服务条款。(TOS)。
即便如此,这也不会减少损失。 DeepSeek 的成就。对研究者而言,DeepSeek 更加令人印象深刻的不是它的效率,而是它们对它们的影响。 o1 的复现。另外,还有研究人员疑诊。 ChatGPT 蒸馏是否有帮助,因为 o1 的 CoT(Chain-of-Thought)思考过程从来没有公开披露过, DeepSeek 怎样才能学会它呢?
此外,很多 LLM 确实在 ChatGPT(以及其它 LLM)在生成的合成数据上进行练习,并且在任何新的因特网上抓取的数据自然也会包括 AI 生成的文本。
总体而言,对于 DeepSeek 由于蒸馏,模型表现出色,仅仅是因为它。 ChatGPT 这种观点,的确忽略了 DeepSeek 这些都是项目、效率和架构创新的实际结果, DeepSeek 技术报告包含详细说明。
中国在这里,我们应该担心 AI 领域领先水平吗?
也许有一点吧?
说实话,在过去的两个月里,中美在 AI 该领域的竞争趋势没有太大变化。相反,外部反应相当激烈。中国在 AI 这个领域一直很有竞争力, DeepSeek 中国的出现不容忽视。
对于开源,一般的观点是:既然中国 AI 相对落后,美国不应该公开分享技术,以免他们奋起直追。
但显然,中国已经赶上了,事实上,他们已经做了很长时间,甚至在开源领域处于领先地位。因此,关闭我们的技术是否真的能带来显著的优势还不清楚。
值得注意的是,像 OpenAI、Anthropic 和 Google DeepMind 这种企业,其模型的确比其模型更好。 DeepSeek R1 更强大。比如,OpenAI 的 o3 在基准测试中,模型的表现非常出色,而且他们很可能已经开发出了下一代模型。此外,随着「星门计划」等待大规模投资的推进, OpenAI 即将完成的融资,美国的前沿 AI 实验室将拥有足够的计算资源来保持领先地位。
中国当然还会在那里 AI 投入大量资金进行开发。总的来说,竞争正在加剧!但是我认为,美国的通用人工智能(AGI)前沿试验室继续保持领先的前景仍然非常光明。
结论
另一方面,一些人工智能从业人员(尤其是 OpenAI 员工)正试图刻意淡化 DeepSeek 另一方面,一些专家和自封权威专家对此进行了回应。 DeepSeek 反应再次显得过于夸张。需要明确的是:OpenAI、Anthropic、Meta、Google、xAI、英伟达等企业的发展尚未结束;DeepSeek 对其结果的描述(很可能)没有虚假。
但是必须承认,DeepSeek 值得得得到应有的认可,它推出的 R1 这个模型确实令人印象深刻。
这篇文章选自tanishq.ai
原文链接:https://www.tanishq.ai/blog/posts/deepseek-delusions.html
本文来自微信微信官方账号“机器之心”,作者:Tanishq Mathew Abraham,编译:机器之心,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com