
全新的视觉理解模型阿里通义千问 Qwen2.5-VL 开源







IT 世家 1 月 28 今天,阿里通义千问官方发布了一条消息,开源全新的视觉理解模型 Qwen2.5-VL —— Qwen 旗舰视觉语言模型,模型家族,推出了 3B、7B 和 72B 三大尺寸版本。
IT 世家附 Qwen2.5-VL 其主要特点如下:
视觉理解:Qwen2.5-VL 不但擅长识别常见物体,如花、鸟、鱼、虫,还能分析图像中的文字、图表、图标、图形和布局。
代理:Qwen2.5-VL 视觉是直接的 Agent,能对工具进行推理和动态使用,初步具备操作计算机和使用手机的能力。
了解长视频和捕获事件:Qwen2.5-VL 能理解超越 1 一个小时的视频,而这一次,它有了通过精确定位相关视频短片来捕捉事件的新能力。
视觉定位:Qwen2.5-VL 可通过生成 bounding boxes 或是 points 对图像中的物体进行精确定位,并能为坐标和特性提供稳定的定位。 JSON 导出。
结构化导出:对发票、表格、表格等数据,Qwen2.5-VL 对内容结构化导出的支持,有利于金融、商业等领域的应用。
根据官方的介绍,旗舰模型 Qwen2.5-VL-72B-Instruct 在一系列包括多个领域和任务在内的基准测试中,它表现出色,包括大学水平的问题、数学、文档理解、视觉问答、视频理解与视觉 Agent。Qwen2.5-VL 它具有分析文档和图表的优点,并能被视为视觉。 Agent 来操作,而且不需要微调特定的任务。
另外,在较小的模型方面,Qwen2.5-VL-7B-Instruct 超越了多项任务 GPT-4o-mini,而 Qwen2.5-VL-3B 作为端侧 AI 的潜力股,超过之前的版本 Qwen2-VL 的 7B 模型。
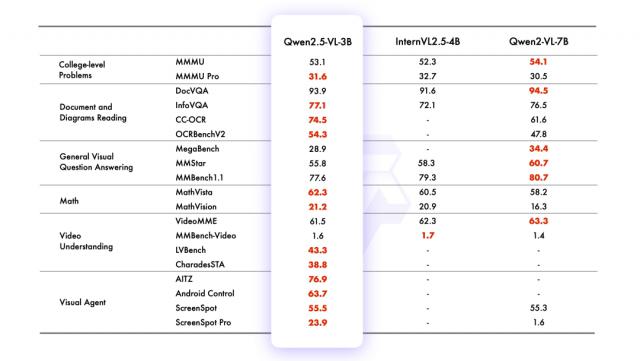
阿里通义千问官方表示, Qwen2-VL 与Qwen2相比.5-VL 提高模型对时间和空间尺度的感知能力,并进一步网络架构的简化提高模型效率。后续将进一步提高解决和推理模型问题的能力,同时整合更多模式,使模型更加智能化,并向能够处理各种输入类型和任务的综合全能模型迈进。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com