
在硅谷教OpenAI做事的中国AI双子星?








国内大模型圈迎来神仙打架,OpenAI一觉醒来就惊呼变天?
一月二十日,DeepSeek发布了DeepSeek-R1模型,没有任何征兆。不到两个小时,Kimi k1.新模型随后发布。除了模型之外,还附加了详细的技术培训报告。
两个推理模型,全面对标OpenAI o1,在多项基准测试中取得了打平和超越o1的好成绩。DeepSeek-R1文本推理模型出厂即开源,可商用,Kimi k1.5同时支持文本和视觉推理,同样各项指标打满,成为实现o1完整版本水平的第一个多模态模型。
中国大模型界的“双子星”一夜之间卷入海外,震撼了硅谷的“十亿点”。社交平台X分享了许多行业和学术领袖的结局,并称赞DeepSeek-R1和Kimi。 k1.5的帖子。
Jim英伟达AI科学家 Fan首次发帖总结了两者的相似之处和差异,并对发表的论文进行了“重磅”评价。

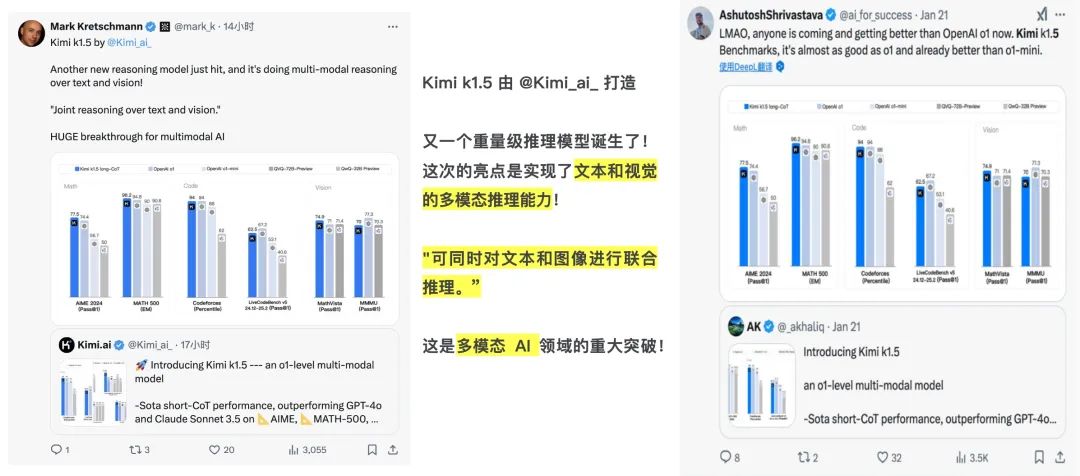
许多AI技术大V对Kimimi k1.5给予肯定,有人评论说“另一个重量级模型诞生了,亮点是文本和视觉的多模式推理能力,这是多模式AI领域的重大进步”。有人把它和OpenAI联系起来。 与OpenAI相比,OpenAI是否已被拉下神坛,“越来越多的模型正在击败OpenAI。 o1”?
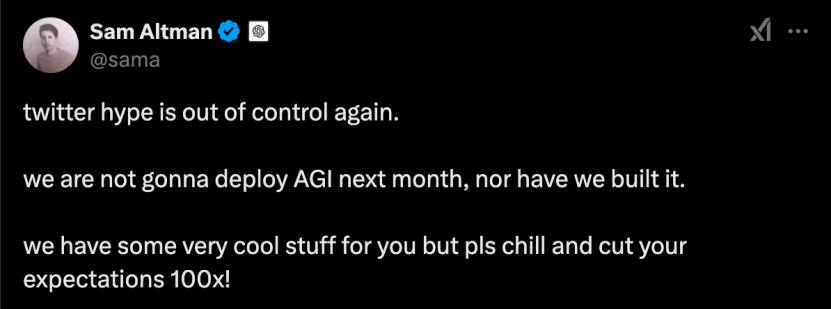
OpenAICEOSamSam面对来自中国的“攻击者”,挤压牙膏释放期货 Altman在个人账号上发帖抱怨媒体炒作AGI,让网友们降低期望,“AGI下个月不会部署,AGI也不会构建”。没想到,反而惹怒了网友,被讽刺为“贼叫捉贼”。
AI世界正在发生一些变化,DeepSeek-R1和Kimi k1.5对强化学习进行了验证(RL)思想的可行性,开始挑战OpenAI的绝对领先水平。
与此同时,中国本土模型不太可能挑战,这也是对国内大型模型产业的精神鼓励。未来,中国AI公司仍有机会打破硅谷的技术垄断,走出中国的自主技术路线。
真正的满血o1来了
继去年11月发布的k0-math数学模型和12月发布的k1视觉思维模型之后,Kimi带来了K系列强化学习模型Kimi。 k1.5。

遵循Kimi k系列思维模型路线图,k0到kn进化是模式和领域的全面扩展。k0属于文本状态,专注于数学领域;k1增强了视觉状态,成为OpenAI以外的第一个多模态o1,其领域已经扩展到物理化学;这次升级的k1.5仍然是多模态,这也是Kimi模型的显著特征之一。在该领域,它已经从数学、物理和化学升级为更常见和更广泛的领域,如代码和通用性。
根据基准测试结果,k1.5SOTA完成了多模态思维模式。(state-of-the-art)多模态推理和一般推理等级的能力。
国内外有很多模型已经达到了o1水平,但是从数据来看,只有Kimi和DeepSeek发布模型才是真正的满血版o1,其他发布模型仍然处于o1-Preview水平-差距为30%-40%。
使用OpenAI 以O1为依据,其数学水平得分为74.4分,编程水平得分为67.2分,并支持多模态。按照这个标准,我们可以看看国内已经发布的推理模型,阿里QVQ。、智谱GML、与实际o1水平相比,科大讯飞星火和阶跃星辰Step系列模型仍有一定距离。在数学水平上,DeepSeek和Kimi模型都超过了OpenAI,编程水平接近o1水平。但是相对于DeepSeek,Kimi支持多模态视觉推理,而DeepSeek只能识别文本,不支持图片识别。
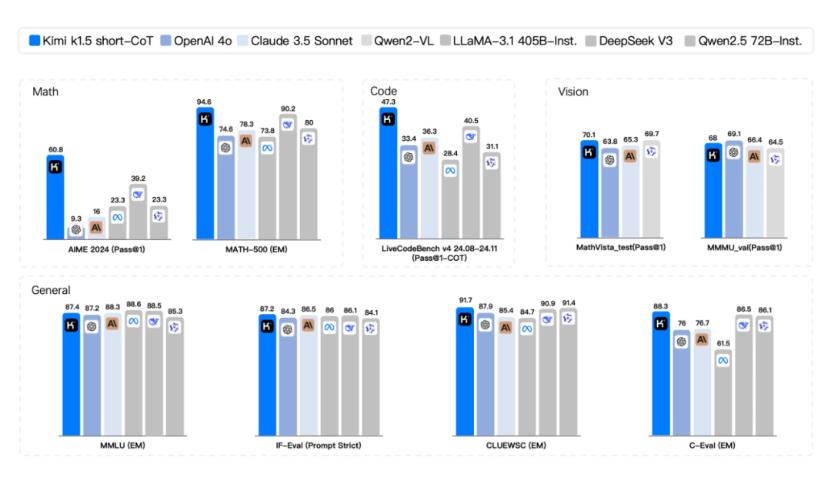
具体来说,在short中-CoT(短期思考)模式,Kimi k1.5超越所有其他模型。它的数学、代码、视觉多模式和通用能力大大超越了SOTA模型在全球范围内的短期思维 GPT-4o和Claude 3.5 Sonnet的水平领先550%。
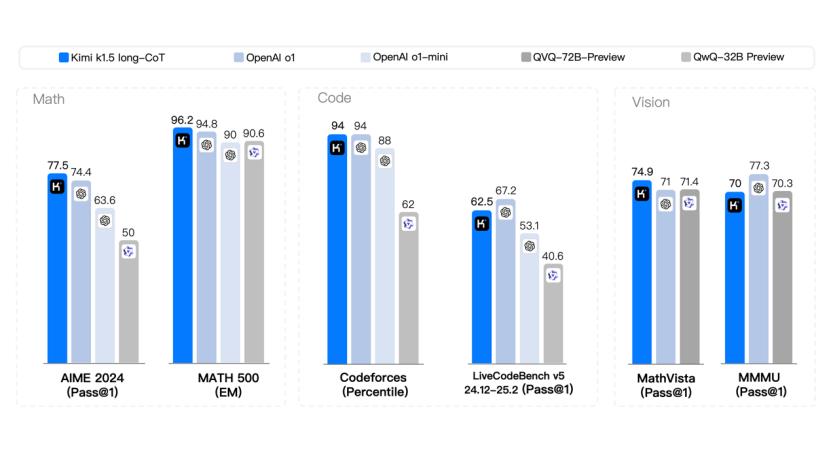
在long-CoT(长期思考)模式,Kimi k1.5具有数学、代码、多模态推理能力,还能实现长思维。 SOTA 模型 OpenAI o1 官方版本的水平。参加两次数学水平考试(AIME 在编程水平测试中,2024和MATH-500击败了o1。(Codeforces)中间和o1打平。除了OpenAI之外,这可能是全球企业首次实现o1正式版本的多模态推理性能。
Kimi k1.5的修炼秘籍
国内外共同打电话,实力水平经得起考验,Kimi是怎样培养成“超脑”的?
看了满是干货的技术报告,可以总结为一个训练思路、一个训练计划和一个训练框架。其中,高效推理和提升思路贯穿其中。
由于信息量的限制,预训练“大力出奇迹”的方法在实际训练中屡屡碰壁,从OpenAI o1从行业开始转变训练范式,把更多的精力投入到强化学习中。
以前的想法可以理解为“直接给予”,即人类应该主动“给予”大模型数据,监督大模型的工作,介入大模型的“调试”过程。但是,加强学习的关键思路是让大模型在没有太多干扰的情况下自我学习和进化。
Kimi的新模型更新使用了加强学习的方法。在训练过程中,确认模型可以获得良好的性能,而无需依靠蒙特卡洛树搜索、价值函数和过程奖励模型。
现在加强学习的思路集中体是“Long2”Short“在训练计划中,这也是Kimi技术报告的亮点。根据其官方介绍,具体方法是先使用更大的前后窗口,让模型学习长链思维,然后将“长模型”的推理经验转移到“短模型”,两者合并,最后加强对“短模型”的学习和微调。
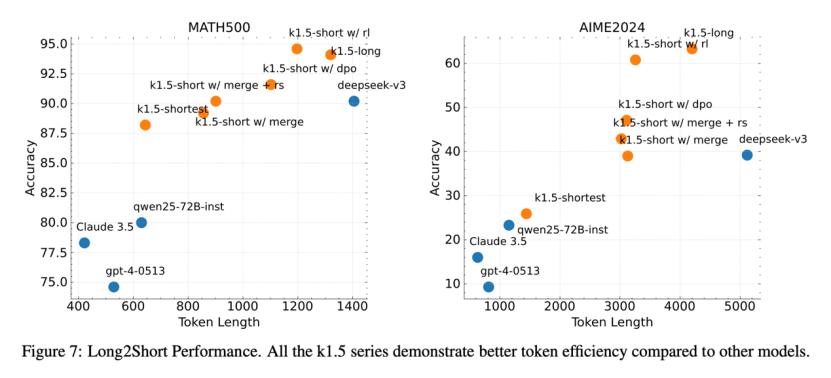
图片注:越靠近左上方越好。
这一行为的优点是可以提高token的利用率和训练效率,在模型性能和效率之间找到最佳解决方案。
在行业内,Kimi的“Long2”Short“训练计划也是“模型蒸馏”的体现。这里,“长模型”是教师,而“短模型”是儿童,教师教给学生知识,用大模型来提高小模型的性能。当然,Kimi也采用了一些提高效率的方法,比如利用“长模型”生成的多个样本,将最短的正面解释为正面样本,长时间生成负面样本,从而形成对照组训练数据集。
为适应强化学习训练,Kimi k1.为了支持整个训练系统,专门设计了一个特殊的强化学习框架。
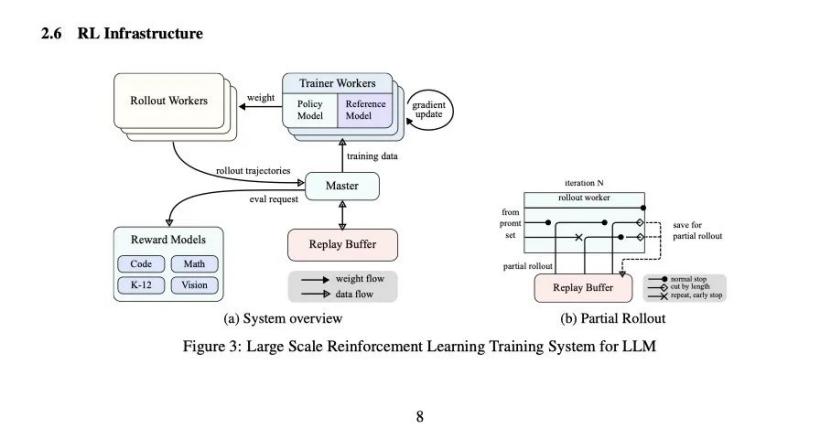
k1.5模型支持128k的上下文本长度。如果模型每次都要完成一个完整的思维链生成和推理过程,就会影响计算资源、内存存储和训练的稳定性。因此,Kimi引入了“Partial Rollouts“技术,产生的链接切割分为多个步骤,而非毕功和一战。
底层AI infra的构建思路反映了月亮黑暗面在长文本中的积累。如何最大化和高效地实现资源是它一直关注的问题。现在,这种思维将继续生成和推理思维链。
OpenAI神话在中国“双子星”结束?
从Kimi和DeepSeek中,我们可能可以看到未来模型训练的几个趋势:加强学习训练的投入和资源倾斜会增加;OpenAI o1已经成为下一阶段进入大模型的新门槛,技术和资源跟不上意味着落后;上下长文本技术非常重要,这将是生成和推理长思维链的基础;Scaling law还没有完全失效,有些地方,比如长前后文本,还是有潜力的。
在此之前,OpenAI定义了大模型训练的四个阶段:预训练、监管微调、奖励建模、强化学习。现在,这一范式已经被打破,Kimi 和DeepSeek一样,为了提高模型训练的效率和性能,可以跳过和简化一些阶段。

Kimi和DeepSeek效应是双重的。走向世界,向海外AI圈,特别是硅谷证实,中国仍然有能力竞争科技第一梯队,如果你继续致力于聚焦,你就能创造奇迹。
OpenAI应该反思一下,为什么中国企业在投入这样的资源和高人才密度的情况下,会在很多方面赶超,这可能会给世界的竞争格局带来微妙的变化。我们不禁要问,OpenAI的先发优势还能持续多久?不仅同一个国家有敌人Anthropic,Topic也从它手里拿走了 B的清单,现在也要警惕来自中国的AI公司。
在中国,新的模式似乎正在发生变化。DeepSeek以其开源和超越OpenAI的性能模型引起了前所未有的关注,甚至有人开始将其纳入“AI 在六小虎的行列中。
与以前相比,目前的Kimi对从k0到kn的技术路线更加清晰,尽管Kimi表示“将重点放在Kimi的产品上”,但是Kimi所承载的技术路线已经远远超过了一个普通的AI应用程序。
Kimi k1.5让月亮的暗面赢得下一阶段的门票,这也让它在未来的竞争中拥有更多的主导地位。在保持一定的领先地位后,2025年的新目标是如何更好地生活。
新一轮洗牌悄然开始,谁会先掉队,谁能先突出重围?
本文来自微信公众号“guangzi0088”(ID:TMTweb),作者:郝鑫 编辑:王潘,36氪经授权发布,吴先之。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com