
数百万的真机数据只有九根牛一毛,数据匮乏已经成为智能行业的困境。







·目前,全身智能领域正处于从GPT-1到GPT-2的过渡阶段,甚至最基本的物理世界数据仍然非常匮乏。远程操作获取的数据成本太高,采集效率低,行业内难以获取。除了缺乏高质量的数据,徐良威认为全身智能数据服务行业面临的首要问题是缺乏统一的数据集定义标准。
在过去的一年里,智能和人形机器人引起了越来越多的关注,但在喧嚣之后,这个行业的发展也面临着巨大的挑战,其中培养智能模型所需的高质量数据成为当前行业的共同烦恼。
日前,上海机器人创业公司智源机器人正式开源百万真机数据AgiBot World再次提到了数据缺乏的问题。智源机器人创始人、首席技术官彭志辉(网名“稚晖君”)表示,在智能领域,采集真机数据的成本和门槛都很高。开源希望很多科研团队基于真实数据练习智能算法,加快技术创新和产品用途。但在业内人士看来,“百万真机信息量”对于行业来说只是九根牛一毛。“只能训练一个动作的泛化,比如分拣,远远不够实现梦想状态中的智力。”
除缺乏数据外,现有数据的标准化也是一个需要解决的问题。
甚至缺乏最基本的数据。
与语言模型的练习不同,它是由于互联网上的海量数据。智能“大脑”的练习需要更多的物理世界,也就是真实世界动态环境下的交互数据。如何解决物理世界数据匮乏的问题,已经成为人形机器人技术进化中最大的问题。
银河通用的创始人和CTO是人形机器人创业企业之一。、北京大学助理教授王鹤曾多次提到智能领域数据短缺的问题。王鹤认为,通用机器人背后的技术必须是一个大模型,基本机器人的大模型应该由数据驱动,这样机器人才能具有很高的泛化性和跨行业应用能力。然而,目前信息量不足以支持通用机器人的发展。
泛化是指模型训练有素后,能够将一种行为应用到不熟悉的应用场景中的能力,能够在不熟悉的场景中独立识别任务并付诸行动。人形机器人创新中心(以下简称“国地中心”)的相关数据负责人正在接受澎湃科技(www.thepaper.cn)采访中表示,获取机器人泛化数据一直是一个大问题。目前,特斯拉的Optimus仍然需要人工远程控制来帮助机器人实现目标,但没有泛化能力。
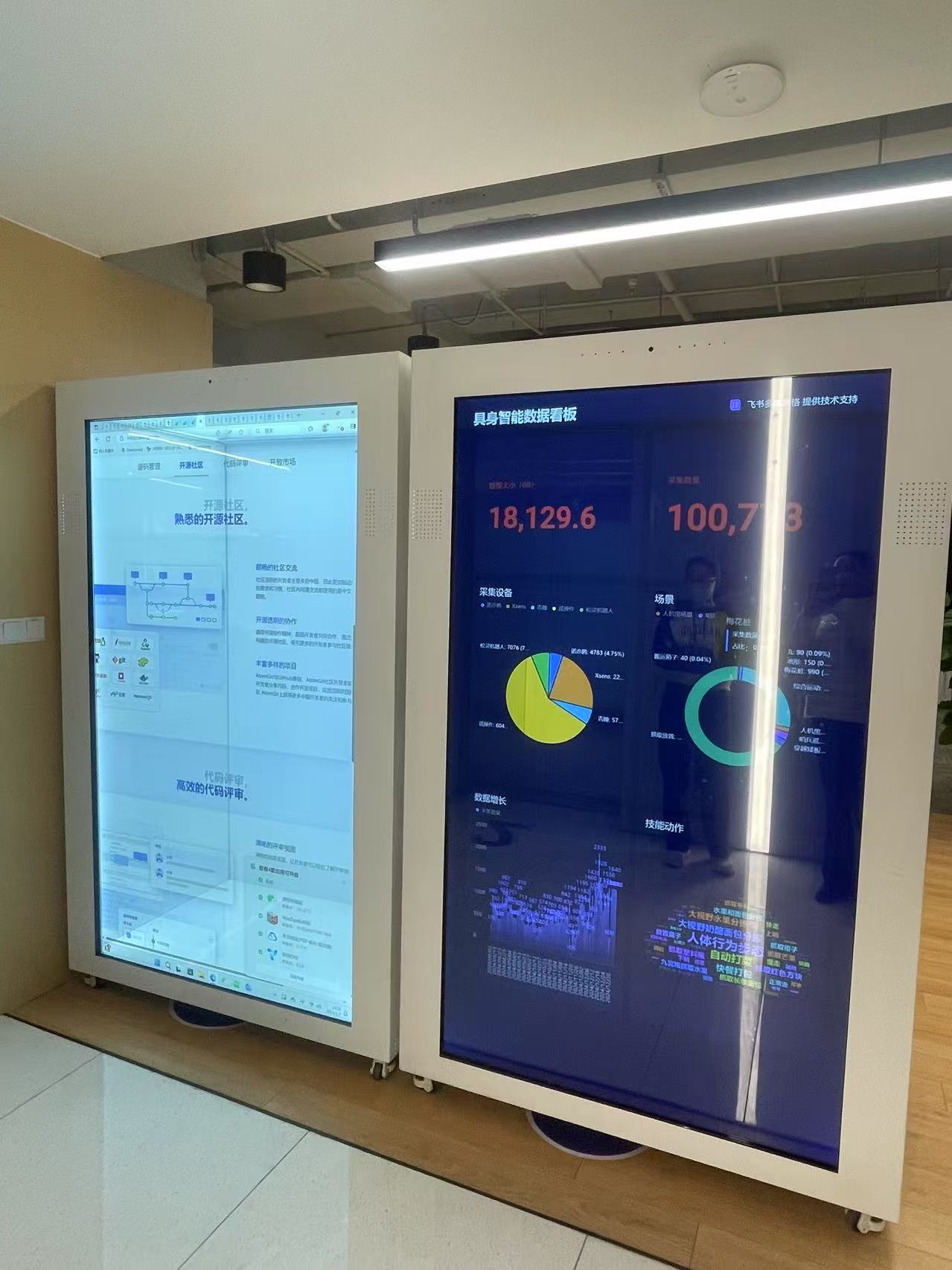
全国人形机器人创新中心具身智能数据看板,澎湃科技记者拍摄。
北京航空航天大学机器人研究所声誉优势王田苗此前在接受《ThePaper》采访时也指出,缺乏数据使人形机器人难以泛化。目前很难获得机器人任务泛化、感知泛化、运动控制三种泛化数据,比如机器人叠衣服、骑自行车等信息。
从2023年开始,王鹤团队开始探索大规模的灵巧手数据合成和大规模的泛化。2024年,10亿规模的数据合成用于训练机器人灵巧手。
艾欧智能创始人徐良威,总部位于深圳的一家创业公司,向具体服务机器人提供基本场景数据和解决方案。经过一年多对机器人技术路径的探索,发现“只有通过大量的数据训练,才能真正通向具体智能”已经成为行业共识,通过模拟数据实现智能的概率远低于使用真实数据的概率。但是,目前具体智能领域正处于从GPT-1到GPT-2的过渡阶段,甚至连最基本的物理世界数据都非常匮乏。
对徐良威而言,对训练具身的智能泛化能力而言,AgiBot 虽然World这个百万数量级的数据集取得了显著的进步,但它只是“九根牛一毛,洒水”,需要更多的数据才能达到理想的效果。
获取高质量的数据收集费用太贵了
该报科技记者了解到,在智能领域的实践中,发展了四种智能收集训练数据:第一种是遥操作机器人数据,即一个人工数据收集器需要戴上遥操作手套,手把手教,才能获得真实的机器操作数据。这样得到的数据质量最高,但是成本很高。二是模拟生成数据,训练数据从无到有地积累在虚拟的3D模拟环境中。这种训练数据主要是生成数据,与现实世界还是有很大区别的。第三种技术是通过人类动作捕捉数据,也称为动作捕捉或动作跟踪数据,是通过传感器、摄像头或其他设备准确记录和分析人体运动的技术。这种方法获得的数据质量很高,但通过人类动作捕获的数据与机器人能否适应还是有一定区别的,需要后期继续做构型对齐相关的工作。四是通过因特网获取人类动作视频或图像数据。这种方法的特点是可以获得大量的数据,但是它们都是单一的模式,非结构化的,没有注明的二维图像或者视频信息,质量很差。
国地中心数据负责人指出,目前行业内最缺乏的是通过远程操作获取的优质数据。模拟生成数据的获取成本较低,但模拟与现实世界的差距仍需消除。但是远程操作获取的数据成本太贵,采集效率低,行业内很难获取。

数据训练者穿着特殊的动作捕捉服装训练人形机器人捕捉数据
“一台遥控设备的投资在35万元左右,加上人工数据采集人的成本,每人每天收集500条左右的数据,人工成本至少需要300元,即使长期投资,也不能保证成功。”根据国地中心数据负责人的估计,特斯拉的人形机器人Optimus在特斯拉工厂完全准备工作至少需要几百万小时的数据,在此期间可能需要至少5亿美元的数据采集成本。
上述国地中心数据负责人向澎湃科技透露,即使银河通用致力于加强机器人大脑模型,强调模拟生成数据的使用,但仍面临一定的挑战。他说:“模拟环境中的参数看起来是正确的,但是在物理世界中,即使是细微的误差也会导致完全不同的结果。举例来说,人形机器人在进行蹲下起身这一动作时,不同的机器人可能会有不同的表现,电动机参数的任何微小变化都会使机器人产生完全不同的行为,难以控制。”
由于泛化数据收集成本高,难以获取,国地中心数据负责人透露,现阶段行业大部分按1:9或是1:10的数据比例训练机器人,即一个遥操作机器人的数据配有9个或10个模拟生成数据,但这个比例尚未确定。
缺少统一标准的数据集
徐良威认为,另一个关键问题是如何实现高效的数据采集。虽然高质量的数据可以通过人工操作机器人获得,但这种方法的效率极低。徐良威表示,智元表示,每周可以收集50万条数据,综合年信息量只能达到1000万,对于智能训练来说非常低效,难以加速。
除了缺乏高质量的数据,徐良威认为智能数据服务行业面临的第一个问题是缺乏统一的数据集定义标准。虽然国外有Google这样的科技巨头已经开源了一些数据,国内也有数百万的真机数据,比如智源机器人开源,但是很难说不同公司开放的数据集格式是否可以适应,数据质量是否可以保持一致。
“北京和上海的开源数据集是否可以适应,数据类型是否一致,数据托管方式有哪些差异,还有待颁布统一的数据标准。”徐良威说,目前国内很多机器人公司都处于“百花齐放”的状态,数据管理也各行其是,导致公司之间的沟通成本非常高。
在数据处理方面,目前行业内缺乏统一的数据处理标准。“不同的公司、机构或平台有不同的数据处理方法。如果机器人想有效利用这些信息,就需要进一步处理。”徐良威说,每个团队或公司都可能需要重新开始处理标记数据,这将浪费大量的时间和资源,不能保证培训结果的实用性。
近日,“人工智能智能数据采集标准”工业和信息化部行业标准由全国各地智能机器人创新中心率先设立,规范了智能数据采集的格式,让不同公司采集的数据可以共享开源,加快模型的“出现”。在徐良威看来,对从业者来说无疑是一个积极的信号。
更多的数据采集训练场将在2025年出现。
世界范围的出现似乎给人形机器人带来了新的希望。去年12月,李飞飞的世界模式开启了从数字世界到物理世界的跨越之旅,实现了从一维数字智能向三维空间智能的重大转变。2025年1月6日,英伟达创始人兼首席执行官黄仁勋在2025CES(国际消费电子产品展)期间,推出了Cosmos世界基础模型平台,包括生成世界基础模型,旨在加快无人驾驶汽车、机器人等物理AI系统的发展。“机器人ChatGPT时刻即将到来,黄仁勋认为。世界基础模型和大语言模型一样,对于推动机器人和自动驾驶汽车的发展尤为重要。”
徐良威表示,这种世界模式为通用智能提供了空间、时间、物理、语义等各个方面的模型表征。理论上讲,一方面,世界模型的成功促使机器人“理解世界”的概率;另一方面,世界模型可以在各个层面生成符合世界规律的数据,并有潜力成为机器人生成数据的新范式。然而,虽然世界上已经有了一些阶段性的成果,但是真正应用于机器人,直到可以商业落地也需要进一步的发展。
在成为行业共识的同时,很多方面都在采用数据缺失的解决方案。2024年8月,特斯拉高薪招募“数据采集员”。;北京国地共创具身服务机器人创新数据收集基地于2024年12月27日亮相。
据了解,自2024年下半年以来,位于上海张江的国家和地方政府正在建设一个基于自己平台的数据采集训练场。目前训练场的场地建设和数据采集机器人设备基本到位。2025年,计划招聘一些数据采集人员配合遥控数据采集。预计2025年量产机器人数量将会增加,数据采集量将会随之大幅增加,数据采集成本也将下降。他说:“今后可能会出现一批便携式数据采集工具,这将进一步降低数据采集成本。”有关人士透露。
在徐良威看来,北京和上海相继提出创建服务机器人创新数据收集基地,构建实践和模拟应用领域。核心理念远不止是数据收集本身,更重要的是可以集中资源,缩短数据积累时间,相应缩短智能市场的准入时间。他预测,2025年,不同地区将加快数据采集训练场的建设,以便尽快实现机器人从0到1的应用,数据采集方式将更加多样化。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com