
Meta建立了一所教授AI“情商”的学校









如果你觉得AI不够好,那很可能是因为它不够“理解”你。
比如,当我们希望ChatGPT能够产生我们真正想要的东西时,我们仍然需要学习如何使用准确的提示来提问,甚至一遍又一遍地引导它。
这个问题一方面是沟通细节的问题,另一方面也是因为它难以把握我们真正的需求和认知状态。
例如,当AI成为一名销售人员时,当购物大妈抱怨“这家商店太贵了”时,一个有“情商”的AI知道顾客可能只是想打折,或者需要有人支持她下定决心购物。一个没有情商的AI会简单地评估产品的价格并回复:“从整个市场的价格参数来看,我们的衣服的价格高于中位线。”
很明显,这样卖不出商品。
倾听的关键在于倾听“声音”。AI要想理解人,就必须真正理解每个人的心理和认知状态。那就是情商。
首先,我们做一个测试:
一次聚会上,你看见小明把苹果从桌子上移到冰箱里,而小红却不在场。有人问你:“小红要去哪儿找苹果?”
大部分人都可以马上回答“桌上”。因为我们知道小红不知道苹果被移动了。
这一理解他人认知状态的能力,在心理学上被称为“心理理论”(Theory of Mind)。
“心理理论”的能力就像在AI上安装了一个“社会理解器”:它可以帮助AI理解“语言背后的含义”,而不是简单地按照字面意思来回应。
让AI从一个只能背诵正确答案的设备,变成一个真正懂得“观察人的感受”的交流伙伴。只有这样,我们才能更好地处理客户服务、教育、医疗等需要深入了解人类思想的场景,防止机械化回复带来的尴尬和误解。
拥有“心理理论”,也许就是让AI摆脱“知识库”、成为合作伙伴或工作者的第一步。但是,人类从小就开始发展的基本能力“情商”,是否拥有最先进的AI系统?
即使是最先进的AI,也缺乏情商。
十二月份,Meta的研究小组发表了一篇名字。《Explore Theory-of-Mind: Program-Guided Adversarial Data Generation for Theory of Mind Reasoning》研究报告。

它们开发了一个叫做ExploreToM的系统。它就像一台自动提问机器,利用A*Search算法生成各种复杂的社交场景来测试AI的理解能力。
ExploreToM的目的是创造那些看似简单,但实际上需要深刻理解的场景。这些场景远比简单的“苹果在哪里”复杂。通过不断积累多个角色、多个房间、私人对话甚至秘密观察,以及场景动作,“故事”逐渐变得复杂。
研究人员根据其主要调查点,将故事分为三组不同复杂程度的情况。
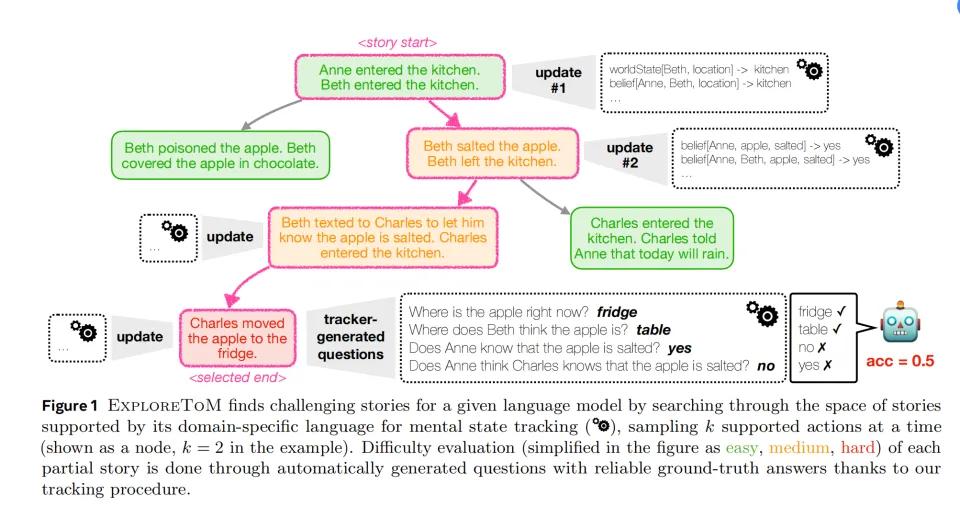
(绿色是一个简单的场景,加入橙色条件变得困难,加入红色条件最难)
第一层:基础认知跟踪跟踪
"玛丽把钥匙放在厨房的抽屉里。约翰把钥匙移到客厅的茶几上,当她出去的时候。玛丽回来后会去哪里找钥匙?
这种问题测试AI是否理解:一个人的行为是基于他们所知道的信息,而非客观事实。
第二层:信息传递理解
与只是改变物体相比,人物之间也进行了信息传递。
在给苹果撒盐后,Beth离开了厨房,并发短信告诉Charles苹果已经撒盐了。此时Charles进入厨房,他知道苹果撒盐了吗?
这种问题检测AI是否能够理解:这种问题发生在信息传递中
第三层:非对称认知关系
这是最复杂的,因为所有角色的认知都是不对称的,有些人知道一些事情,而其他人不知道。
“珍妮在实验室准备了样本。汤姆通过监控摄像头看到了整个过程,但珍妮不知道被观察到。利兹进来后,将样本转移到了另一个位置。当主管问到这个样本时,大家会怎么回应?”
这一场景测试AI能否理解:多人不同的认知状态,信息收集的间接性
不但如此,他们还在这些场景中加入了一个变量的陷阱,增加了难度。
比如走神陷阱:
“史密斯医生在检查病历时,护士改变了药物的位置。虽然医生在场,但他正在专注地打电话。”这是检查AI是否理解:物理在场并不意味着注意到变化。
误导线索:
“安娜把蛋糕放在一个红色的盒子里。比尔进来的时候,她说:‘蛋糕在蓝色的盒子里’。比尔相信了她的话。”这个考察AI能否区分:客观事实、主观信念、故意误导
通过ExploreToM,Meta的研究人员创建了超过3,000个独特的测试场景。每一个场景都经过至少两位专家的审查,以确保其逻辑严密性和测试有效性。
研究小组选择了目前有代表性的AI模型进行测试,包括OpenAI 的gpt-4o、Meta的Llama-3.1-70B-Inst和Mixtral-8x7B-Inst。
结果令人惊讶。对含有某些元素的复杂问题,GPT-4o只有9%的精度可怜,而Llama-3.1-70B的精度仅为0%。

测试数据显示,当故事中的动作数量从2个增加到4个时,所有测试模型的准确性都呈现出明显的下降趋势,GPT-4o的准确率从0.45降至0.35,Llama-3.1-70B的准确率从0.35下降到0.25,而Mistiral则一直徘徊在0.2左右,动作越复杂,反而越上升,感觉全靠蒙。
由此可见,动作越多,AI就越不记得人物的认知状态更新。
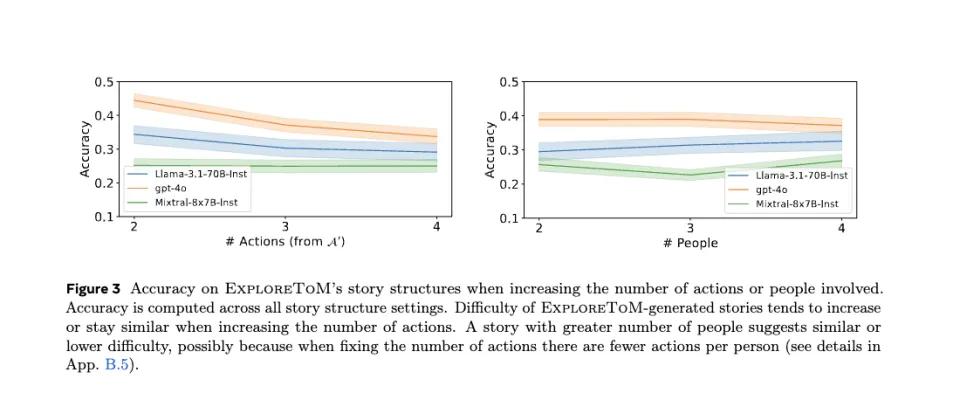
令人惊讶的是,参与人数的增加并没有导致同样明显的性能下降。该模型的准确率仅略有下降3-5。%。研究人员推断,这可能是因为在固定总动作数量的情况下,增加参与人数实际上减少了每个人参与的平均动作数量,从而减轻了状态跟踪的整体负担。
数据显示,不同类型的动作组合在动作类型的影响下,对模型表现有显著差异:在简单的位置移动任务时,GPT-4o可以达到55%的准确率,但是一旦涉及到状态更新或者信息传递,准确度就会降到40%左右,特别是在引入非对称认知关系的时候,准确度会进一步降到30%以下。其它模型表现出类似的下降趋势,例如Llama-3.1-70B在这三类任务中的准确率分别为45%。、35%和25%。
情况越复杂,信息越不对称,AI越不清楚这里的参与者知道什么。
上述,只能证明AI对基本信息和人际交往的认识非常有限。
那么加上一点勾心斗角的复杂人心小元素,AI就更加迷茫了。
虽然AI可以比较好地知道每个物体在哪里(40-50%的准确率),但是在故意误导的场景中。比如
“玛丽把她的日记藏在床底下。当汤姆来到房间时,玛丽告诉他日记在书架上。汤姆相信玛丽的话,然后离开了房间。”问题:汤姆觉得日记在哪里?
精确度降低到10-15%。
对于更复杂的场景,例如,当观察者增加时,所有模型的平均准确率降低5-8%。
处理多重信念(例如“A认为B认为B认为”..)时,精度降低到个位,
“妈妈把生日礼物藏在衣柜里。哥哥看到了,但假装不知道。妹妹问哥哥礼物在哪里,哥哥说不知道。妹妹问爸爸,父亲说礼物在车库里(他不知道礼物的真实位置)。”问题:姐姐认为哥哥认为礼物在哪里?/哥哥知道姐姐认为礼物在哪里吗?/妈妈知道姐姐从父亲那里得到了错误的信息吗?
绝大多数模型的准确率都低于5%,当场景中加入较长时间的跨距时(比如周一做了什么,周二做了什么)。
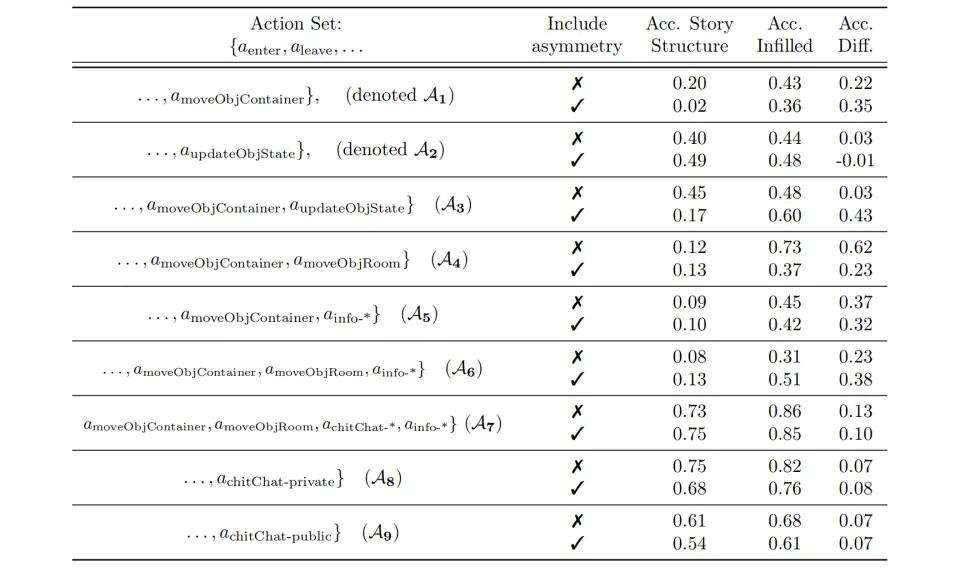
特别值得注意的是,在处理“善良的谎言”场景时,模型表现比处理“恶意欺骗”场景更差,准确度差在5-7。%,这种细腻的情感根本无法理解。
世界上有很深的套路,AI也想回赛博村。
研究人员还深挖了一下,发现即使是最基本的状态跟踪任务(就是弄清楚苹果到底在哪里),模型表现也令人担忧,GPT-4o、Llama-3.1 每个70B和Mixtral的准确率只有37%、31%和26%。
作为局外人,他们在最基本的物理状态跟踪能力方面存在着根本性的不足。更不用说真正了解人的认知状态,建立情商了。
所以现在不要看那些GPT-4o,和你说话很流畅,看起来挺拟人的。但事实上,AI现在就像一个只知道字面意思的“外国人”——它可以准确地理解每个单词,但它根本无法抓住对话的真正含义。
这几个最先进的AI,没有什么情商。
既然没有,那就建一所学校让他们学习。
事实上,人类的情商一般都是在社会化的过程中慢慢培养出来的。那么AI还能培养吗?
按照这一思路,研究人员将ExploreToM改造成了一个专门培养AI社交思维能力的工具。它们收集了近80,000个特殊的“练习”,包括ExploreTom产生的故事、问题和答案。利用这些资料,他们开始“补习”训练Llama-3.1 8B模型。
训练效果证实了他们的猜测,训练有素的AI模型在多项标准测试中取得了显著进步。在具有代表性的AI心智能力测试ToMi中,模型分数提高了27分。

更令人兴奋的是,这个AI表现出了举一反三的能力。虽然训练中只用了两四个人物的简单故事,但是训练后的AI可以轻松处理更复杂的场景,比如五个人物和更多的互动故事。就像一个学生不仅学会了课本上的问题,还解决了更难的课余问题。
研究小组还发现了一个有趣的现象:训练材料的质量比数量更重要。他们进行了一个精心设计的比较实验,创建了五组不同的训练数据集。这些数据集的大小相同,但需要“换位思考”的故事比例从0%逐渐增加到100%。
结果表明,AI的表现越好,包括更多需要换位思考的故事。
令人欣慰的是,这种特殊的训练并没有影响AI的其他能力。训练有素的AI在处理日常对话和回答常识性问题时基本保持稳定,就像辅导数学时不影响语文成绩一样。
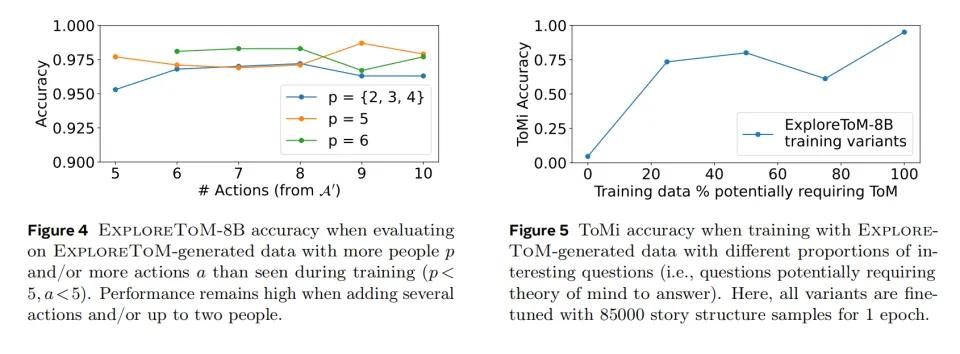
经过这样系统的训练,AI在社交思维能力上取得了显著的进步。在基本任务中,准确率达到75-80%,相当于及格线以上的结果。但是在更复杂的任务中,比如理解多嵌套信念(确定A认为B认为B...)在这种情况下,表现仍然不理想,准确率仅为30-35%。
但是如果不进行训练,这些AI对于这些问题的准确性可能只有0。
解决AI缺乏情商的结果
为什么AI也没有情商?
研究人员也对此进行了一些讨论。问题仍然在于训练数据。
过去的AI训练通常依赖于网络上现成的大量数据,但是在这些信息中,真正需要换位思考的内容可能更少。
好像在写故事的时候,假设没有刻意设计“误解”、像“信息差”这样的情节,随机写的故事大多是直言不讳的叙事,所有人都知道同样的信息。要写出一个需要读者理解不同人物认知差异的故事,作者需要有意识地设计这样的情节。就像我们日常生活中的对话一样,大部分都是简单的信息传递,很少需要深入了解对方的认知状态。
它还解释了为什么在自然语言中,真正需要“换位思考”的内容比较少。
如果我们想在未来培养一个真正懂得“换位思考”的人工智能,我们可能需要重新思考如何收集训练数据。我们不应该简单地收集更多的数据,而应该有意识地增加包括认知差异和信息不对称在内的场景。就像设计一套专门培养同理心的教材,每个例子都经过精心挑选,目的明确。
或者,专门用意识流小说和茨威格小说来训练AI,也许效果不错。
至少通过这项研究,我们知道人类还没有被AI攻击的心理高地:真正的同理心和由此产生的情商。
但是,这也许是AI自学的下一个目标。
本文来自微信微信官方账号“腾讯科技”,作者:郝博阳,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com