
全网热评的李飞飞世界生成模型,真的可以构建物理世界吗?





还记得《爱丽丝梦游仙境》开头那个神奇的兔子洞吗?现在你不必追着白兔跳进去,只需点击鼠标即可。
李飞飞空间智能Worldd在北京时间12月3日凌晨 第一个重磅成果是Labs的第一个项目:世界生成。

世界生成是一种可以通过单个图像生成的图像。 3D 人工智能系统在物理世界,World Labs官方帐户连续发送9条X(原Twitter),更新项目的最新进展:
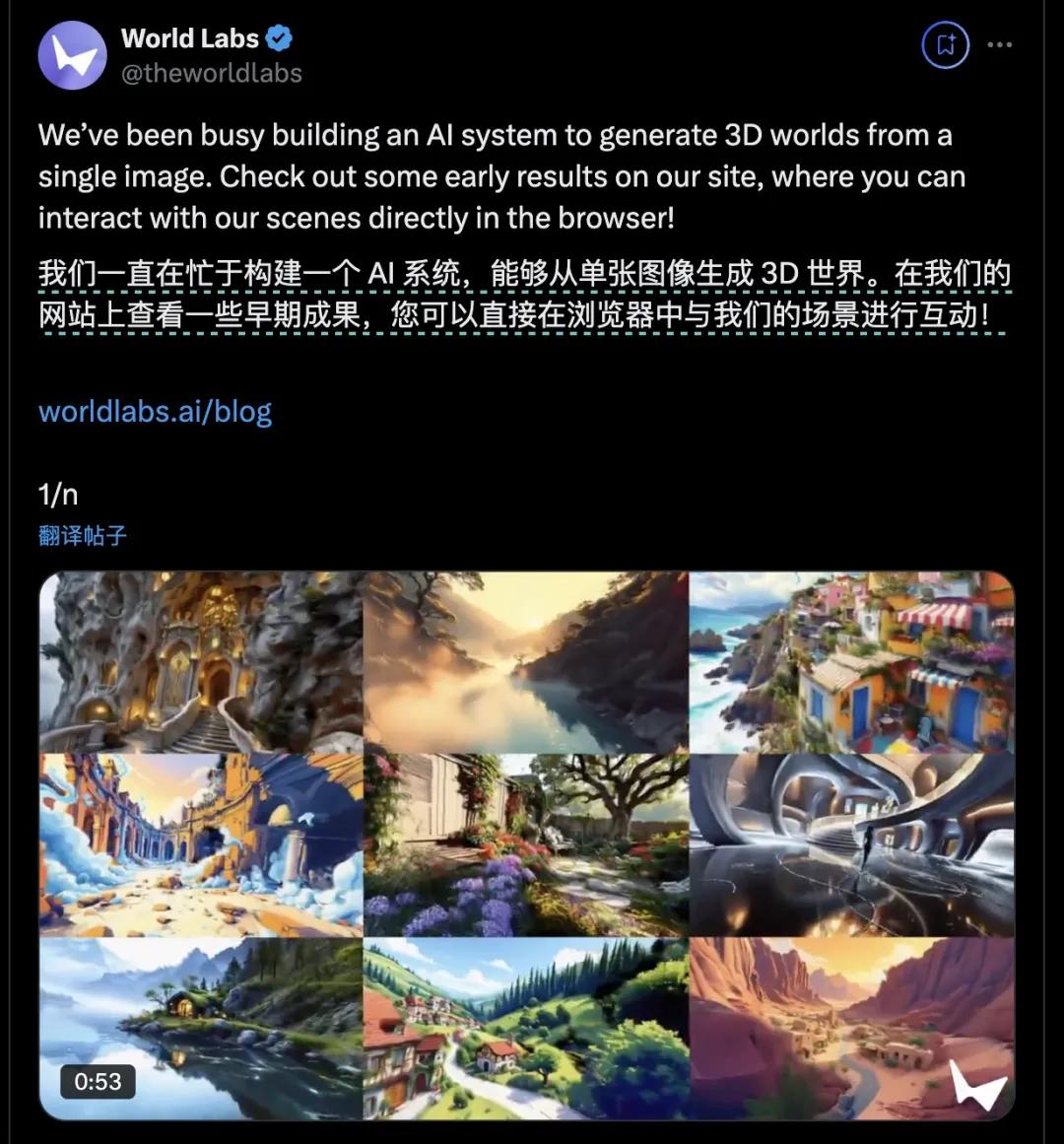
这个更新引起了AI界的热议。李飞飞高徒Jim英伟达高级研究科学家 Fan在X上说,这是一种跨时代的商品,可以与Sora相媲美。他说“GenAI 关于人类感受的快照正在产生越来越多的高维度。Stable Diffusion是一张二维快照。Sora 这是一张二维加时间快照。如今,World Labs 这是一张三维、完全沉浸式的快照。”

Saraha16z的合伙人 “Wang还说,”AI 产生的连贯 3D 世界已通过 @theworldlabs 问世。”
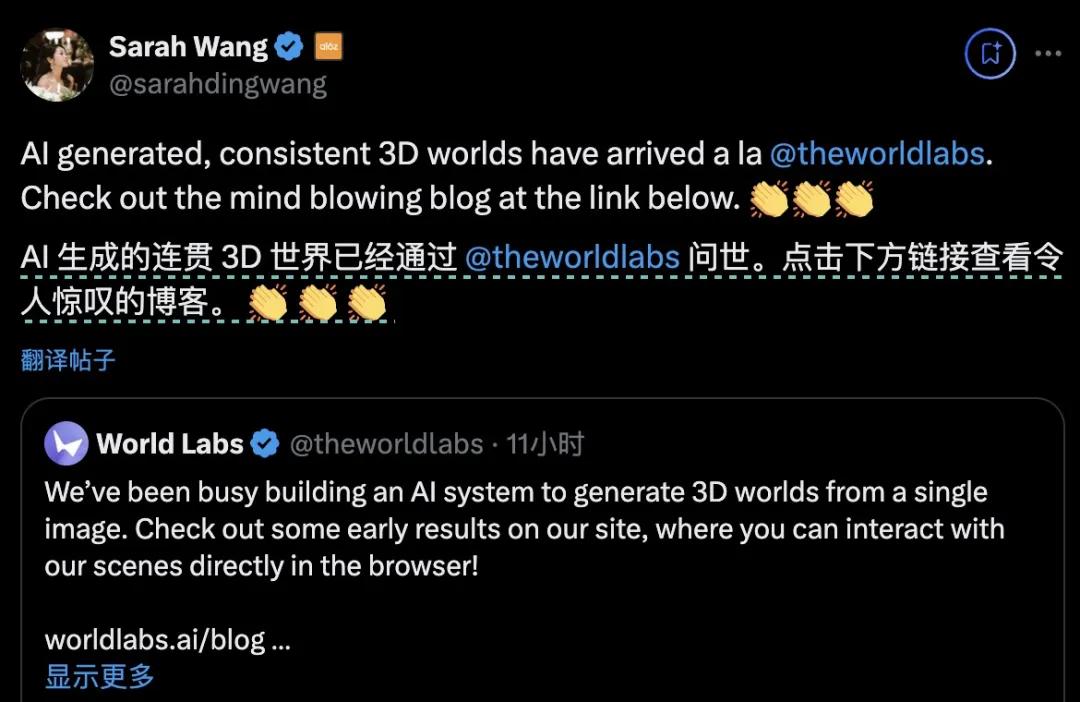
来自Google Ben科学家Brain Poole试图拆解其背后的原理,这项技术的创造得益于谷歌的CAT3D项目。但是这个项目没有李飞飞那么受欢迎。
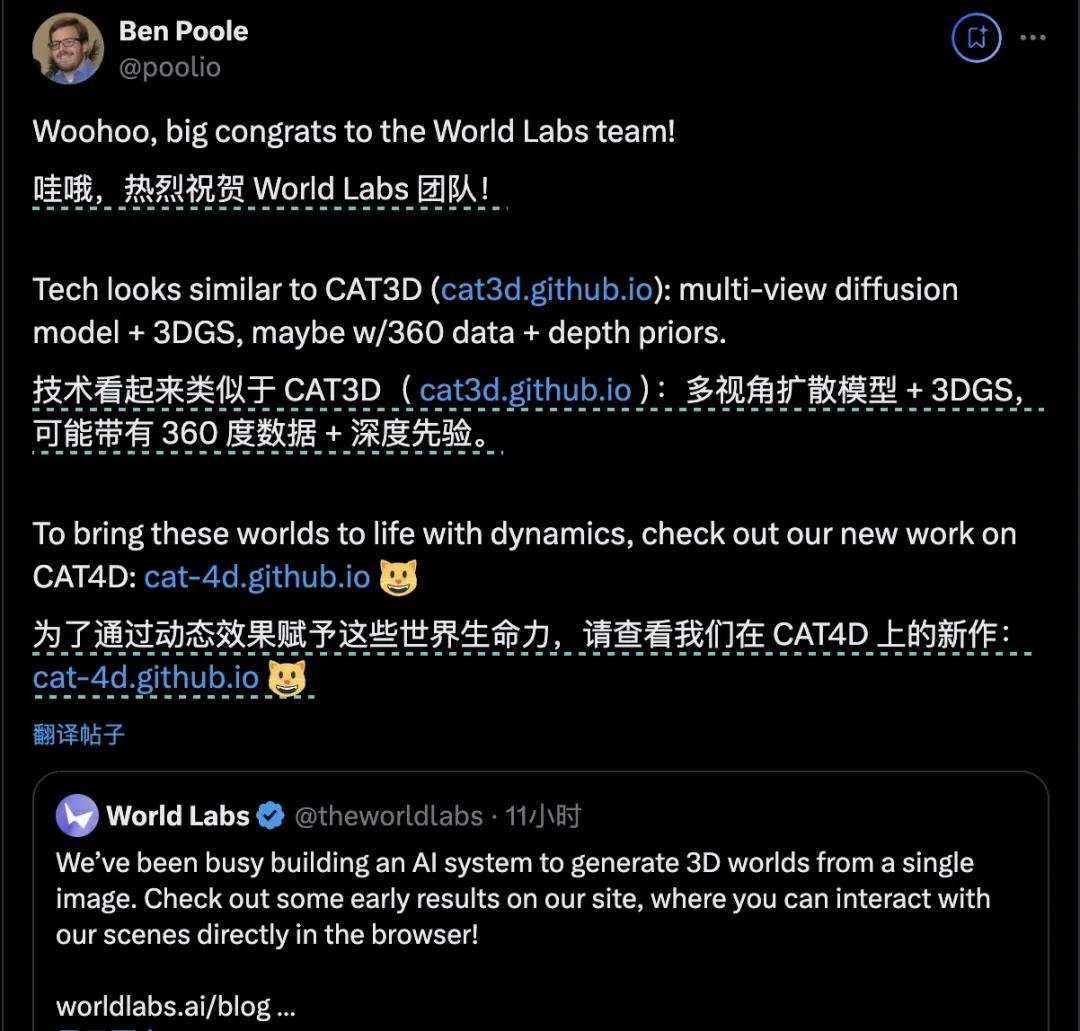
但是Haoruu在卡内基梅隆大学机器人研究所工作 Xue展望了该产品的潜在应用:在具体智能中构建无限现实世界。
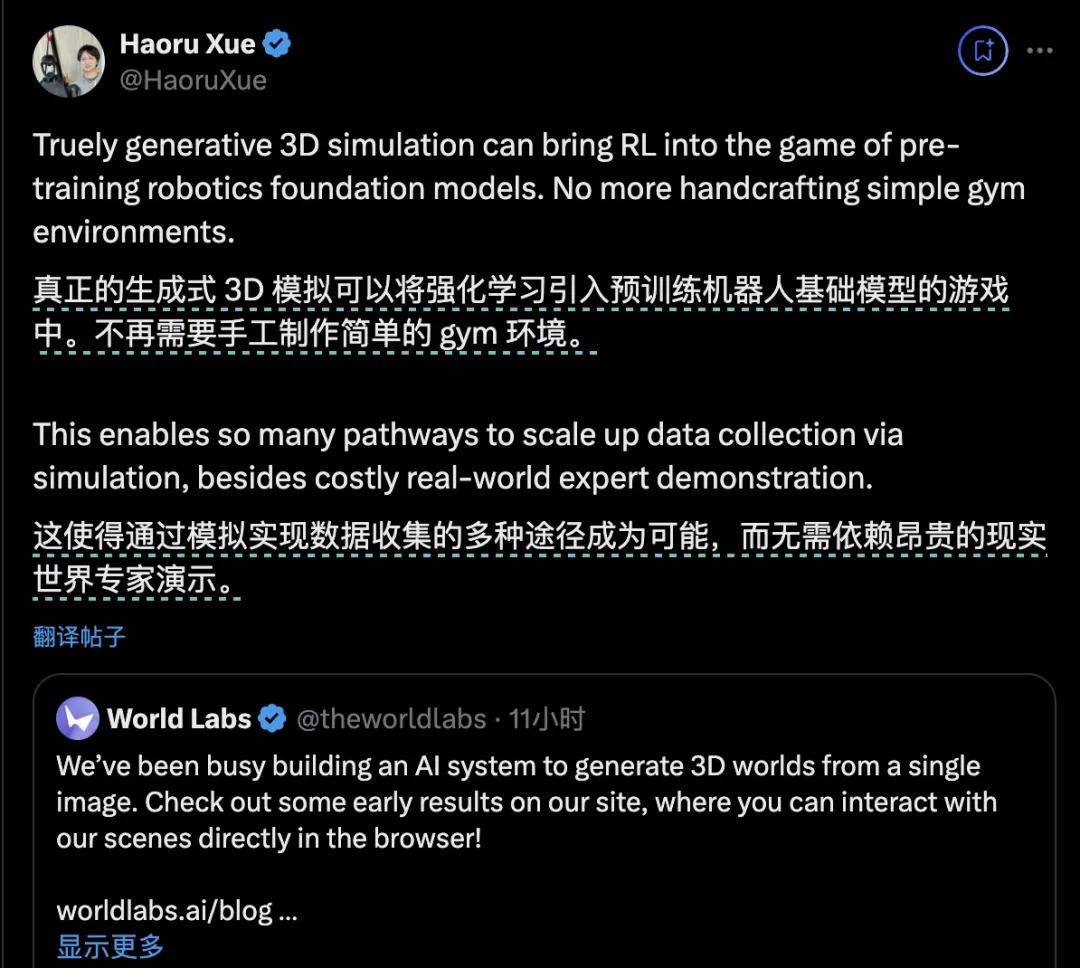
看到这么多评论,World Labs真的可以跨越世代吗?就其效果而言,的确可以。
从任何平凡的照片中,都可以生成一个3D世界,可以进去闲逛。这听起来像是科幻作家的幻想,但从今天开始,依靠World。 Labs的发明,这已经成为触手可及的现实。
1 世界上生成的模型,有什么不同?
在此之前,我们还看到了各种AI生成产品,生成3D可交互场景,包括《我的世界》,可以即时交互。Oasis。
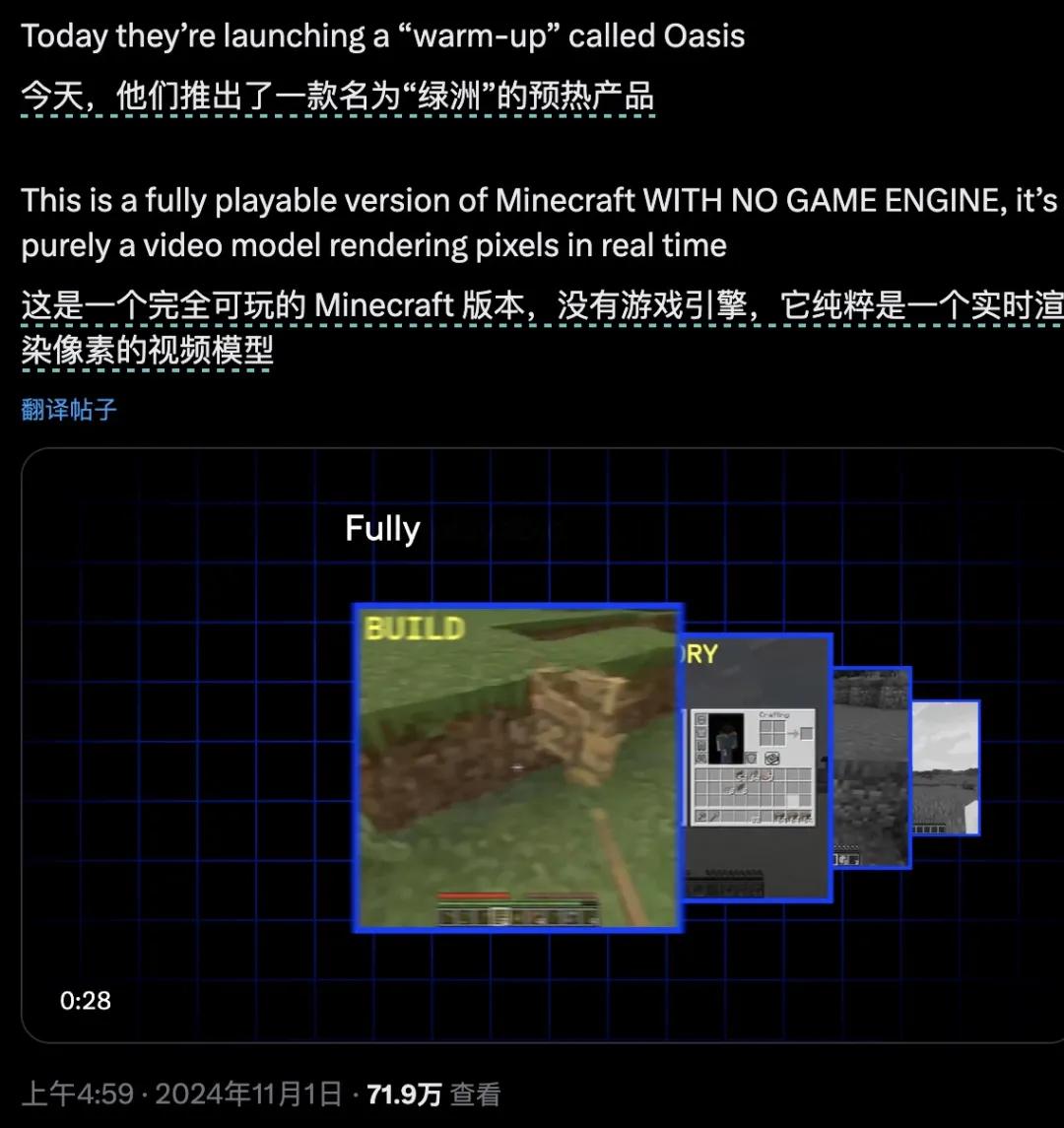
但是World Labs技术的核心突破在于直接生成三维场景,而不是停留在传统像素上。当一个场景被生成时,它就像现实世界一样稳定——你可以自由移动,近距离观察一朵花的细节,或者绕过角落看隐藏的风景。然而,像素生成很难克服随机性问题。

此外,世界还遵循基本的物理规则,具有真正的深度感和空间感。
World Labs也可以进行许多场景控制。举例来说,在镜头上,你可以调整虚拟相机的景深,做出著名的希区柯克变焦。

在这个世界上,甚至可以设置多个虚拟镜头来调整镜头的运动。
效果方面,你也可以给场景增加动画效果,让叶子随风摇曳,让水面波纹。这表明World Labs可以很好地识别3D物体的边缘和实体,而不仅仅是恢复景深。


更加令人惊讶的是,该系统不仅可以处理普通照片,还可以处理艺术作品。
想象一下:你可以溜进梵高的《夜晚露天咖啡馆》,在那些标志性的黄光下喝一杯咖啡;或者在爱德华·霍普的《夜游》中,从另一个角度看那些永恒的夜归。这大概是最接近“穿越名画”的体验了——虽然你还是喝不到那杯咖啡。
获得测试资格的创作者,已开始迫不及待地开始魔改这一技术,并将其纳入视频生成的工作流程。您可以先用文字生成图片,然后将其转换为3D场景,然后在其中自由设计镜头运动。一些创作者已经开始了这种新的工作方式——他们将World Runway和AI工具等Labs技术与现有AI工具相结合, mod,这部电影的效果相当惊人。
2 解码世界生成背后的技术
虽然World 虽然Labs还没有完全公布其背后的技术论文,但是根据一些蛛丝马迹,我们仍然可以对其技术背景进行重构。
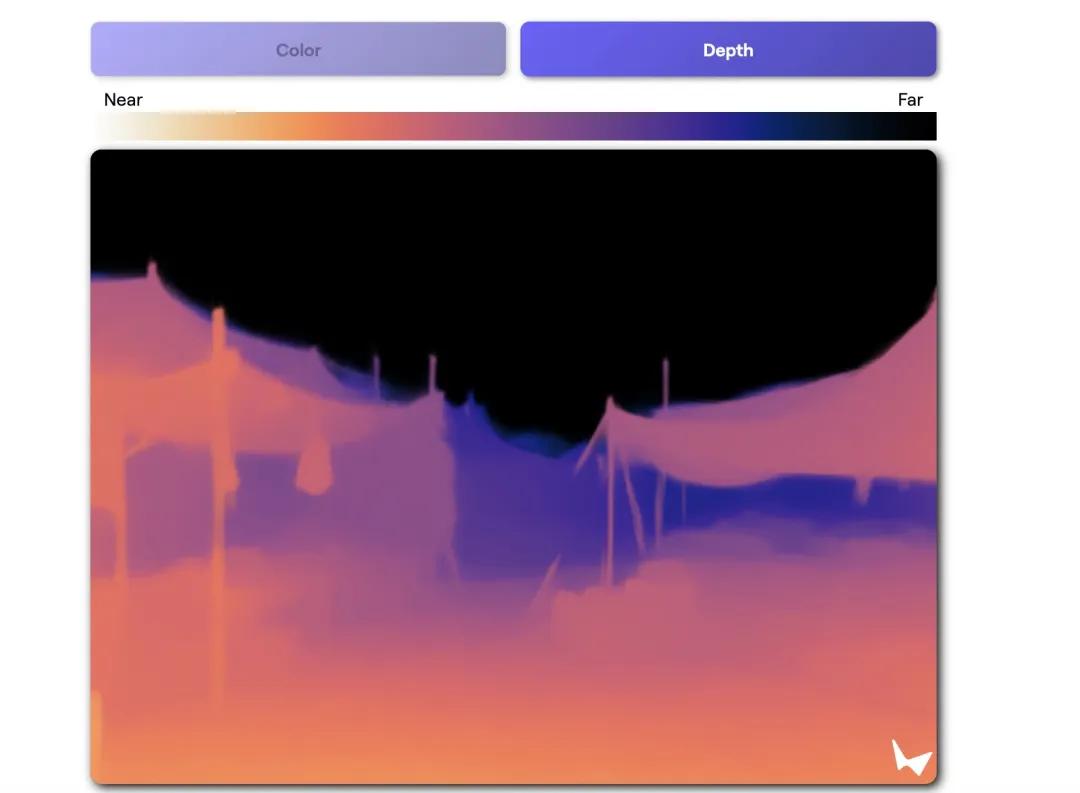
World 在Labs提供的一系列情景控制中,有一种是景深恢复。它是实现图片到3D场景重构的核心方法。
Lucid早在2023年底,首尔大学 Dreamer和Skybox AI 可以探索的照片已经实现到3D场景的构成。首先使用类似的Stable 像Diffusion这样的AI模型生成图像,然后通过点云来保证空间的准确性(即用大量的3D坐标点来表示物体表面的数据结构,就像用无数的点来描绘空间的形状一样)。Diffusion系统 在创建新的视角图像时,模型会参照这些点云投影作为指导,确保产生的内容符合3D几何规律。
产生的2D图像随后通过景深估计(预测图像中物体距离的技术)转换为新的3D点,然后利用高斯透射技术将这些分散的点转化为持续平滑的3D场景(一种通过在空间中分布颜色和透明度的小球来实现真实的3D渲染的方法)。整个过程就像用AI“画”3D空间,但每一笔都受到严格的几何限制,确保最终产生的虚拟世界既真实又自然,可以自由探索。

但是以当时的技术,很难生成360度的全场景,3D的景倍感也很有限。但是这个技术路径很可能是World。 实现Labs的基础。

而Ben 2024年5月,Poole提到了Deepmind CAT3D的发布,其核心是一个“两步走”的过程 - 先使用条件扩散模型(类似Stable) Diffusion)通过输入图片生成多个不同视角的场景,然后使用NeRF(神经辐射场),一种神经网络技术,将2D图像转换为3D场景),将这些角度整合成一个连续的3D空间。就像AI首先从不同的角度“想象”场景会是什么样子,然后把这些“想象”拼接成一个可以自由探索的3D世界。这就像AI首先从不同的角度“想象”场景会是什么样子,然后把这些“想象”拼接成一个可以自由探索的3D世界。关键的突破是,他们把原本需要大量真实照片的NeRF技术改造成了一个只需要几张甚至一张照片就可以工作的系统,响应速度惊人,只需要一分钟。

World Labs更像是两者的结合状态,既可以延伸生成场景,又可以使场景中的3D物体更加立体多角度。
3 没有重建物理世界,但将来也许可以
当然,最初的结果仍然显示在目前。在每个人的试用中,自由移动是有边界的。这可能是因为3D模型不是即时渲染,很难保证大规模镜头运动后其他部分的形成。

另外,世界是静止的。虽然可以用特效调整,但是需要其他工具来生成人物这样的移动内容。这是一个可以探索的世界,但你能做的探索可能只是徘徊。
至于物理世界的互动,除了我们现在可以看到的,从展示视频中存在的物理反弹和3D轮廓的波浪图案来看,没有其他痕迹。这只能说明,World 在Labs创造的世界里,最多有3D体积的构建和基本反馈。很难说它“模拟了物理世界”。
不过,这可能只是World。 第一步是Labs和李飞飞的智能野心。李飞飞自己在5月份的讲座中提到:“如果我们想让AI超越现在的能力,我们不仅想看到和说话的AI,还想要行动的AI。最新的空间智能里程碑是教计算机观察、学习、行动,学习观察和行动更好。"让这个静止的世界动起来,才是空间智能心所向往的。
他们还在博客上表示,他们正在努力提高产生世界规模和细节的质量,探索更多的互动技术。在不久的将来,任何人都可能通过简单的操作创造自己的3D世界,并与之深入互动。
这让人想起博尔赫斯的图书馆,但这一次,它不是一本无限的书,而是一个无限的空间。在AI技术的魔法加持下,每张照片都可能成为通往独特数字领地的入口。这大概就是技术对我们的承诺:真正的访问,而不是简单的观看;不是被动的欣赏,而是主动的探索。
所以,你们准备好钻进AI世界的兔子洞了吗?
本文来自微信微信官方账号“腾讯科技”,作者:郝博阳,编辑:郑可君,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com